Review — Scaled-YOLOv4: Scaling Cross Stage Partial Network
Outperforms EfficientDet, SpineNet, YOLOv4 & YOLOv3

In this story, Scaled-YOLOv4: Scaling Cross Stage Partial Network, (Scaled-YOLOv4), by Institute of Information Science Academia Sinica, is reviewed.
YOLOv4, which is based on CSPNet, has been proposed for object detection.
In this paper:
- First, YOLOv4 is re-designed to form YOLOv4-CSP.
- Then, A network scaling approach that modifies not only the depth, width, resolution, but also structure of the network, which finally forms Scaled-YOLOv4.
This is a paper in 2021 CVPR with over 50 citations. (Sik-Ho Tsang @ Medium) (In Scaled-YOLOv4, there are many prior arts used, e.g. CSPNet, OSANet, YOLOv4. It is better to know them before Scaled-YOLOv4.)
1. Principles of Model Scaling
- Some factors are considered when working on model scaling for object detection task. (If not interested, please skip to Section 2 directly.)
1.1. General Principle of Model Scaling

- ResNet, ResNeXt and DarkNet layers are investigated. (It is also assumed that ResNet, ResNeXt, and DarkNet which is in YOLO series, are already read.)
- Let the scaling factors that can be used to adjust the image size, the number of layers, and the number of channels be α, β, and γ, respectively.
- For the k-layer CNNs with b base layer channels, when these scaling factors vary, the corresponding changes on FLOPs are shown as above table.
The scaling size, depth and width cause increase in the computation cost. They respectively show square, linear, and square increase.

- When CSPNet is applied to ResNet, ResNeXt, and Darknet and observe the changes in the amount of computations, in the above table.
- In brief, CSPNet splits the input into two paths. One performs convolutions. One performs no convolution. They are fused at the output.
- CSPNet can effectively reduce the amount of computations (FLOPs) on ResNet, ResNeXt, and Darknet by 23.5%, 46.7%, and 50.0%, respectively.
- (If interested, please feel free to visit CSPNet.)
Therefore, CSP-ized models are used as the best model for performing model scaling.
1.2. Scaling Tiny Models for Low-End Devices

- Memory bandwidth, memory access cost (MACs), and DRAM traffic should also be considered.
- Lightweight models are different from large models in that their parameter utilization efficiency must be higher.
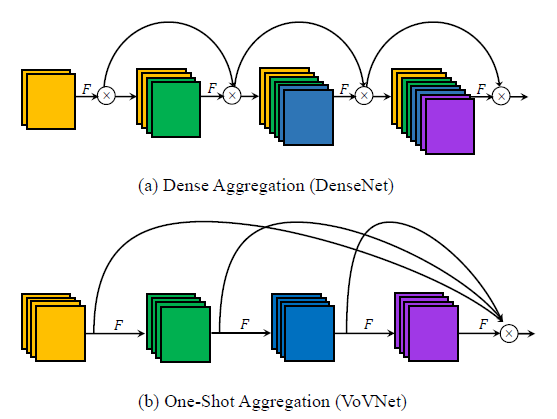
- The network with efficient parameter utilization is analyzed, such as the computation load of DenseNet and OSANet, where g means growth rate.
- The order of computation complexity of DenseNet is O(whgbk), and that of OSANet is O(max(whbg, whkg2)).
- (If interested, please feel free to visit DenseNet & VoVNet/OSANet.)
The tiny model is designed with the help of OSANet, which has a smaller computation complexity.
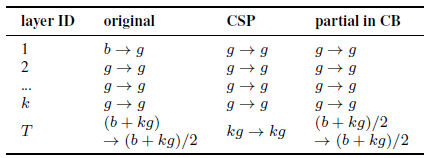
- A new concept of gradient truncation is performed between computational block of the CSPOSANet.
- This feature is to re-plan the b channels of the base layer and the kg channels generated by computational block, and split them into two paths with equal channel numbers, as shown above.
- When the number of channel is b+kg, these channels are split into 2 paths.
The CSPOSANet is designed to dynamically adjust the channel allocation.

- Minimize Convolutional Input/Output (CIO) is an indicator that can measure the status of DRAM IO.
When kg>b/2, the proposed CSPOSANet can obtain the best CIO.
1.3. Scaling Large Models for High-End GPUs
- We hope to improve the accuracy and maintain the real-time inference speed after scaling up the CNN model, the above factors should be considered.
- The biggest difference between image classification and object detection is that the former only needs to identify the category of the largest component in an image, while the latter needs to predict the position and size of each object in an image.
The ability to better predict the size of an object basically depends on the receptive field of the feature vector.

