Brief Review — SiLU: Sigmoid-weighted Linear Unit
Activation Functions Used in YOLOv7, SiLU & dSiLU
3 min readJul 20, 2022
Sigmoid-weighted linear units for neural network function approximation in reinforcement learning
SiLU, by ATR Computational Neuroscience Laboratories, and Okinawa Institute of Science and Technology Graduate University
2018 JNN, Over 400 Citations (Sik-Ho Tsang @ Medium)
Activation Function, Deep Reinforcement Learning, DQN, Object Detection
- Two activation functions are proposed for neural network function approximation in reinforcement learning: the sigmoid-weighted linear unit (SiLU) and its derivative function (dSiLU).
Outline
- Sigmoid-weighted Linear Unit (SiLU)
- Derivative of SiLU (dSiLU)
- Results
1. Sigmoid-weighted Linear Unit (SiLU)

- SiLU is proposed as an activation function for neural network function approximation in reinforcement learning.
- The activation ak of the kth SiLU for input zk is computed by the sigmoid function multiplied by its input:

- where sigmoid function is:

- For zk-values of large magnitude, the activation of the SiLU is approximately equal to the activation of the ReLU.
- Unlike the ReLU (and other commonly used activation units such as sigmoid and tanh units), the activation of the SiLU is not monotonically increasing.
- Instead, it has a global minimum value of approximately −0.28 for zk ≈ −1.28. An attractive feature of the SiLU is that it has a self-stabilizing property.
- The global minimum, where the derivative is zero, functions as a ‘‘soft floor’’ on the weights that serves as an implicit regularizer that inhibits the learning of weights of large magnitudes.
2. Derivative of SiLU (dSiLU)

- The derivative function of the SiLU (i.e., the derivative of the contribution from a hidden node to the output in an EE-RBM) looks like a steeper and ‘‘overshooting’’ version of the sigmoid function:

- It is proposed as a competitive alternative to the sigmoid function.
- The dSiLU has a maximum value of approximately 1.1 and a minimum value of approximately −0.1 for zk ≈ ±2.4, i.e., the solutions to the equation zk=−log((zk−2)/(zk+2)).
3. Results

- Better score is achieved by SiLU and dSiLU.
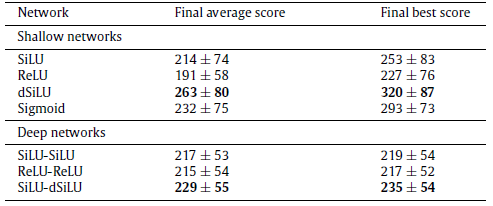
- Using SiLU and dSiLU obtains better performance.
SiLU is later used by many papers from other fields such as object detection. YOLOv7 uses SiLU, Mish used in Scaled YOLOv4 and YOLOv4 is abandoned.
(Start from now, for some papers, I may just briefly write a very short story.)
