Review — HRNetV2, HRNetV2p: Deep High-Resolution Representation Learning for Visual Recognition
HRNetV2, HRNetV2p, Improves HRNetV1
Deep High-Resolution Representation Learning for Visual Recognition,
HRNetV2, HRNetV2p, by Microsoft Research, University of Science and Technology of China, Huazhong University of Science and Technology, Peking University, South China University of Technology, Griffith University, and Microsoft, Redmond
2021 TPAMI, Over 1900 Citations (Sik-Ho Tsang @ Medium)
High-Resolution Representations for Labeling Pixels and Regions,
2019 arXiv, Over 600 CitationsHuman Pose Estimation
2014 … 2017 [G-RMI] [CMUPose & OpenPose] [Mask R-CNN] 2018 [PersonLab]
Image Classification: 1989 … 2023 [Vision Permutator (ViP)]
Object Detection: 2014 … 2023 [YOLOv7]
Semantic Segmentation: 2014 … 2022 [PVTv2] [YOLACT++]
==== My Other Paper Readings Are Also Over Here ====
- High-Resolution Network (HRNet), maintains high-resolution representations through the whole process. There are two key characteristics: (i) Connect the high-to-low resolution convolution streams in parallel and (ii) repeatedly exchange the information across resolutions.
- HRNet supports wide range of applications, including human pose estimation, semantic segmentation, and object detection.
- Authors also have a 2019 arXiv paper: High-Resolution Representations for Labeling Pixels and Regions, with over 600 Citations. In this paper, they also cover ImageNet classification results by modifying HRNet
Outline
- HRNet
- Human Pose Estimation Results
- Semantic Segmentation Results
- Object Detection Results
- Image Classification Results
1. HRNet
- (Please feel free to read HRNetV1 first before reading this article.)
1.1. Backbone

As mentioned, the HRNet backbone (i) connects the high-to-low resolution convolution streams in parallel and (ii) repeatedly exchanges the information across resolutions.

To exchange the information across resolution, fusion modules are designed as above.
1.2. Representation Head

(a) HRNetV1: The output is the representation only from the high-resolution stream. Other three representations are ignored.
(b) HRNetV2: Low-resolution representations are rescaled through bilinear upsampling without changing the number of channels to the high resolution, and the four representations are concatenated, followed by a 1×1 convolution to mix the four representations.
(c) HRNetV2p: Multi-level representations are constructed by downsampling the high-resolution representation output from HRNetV2 to multiple levels.
- In this paper, HRNetV1 is used for human pose estimation, HRNetV2 is used for semantic segmentation, and HRNetV2p is used for object detection.



3. Semantic Segmentation Results


- HRNetV2 is used and the resulting 15C-dimensional representation at each position is passed to a linear classifier with the softmax loss to predict the segmentation maps.
In Table 3, HRNetV2-W40 (40 indicates the width of the high-resolution convolution), with similar model size to DeepLabv3+ and much lower computation complexity, gets better performance: 4.7 points gain over UNet++, 1.7 points gain over DeepLabv3 and about 0.5 points gain over PSPNet, DeepLabv3+.
HRNetV2-W48, with similar model size to PSPNet and much lower computation complexity, achieves much significant improvement: 5.6 points gain over UNet++, 2.6 points gain over DeepLabv3 and about 1.4 points gain over PSPNet and DeepLabv3+.
4. Object Detection Results


In the Faster R-CNN framework, the proposed networks perform better than ResNet with similar parameter and computation complexity: HRNetV2p-W32 vs. ResNet-101-FPN, HRNetV2p-W40 vs. ResNet-152-FPN, HRNetV2p-W48 vs. X-101-64×4d-FPN.
In the Cascade R-CNN and CenterNet frameworks, HRNet also performs better.
In the Cascade Mask R-CNN and Hybrid Task Cascade frameworks, HRNet gets the overall better performance.
5. Image Classification Results (2019 arXiv)

- After obtaining multiple resolution using HRNet backbone, the above head is used for ImageNet classification.
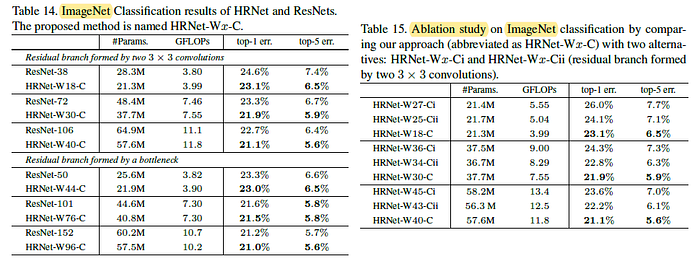
In Table 14, using HRNet as backbone is better than ResNet one. In Table 15, the proposed manner is superior to the two alternatives.