- It is apparent that width scaling can be independently operated.
- The compound of {size^input, #stage} turns out with the best impact.
Therefore, when performing scaling up, compound scaling is firstly performed on size^input, #stage, and then according to real-time requirements, scaling is further performed on depth and width respectively.
2. Scaled-YOLOv4: CSP-ized YOLOv4 / YOLOv4-CSP
2.1. Backbone
- The amount of computation of each CSPDarknet stage is whb²(9/4+3/4+5k/2).
- According to the previous section, CSPDarknet stage will have a better computational advantage over Darknet stage only when k>1 is satisfied.
- The number of residual layer owned by each stage in CSPDarknet53 is 1–2–8–8–4 respectively.
- In order to get a better speed/accuracy trade-off, the first CSP stage is converted into original Darknet residual layer.
2.2. Neck
- The PAN architecture in YOLOv4 is also CSP-ized as above.
- This new update effectively cuts down 40% of computation.
2.3. SPP
3. Scaled-YOLOv4: YOLOv4-tiny

- YOLOv4-tiny is designed for low-end GPU device.
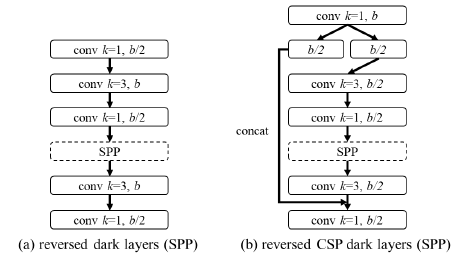
- The CSPOSANet with partial in computational block (PCB) architecture is used to form the backbone of YOLOv4.
- g=b=2 is set as the growth rate and make it grow to b/2+kg=2b at the end.
- Through calculation, k=3 is deduced, and its architecture is shown as above.
4. Scaled-YOLOv4: YOLOv4-large
- YOLOv4-large is designed for cloud GPU.
- A fully CSP-ized model YOLOv4-P5 is designed and can be scaled up to YOLOv4-P6 and YOLOv4-P7.
- Compound scaling on size^input, #stage is performed.
- The depth scale of each stage to 2^(d_si), and d_s to [1, 3, 15, 15, 7, 7, 7].
- The inference time is further used as constraint to perform additional width scaling.
- YOLOv4-P6 can reach real-time performance at 30 FPS video when the width scaling factor is equal to 1.
- YOLOv4-P7 can reach real-time performance at 16 FPS video when the width scaling factor is equal to 1.25.
5. Ablation Study
- MSCOCO 2017 object detection dataset is used.
- All models are trained from scratched.
5.1. Ablation Study on CSP-ized Model
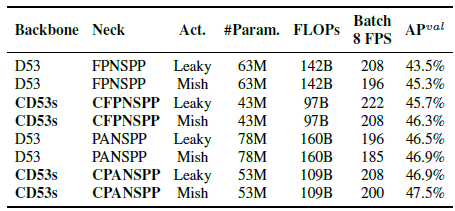
- Darknet53 (D53) is used as backbone and FPN with SPP (FPNSPP) and PAN with SPP (PANSPP) are chosen as necks to design ablation studies.
- LeakyReLU (Leaky) and Mish activation function are tried.
CSP-ized models have greatly reduced the amount of parameters and computations by 32%, and brought improvements in both Batch 8 throughput and AP.
Both CD53s-CFPNSPP-Mish, and CD53s-CPANSPP-Leaky have the same batch 8 throughput with D53-FPNSPP-Leaky, but they respectively have 1% and 1.6% AP improvement with lower computing resources.
Therefore, CD53s-CPANSPP-Mish is decided to used, as it results in the highest AP in the above table as the backbone of YOLOv4-CSP.
5.2. Ablation Study on YOLOv4-tiny
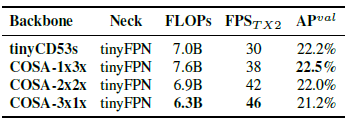
- The designed PCB technique can make the model more flexible, because such a design can be adjusted according to actual needs.
- The proposed COSA can get a higher AP.
Therefore, COSA-2x2x is finally chosen, which received the best speed/accuracy trade-off in the experiment as the YOLOv4-tiny architecture.
5.3. Ablation Study on YOLOv4-large
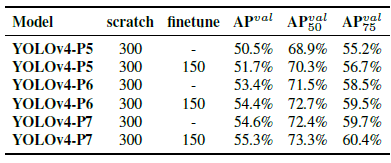
- For YOLOv4-large, 300 epochs are firstly executed and then followed by 150 epochs for fine-tuning using stronger data augmentation method.
AP is improved with further fine-tuning using stronger data augmentation method.
6. Scaled-YOLOv4 for Object Detection Results
6.1. Large-Model

