Review — RMMLP: RollingMLP and Matrix Decomposition for Skin Lesion Segmentation
RMMLP: MEEMLP+DMMLP+DSFF

RMMLP: RollingMLP and Matrix Decomposition for Skin Lesion Segmentation,
RMMLP, by Jiangnan University, and Wuxi People’s Hospital,
2023 J. BSPC (Sik-Ho Tsang @ Medium)Biomedical Image Segmentation
2015 … 2022 [UNETR] [Half-UNet] [BUSIS] [RCA-IUNet] [Swin-Unet] [DS-TransUNet] [UNeXt] 2023 [DCSAU-Net]
- An MLP-based model, RMMLP, is proposed using matrix decomposition and rolling tensors for skin lesion segmentation.
- Specifically, the correlation matrix is dynamically calculated according to the size of the input image and use it as the weight to guide the segmentation.
- The way of rolling tensors can fully mix the feature information and sequentially extract the information under different receptive fields.
- A two-layer decoding structure is employed using matrix decomposition to fuse the feature extracted in the parallel MLP encoders.
Outline
- RMMLP
- Results
1. RMMLP
1.1. Overall Architecture

- RMMLP uses four ResNet Blocks as encoders to preliminarily extract four features of different scales 𝐹𝑖, 𝑖 ∈ {1, 2, 3, 4}.
- 𝐹𝑖 is sent into three Multiscale Edge Extraction MLPs (MEEMLPs) and gets edge segmentation results at three different scales.
- High-level feature 𝐹4 has abundant semantic information, so it can achieve the skin lesion information after passing through Dynamic-Matrices MLP (DMMLP).
- For local context in different scales, we use Double Scale Feature Fusion (DSFF) to perform fusion decoding in order to obtain the prediction result at two scales.
- Deep supervision is also used here. £edge is the boundary loss.
1.2. Multi-scale Edge Extraction MLP (MEEMLP)

- The feature maps generated by ResNet encoder are passed through three convolution layers with different convolution kernels, then were sent to Rolling-MLP.
- After that, the outputs of the three branches are fused and passed through channel attention and spatial attention as in CBAM after the residual connection.

