Review: Language Modeling with Gated Convolutional Networks (GCNN/GLU)
Gated Convolutional Networks (GCNN) Using Gated Linear Unit (GLU)
In this story, Language Modeling with Gated Convolutional Networks, (GCNN/GLU), by Facebook AI Research, is briefly reviewed. In this paper:
- A finite context approach through stacked convolutions is proposed, which can be more efficient since they allow parallelization over sequential tokens.
- A novel simplified gating mechanism, Gated Linear Unit (GLU), is proposed.
This is a paper in 2016 arXiv with over 1300 citations. (Sik-Ho Tsang @ Medium)
Outline
- Gated Convolutional Networks (GCNN): Network Architecture
- Experimental Results
1. Gated Convolutional Networks (GCNN): Network Architecture

- The above architecture will be mentioned part by part from input to output as below.
1.1. Motivations of Using CNN over RNN
- Recurrent neural network (RNN) always needs to wait for previous state, which is difficult for parallelization.
- The proposed approach use CNN, which convolves the inputs with a function f to obtain H=f*w and therefore has no temporal dependencies, so it is easier to parallelize over the individual words of a sentence.
1.2. Word Embedding as Input

- Words are represented by a vector embedding stored in a lookup table D^(|V|×e) where |V| is the number of words in the vocabulary and e is the embedding size. The input to the model is a sequence of words w0, .., wN which are represented by word embeddings E=[Dw0, …, DwN].
1.3. Gated Linear Unit (GLU)

- The hidden layers h0, …, hL are computed as:

- where σ is the sigmoid function and ⨂ is the element-wise product between matrices.
- When convolving inputs, care is needed that hi does not contain information from future words. Zero-padding is used to pad the input to handle this problem.
The output of each layer is a linear projection X*W+b modulated by the gates (X*V+c), which is called Gated Linear Units (GLU).
1.4. Stacking GLU

- Stacking multiple layers on top of the input E gives a representation of the context for each word H=hL○…○h0(E).
- The convolution and the gated linear unit in a pre-activation residual block (Pre-Activation ResNet).
- The blocks have a bottleneck structure for computational efficiency and each block has up to 5 layers.
- (Please feel free to read Pre-Activation ResNet if interested.)
1.5. Softmax

- The simplest choice to obtain model predictions is to use a softmax layer, but it is computationally inefficient for large vocabularies.
- Adaptive softmax which assigns higher capacity to very frequent words and lower capacity to rare words (Grave et al., 2016a), is used.
1.6. GCNN Variants
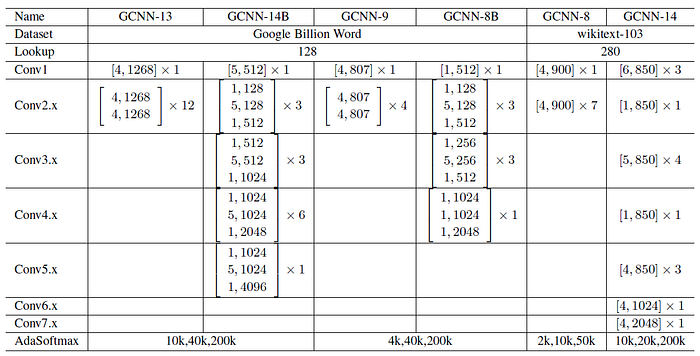
- Gradient clipping is used where large gradient is clipped.
- Weight normalization is used where weights are normalized in some layers.
- Both techniques are used to speed up the convergence.
2. Experimental Results
2.1. Google Billion Word Dataset

- GCNN outperforms the comparable LSTM results on Google billion words.
GCNN reaches 38.1 test perplexity while the comparable LSTM has 39.8 perplexity.
2.2. WikiText-103 Dataset
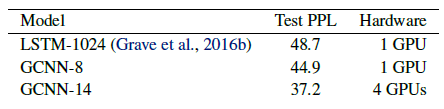
- An input sequence is an entire Wikipedia article instead of an individual sentence — increasing the average length to 4000 words.
GCNN outperforms LSTMs on this problem as well.
2.3. Other Studies

The adaptive softmax approximation greatly reduces the number of operations required to reach a given perplexity.
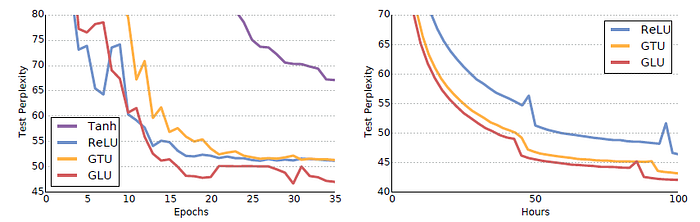
Models with gated linear units (GLU) converge faster and to a lower perplexity.
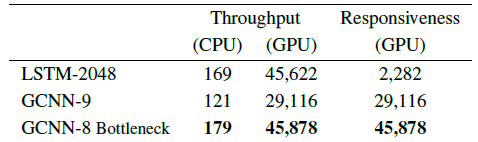
- Throughput can be maximized by processing many sentences in parallel to amortize sequential operations.
- In contrast, responsiveness is the speed of processing the input sequentially, one token at a time.
The GCNN with bottlenecks improves the responsiveness by 20 times while maintaining high throughput.
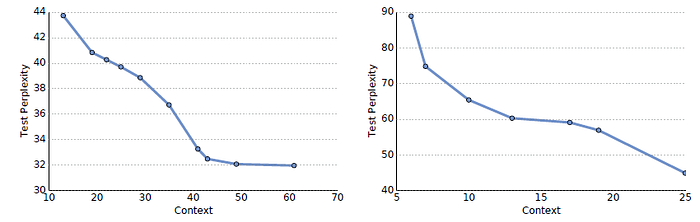
- Models with bigger context achieve better results but the results start diminishing quickly after a context of 20.
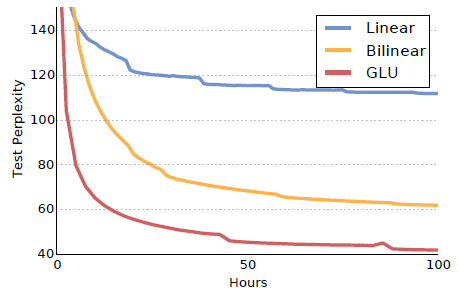
GLUs perform best.

Weight normalization and gradient clipping significantly speed up convergence.
Reference
[2016 arXiv] [GCNN/GLU]
Language Modeling with Gated Convolutional Networks
Natural Language Processing (NLP)
Sequence Model: 2014 [GRU] [Doc2Vec]
Language Model: 2007 [Bengio TNN’07] 2013 [Word2Vec] [NCE] [Negative Sampling] 2016 [GCNN/GLU]
Sentence Embedding: 2015 [Skip-Thought]
Machine Translation: 2014 [Seq2Seq] [RNN Encoder-Decoder] 2015 [Attention Decoder/RNNSearch] 2016 [GNMT] [ByteNet] [Deep-ED & Deep-Att]
Image Captioning: 2015 [m-RNN] [R-CNN+BRNN] [Show and Tell/NIC] [Show, Attend and Tell]
