Review: Image Transformer
Image Generation and Super Resolution Using Transformer

In this story, Image Transformer, by Google Brain, University of California, and Google AI, is briefly reviewed. In this paper:
- Self-Attention Transformer is used for image generation.
- By restricting the self-attention mechanism to attend to local neighborhoods, the size of images the model can process is significantly increased.
This is a paper in 2018 ICLR with over 600 citations. (Sik-Ho Tsang @ Medium)
Outline
- Image Transformer
- Local Self-Attention
- Experimental Results
1. Image Transformer
- For image-conditioned generation, as in our super-resolution models, we use an encoder-decoder architecture.
- The encoder generates a contextualized, per-pixel-channel representation of the source image.
- The decoder autoregressively generates an output image of pixel intensities, one channel per pixel at each time step.
- For unconditional and class-conditional generation, the Image Transformer is employed in a decoder-only configuration.
- (Please feel free to read Transformer if interested.)
1.1. One Layer of Image Transformer


- A slice of one layer of the Image Transformer, recomputing the representation q0 of a single channel of one pixel q by attending to a memory of previously generated pixels m1, m2, … .
- After performing local self-attention, a two-layer position-wise feed-forward neural network is applied with the same parameters for all positions in a given layer.
- Self-attention and the feed-forward networks are followed by dropout and bypassed by a residual connection with subsequent layer normalization.
- The position encodings pq, p1, … are added only in the first layer.
2. Local Self-Attention
- There are two settings for Image Transformer:

2.1. 1D Local Attention
- The input tensor with positional encodings is flattened in raster-scan order.
- For each query block, the memory block M is built from the same positions as Q and an additional lm positions corresponding to pixels that have been generated before, which can result in overlapping memory blocks.
2.2. 2D Local Attention
- The input tensor with positional encodings is partitioned into rectangular query blocks contiguous in the original image space.
- The image is generated one query block after another, ordering the blocks in raster-scan order.
3. Experimental Results
3.1. Image Generation


- Unlike GAN, image generation is performed pixel by pixel which has the log likelihoods in logit space, bits per dimension can be measured.
- Left: Images on the left are from a model that achieves 3.03 bits/dim on the test set.
- Right: Images on the right are from the proposed best non-averaged model with 2.99 bits/dim.
- Both models are able to generate convincing cars, trucks, and ships. Generated horses, planes, and birds also look reasonable.
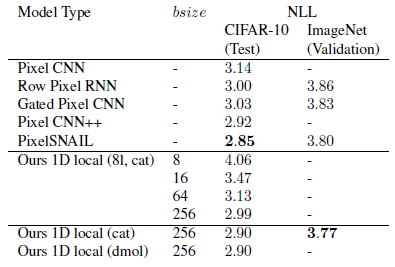
- The Image Transformer outperforms all models and matches Pixel-CNN++, achieving a new state-of-the-art on ImageNet. Increasing memory block size (bsize) significantly improves performance.
3.2. Super Resolution

3.3. Super Resolution on CelebA


- τ is to tempered softmax, proposed by Dahl, 2017.
- An 8×8 pixel image is enlarged four-fold to 32×32.
- 35% to 36% of humans are fooled, which is significantly better than the previous state of the art.
This is a paper to utilize Transformer proposed in Attention is All You Need for image generation and image super resolution.
Reference
[2018 ICML] [Image Transformer]
Image Transformer
Single Image Super Resolution (SISR)
2014–2016: [SRCNN]
2016: [FSRCNN] [VDSR] [ESPCN] [RED-Net] [DRCN]
2017: [DnCNN] [DRRN] [LapSRN & MS-LapSRN] [MemNet] [IRCNN] [WDRN / WavResNet] [SRDenseNet] [SRGAN & SRResNet] [SelNet] [CNF] [BT-SRN] [EDSR & MDSR] [EnhanceNet]
2018: [MWCNN] [MDesNet] [RDN] [SRMD & SRMDNF] [DBPN & D-DBPN] [RCAN] [ESRGAN] [CARN] [IDN] [ZSSR] [MSRN] [Image Transformer]
2019: [SR+STN] [IDBP-CNN-IA] [SRFBN] [OISR]
2020: [PRLSR] [CSFN & CSFN-M]
