Review — Mish: A Self Regularized Non-Monotonic Activation Function

Mish: A Self Regularized Non-Monotonic Activation Function
Mish, by Landskape, KIIT, Bhubaneswar
2020 BMVC, Over 500 Citations (Sik-Ho Tsang @ Medium)
Image Classification, Object Detection, Activation Function
- Mish, a novel self-regularized non-monotonic activation function, is proposed, which can be mathematically defined as:
- f(x) = x tanh(softplus(x))
Outline
- Conventional Activation Functions
- Mish
- Experimental Results
1. Conventional Activation Functions
1.1. Sigmoid and Tanh
- Sigmoid and Tanh activation functions were extensively used, which subsequently became ineffective in deep neural networks, due to zero gradients at both tails.
1.2. ReLU
- A less probability inspired, unsaturated piece-wise linear activation known as Rectified Linear Unit (ReLU) became more relevant and showed better generalization and improved speed of convergence compared to Sigmoid and Tanh.
- But ReLU has a popularly known problem as Dying ReLU, which is experienced through a gradient information loss caused by collapsing the negative inputs to zero.
1.3. Leaky ReLU, ELU, SELU, Swish
- Over the years, many activation functions, such as Leaky ReLU, ELU, SELU, Swish, have been proposed which improve performance and address the shortcomings of ReLU.
- The smooth, continuous profile of Swish proved essential in better information propagation as compared to ReLU.
In this paper, inspired by the self gating property of Swish, Mish is proposed.
2. Mish

- While Swish is found by Neural Architecture Search (NAS), the design of Mish, while influenced by the work performed by Swish, was found by systematic analysis and experimentation over the characteristics that made Swish so effective.
- (a): arctan(x)softplus(x), tanh(x)softplus(x), x log(1+arctan(e^x)) and x log(1+tanh(e^x)), where softplus(x) = ln(1+e^x), are studied.
- (b): Mish performed better than the other activation functions.
- It is found that x log(1+tanh(e^x)) performed on par with Mish,its training is often unstable.
Mish is a smooth, continuous, self regularized, non-monotonic activation function:

- Mish is bounded below at around 0.31, and unbound above.
Due to the preservation of a small amount of negative information, Mish eliminated by design the preconditions necessary for the Dying ReLU phenomenon.
- Being unbounded above, Mish avoids saturation, which generally causes training to slow down.
- Also, unlike ReLU, Mish is continuously differentiable, a property that is preferable because it avoids singularities.
3. Experimental Results
3.1. Ablation Study on CIFAR-10 and MNIST

- (a): Post fifteen layers, there was a sharp decrease in accuracy for both Swish and ReLU, while Mish maintained a significantly higher accuracy in large models where optimization becomes difficult.
- (b): Consistently better loss is observed with varying intensity of Input Gaussian Noise with Mish as compared to ReLU and Swish.
- (c): Consistent positive difference is observed in the performance of Mish compared to Swish while using different initializers.
3.2. CIFAR-10
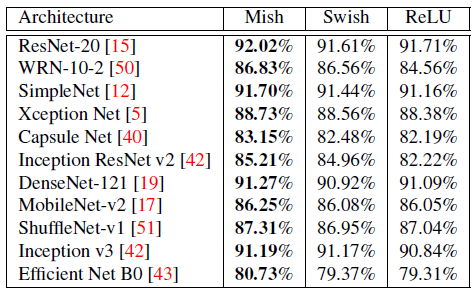
Mish activation function consistently outperforms ReLU and Swish activation functions across all the standard architectures used in the experiment, with often providing 1% to 3% performance improvement over the baseline ReLU enabled network architectures.
3.3. ImageNet
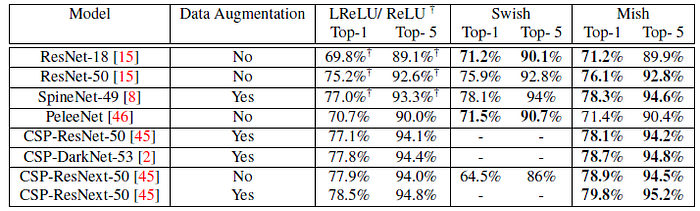
- Data Augmentation indicates the use of CutMix, Mosaic in YOLOv4, and Label Smoothing in Inception-v3.
Mish consistently outperforms the default Leaky ReLU/ ReLU on all the four network architectures with a 1% increase in Top-1 Accuracy over Leaky ReLU in CSP-ResNet-50 architecture although Swish provides marginally stronger result in PeleeNet as compared to Mish.
3.4. MS-COCO Object Detection

Simply replacing ReLU with Mish in the backbone improved the mAP@0.5 for CSP-DarkNet-53 and CSP-DarkNet-53+PANet+SPP by 0.4%.
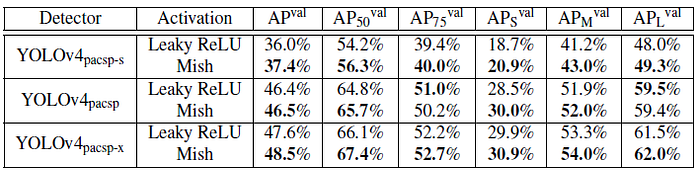
Using Mish, a consistent 0.9% to 2.1% improvement is observed in the AP50 val on test size of 736.
3.5. Time Complexity
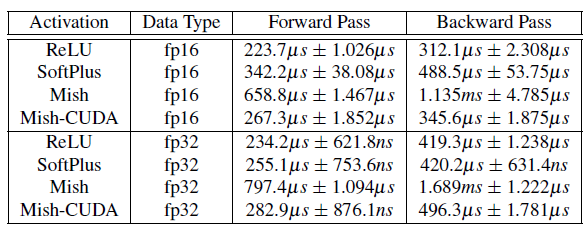
- In practical implementation, a threshold of 20 is enforced on Softplus, which makes the training more stable and prevents gradient overflow.
- All runs were performed on an NVIDIA GeForce RTX-2070 GPU using standard benchmarking practices over 100 runs.
The significant reduction in computational overhead of Mish by using the optimized version Mish-CUDA.
It is surprising that Mish outperforms Swish while they seems to be similar. And Mish is used in YOLOv4 and Scaled-YOLOv4.
Reference
[2020 BMVC] [Mish]
Mish: A Self Regularized Non-Monotonic Activation Function
Image Classification
1989–2019 … 2020: [Random Erasing (RE)] [SAOL] [AdderNet] [FixEfficientNet] [BiT] [RandAugment] [ImageNet-ReaL] [ciFAIR] [ResNeSt] [Batch Augment, BA] [Mish]
2021: [Learned Resizer] [Vision Transformer, ViT] [ResNet Strikes Back] [DeiT] [EfficientNetV2] [MLP-Mixer] [T2T-ViT] [Swin Transformer] [CaiT] [ResMLP] [ResNet-RS] [NFNet]
Object Detection
2014–2018 … 2019: [DCNv2] [Rethinking ImageNet Pre-training] [GRF-DSOD & GRF-SSD] [CenterNet] [Grid R-CNN] [NAS-FPN] [ASFF] [Bag of Freebies] [VoVNet/OSANet] [FCOS] [GIoU]
2020: [EfficientDet] [CSPNet] [YOLOv4] [SpineNet] [DETR] [Mish]
2021: [Scaled-YOLOv4]