- Inspired by UNeXt, rolling method is of great significance for fusing semantic information.
- Input is first projected into non-overlapping tokens and layer normalization is performed.
- Before rolling, the feature map is divided into S pieces (S is a hyperparameter) in the channel dimension. For each pieces, constant 0 is padded and the map is rolled in both dimensions of height and width.
- Unlike UNeXt, all the information of the enlarged feature map is fused.
- After an MLP layer, the semantic information is aggregated and the map is reshaped into the previous size.
1.3. Dynamic-Matrices MLP (DMMLP)
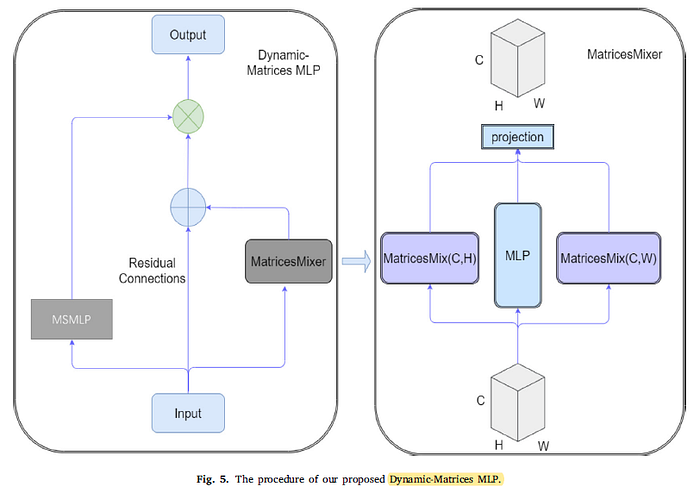
- A dynamic matrix M is generated given a set of input 𝑥 of size 𝐻×𝑊×𝐶 in MatricesMixer module.
- With matrix M obtained, the mixed output 𝑌 = 𝑀𝑥 is calculated.
- Then, after residual concatenation with the original input, Y can be multiplied with the output generated by MEEMLP:
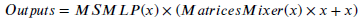
DMMLP is only used in the highest level since it has a larger receptive field. Also, the number of parameters at smaller resolution will be significantly lower than that of other layer features.
- A novel information-mixing method based on MLP and Dynamic Matrices. For the input 𝑋, X is flattened into a vector and the mixing matrices are generated.
- For MatricesMixer, the intuition here is similar to DynaMixer [38]. The result obtained from the MLP whose input is still the original feature map. They are added together and then averaged (DC) to obtain the weights.
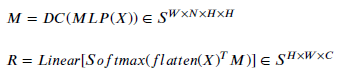
- where M is a dynamically generated weights matrix, 𝑁 is a hyperparameter and R is the results of mixing channel information with height and width respectively.
- Finally, the weights will be multiplied by the three previously calculated values and mapped to get the final result.
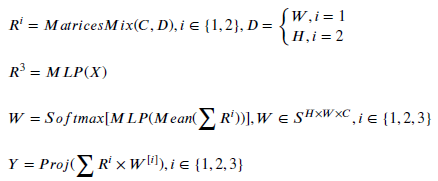
1.4. Decoder Using Double Scale Feature Fusion (DSFF)
- A modified lightweight Hamburger [42] is used.
- Firstly, Double Scale Feature Fusion (DSFF) is used to aggregate upper and lower feature maps of two different scales. In DSFF, the convolution blocks consist of a bilinear interpolation layer to upsample. The two feature maps are concatenated and sent to two consecutive residual blocks.
- Deep supervision is performed on all three outputs.
- Boundary-Burger Fusion also uses matrix decomposition. Matrix decomposition models used to be used in image denoising [44], image repairing [45] and so on.
- After combining all the inputs, they are reshaped as X. Then, generating a matrix 𝑊1 randomly to work as weights. An outer product is performed on transposed X and 𝑊1 to get the coefficient 𝑃1 which is required later.
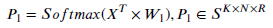
- Next, the following calculation formula is repeated for n times to reconstruct X:
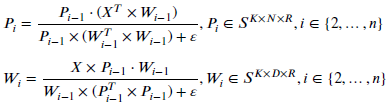
- After the matrix decomposition, an output Xfinal is obtained with the same size:
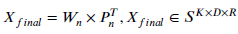
1.5. Loss Function
- Binary cross-entorpy loss is used.
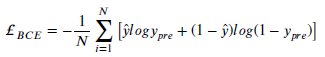
- Dice loss is also used.
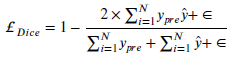
- The above losses are combined:
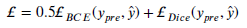
- Finally, the total loss, with weak supercision using 3 edge losses:

2. Results
2.1. ISIC2018

RMMLP achieves 0.9198 in Dice and 0.8540 in IoU. It is obvious that the proposed model achieves the highest scores with a relatively small amount of parameters which shows that Transformer is not the optimal solution.
2.2. ISIC2016+PH2
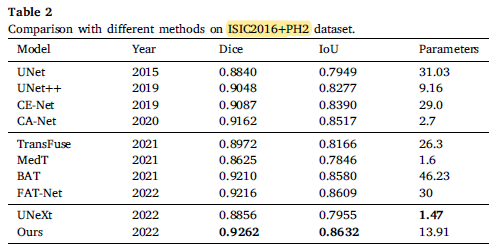
After training on ISIC2016, the Dice coefficient of the test on PH2 is 0.51% higher than that of FAT-Net, proving that the combination of MLP and CNN is also competitive.
2.3. ISIC2017
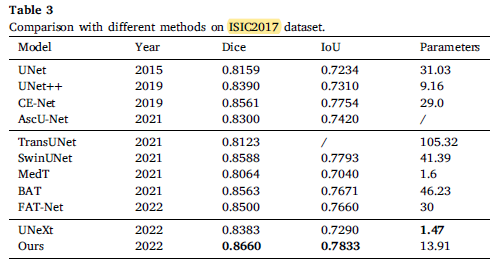
The proposed model extracts global features on images of different scales, and exceeded Swin-Unet by 0.72% and 0.4% on dice coefficient and IoU, respectively.
2.4. Ablation Study
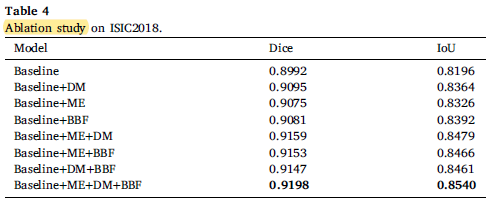
After adding all modules, the Dice coefficient reaches the highest 0.9198 and IoU achieved 0.8540 which confirms the proposed three modules are effective.
2.5. Visualizations

The proposed method obtains better segmentation results.
