Review — Show, Attend and Tell: Neural Image Caption Generation
With Attention, Show, Attend and Tell Outperforms Show and Tell

In this story, Show, Attend and Tell: Neural Image Caption Generation with Visual Attention, (Show, Attend and Tell), by Université de Montréal, University of Toronto, is briefly reviewed. This is a paper from Prof. Bengio’s group. In this paper:
- An attention based model is introduced that automatically learns to describe the content of images.
This is a paper in 2015 ICML with over 7900 citations. (Sik-Ho Tsang @ Medium)
Outline
- CNN Encoder
- Attention Decoder
- Experimental Results

1. CNN Encoder
- The model takes a single raw image and generates a caption y encoded as a sequence of 1-of-K encoded words.

- where K is the size of the vocabulary and C is the length of the caption.
- A convolutional neural network (CNN) is used to extract a set of feature vectors which we refer to as annotation vectors.
- The extractor produces L vectors, each of which is a D-dimensional representation corresponding to a part of the image.

Features are extracted from a lower convolutional layer. This allows the decoder to selectively focus on certain parts of an image by weighting a subset of all the feature vectors.
- e.g.: the 14×14×512 feature map of the fourth convolutional layer before max pooling in ImageNet-Pretrained VGGNet is used.
- The decoder operates on the flattened 196×512 (i.e L×D) encoding.
- Or it can be GoogLeNet in the experiments.
2. Attention Decoder
2.1. Attention Decoder

(For this part, the concept of attention decoder is very similar to the Attention Decoder for Machine Translation. Please feel free to read it.)
- A long short-term memory (LSTM) network is used that produces a caption by generating one word at every time step conditioned on a context vector, the previous hidden state and the previously generated words.
- The context vector ^zt is a dynamic representation of the relevant part of the image input at time t.
- A mechanism that computes ^zt from the annotation vectors ai, i=1, …, L corresponding to the features extracted at different image locations.
For each location i, the mechanism generates a positive weight i which can be interpreted either as the probability that location i is the right place to focus for producing the next word (stochastic attention mechanism), or as the relative importance to give to location i in blending the ai’s together (deterministic attention mechanism).
- The weight i of each annotation vector ai is computed by an attention model fatt for which a multilayer perceptron is used which conditioned on the previous hidden state ht-1.
- To emphasize, the hidden state varies as the output RNN advances in its output sequence: “where” the network looks next depends on the sequence of words that has already been generated.

- Once the weights (which sum to one) are computed, i.e. softmax, the context vector ^zt is computed by:
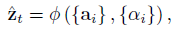
- where Φ is a function that returns a single vector given the set of annotation vectors and their corresponding weights. This function is mentioned in the next sub-section.

- (I think this video https://www.youtube.com/watch?v=y1S3Ri7myMg provides a good and layman way about the soft and hard attentions.)
2.2. Stochastic “Hard” Attention & Deterministic “Soft” Attention
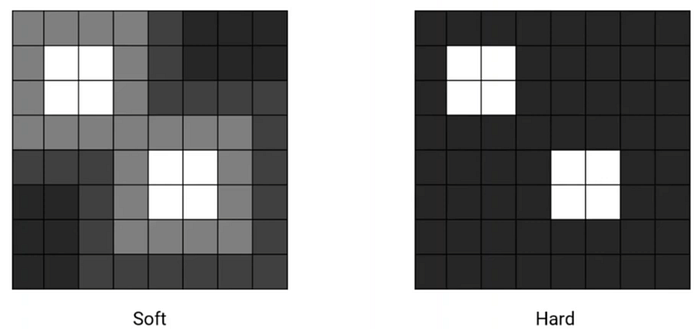
- The hard attention focuses only on the part it wants and ignore other parts while the soft attention is smooth.

- In soft attention, different weights based on the image are used.

- In hard attention, only the most important part is used.

- (For equations that deriving the attentions, they are sophisticated. Please feel free to read the paper.)
3. Experimental Results

- Each image in the Flickr8k/30k dataset have 5 reference captions.
- For COCO dataset, captions in excess of 5 are discarded.
- A fixed vocabulary size of 10,000 is used.
Show, Attend & Tell obtains the SOTA performance on the Flickr8k, Flickr30k and MS COCO, e.g. outperforms Show and Tell/NIC.

The model learns alignments that agree very strongly with human intuition.

- But the proposed model also makes mistakes, which means there is room for improvement.
Reference
[2015 ICML] [Show, Attend and Tell]
Show, Attend and Tell: Neural Image Caption Generation with Visual Attention
Natural Language Processing (NLP)
Sequence Model: 2014 [GRU] [Doc2Vec]
Language Model: 2007 [Bengio TNN’07] 2013 [Word2Vec] [NCE] [Negative Sampling]
Sentence Embedding: 2015 [Skip-Thought]
Machine Translation: 2014 [Seq2Seq] [RNN Encoder-Decoder] 2015 [Attention Decoder/RNNSearch] 2016 [GNMT] [ByteNet]
Image Captioning: 2015 [m-RNN] [R-CNN+BRNN] [Show and Tell/NIC] [Show, Attend and Tell]