As shown in the figure at the top of the story and also the table above, all scaled YOLOv4 models, including YOLOv4-CSP, YOLOv4-P5, YOLOv4-P6, YOLOv4-P7, are Pareto optimal on all indicators.
- When comparing YOLOv4-CSP with the same accuracy of EfficientDet-D3 (47.5% vs 47.5%), the inference speed is 1.9 times.
- When YOLOv4-P5 is compared with EfficientDet-D5 with the same accuracy (51.8% vs 51.5%), the inference speed is 2.9 times.
- The situation is similar to the comparisons between YOLOv4-P6 vs EfficientDet-D7 (54.5% vs 53.7%) and YOLOv4-P7 vs EfficientDet-D7x (55.5% vs 55.1%). In both cases, YOLOv4-P6 and YOLOv4-P7 are, respectively, 3.7 times and 2.5 times faster in terms of inference speed.
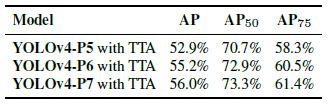
- With test-time augmentation (TTA), YOLOv4-P5, YOLOv4-P6, and YOLOv4-P7 gets 1.1%, 0.7%, and 0.5% higher AP, respectively.
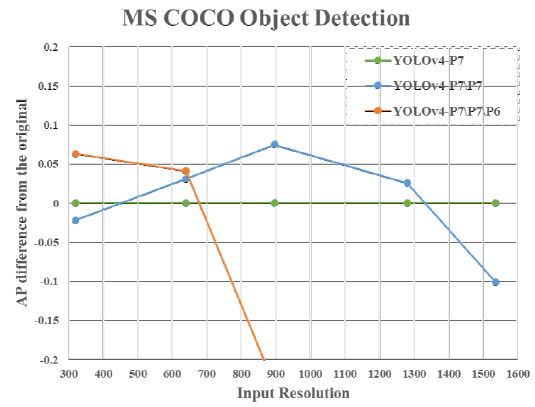
- FPN-like architecture is a naïve once-for-all model while YOLOv4 has some stages of top-down path and detection branch.
- YOLOv4-P7\P7 and YOLOv4-P7\P7\P6 represent the model which has removed {P7} and {P7, P6} stages from the trained YOLOv4-P7.
As shown above, YOLOv4-P7 has the best AP at high resolution, while YOLOv4-P7\P7 and YOLOv4-P7\P7\P6 have the best AP at middle and low resolution, respectively. This means that we can use subnets of FPN-like models to execute the object detection task well.
6.2. Tiny-Model
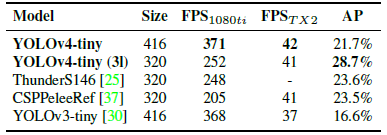
YOLOv4-tiny achieves the best performance in comparison with other tiny models.

- YOLOv4-tiny is put on different embedded GPUs for testing, including Xavier AGX, Xavier NX, Jetson TX2, Jetson NANO.
- If FP16 and batch size 4 are adopted to test Xavier AGX and Xavier NX, the frame rate can reach 380 FPS and 199 FPS respectively.
- In addition, if one uses TensorRT FP16 to run YOLOv4-tiny on general GPU RTX 2080ti, when the batch size respectively equals to 1 and 4, the respective frame rate can reach 773 FPS and 1774 FPS, which is extremely fast.
YOLOv4-tiny can achieve real-time performance no matter which device is used.
Reference
[2021 CVPR] [Scaled-YOLOv4]
Scaled-YOLOv4: Scaling Cross Stage Partial Network
Object Detection
2014-2017: …
2018: [YOLOv3] [Cascade R-CNN] [MegDet] [StairNet] [RefineDet] [CornerNet] [Pelee & PeleeNet]
2019: [DCNv2] [Rethinking ImageNet Pre-training] [GRF-DSOD & GRF-SSD] [CenterNet] [Grid R-CNN] [NAS-FPN] [ASFF] [Bag of Freebies] [VoVNet/OSANet]
2020: [EfficientDet] [CSPNet] [YOLOv4] [SpineNet]
2021: [Scaled-YOLOv4]
