Review — VisualBERT: A Simple and Performant Baseline for Vision and Language
A Joint Representation Model for Vision and Language
VisualBERT: A Simple and Performant Baseline for Vision and Language
VisualBERT, by University of California, Allen Institute for Artificial Intelligence, and Peking University
2019 arXiv, Over 500 Citations (Sik-Ho Tsang @ Medium)
Vision Language Model, VLM, Transformer, BERT
- VisualBERT, a simple and flexible framework, is proposed for modeling a broad range of vision-and-language tasks.
- VisualBERT consists of a stack of Transformer layers that implicitly align elements of an input text and regions in an associated input image with self-attention.
Outline
- VisualBERT
- Datasets & Variants
- Experimental Results
1. VisualBERT

1.1. Visual Embeddings
- In addition to all the components of BERT, a set of visual embeddings, F, are introduced to model an image. Each f ∈ F corresponds to a bounding region in the image, derived from an object detector.
- Each embedding in F is computed by summing three embeddings:
- fo, a visual feature representation of the bounding region of f, computed by a convolutional neural network.
- fs, a segment embedding indicates it is an image embedding as opposed to a text embedding.
- fp, a position embedding, which is used when alignments between words and bounding regions are provided as part of the input, and set to the sum of the position embeddings corresponding to the aligned words.
- The visual embeddings are then passed to the multi-layer Transformer along with the original set of text embeddings, allowing the model to implicitly discover useful alignments between both sets of inputs, and build up a new joint representation.
1.2. Training
- A similar training procedure as BERT is used.
- A resource of paired data is used: COCO dataset that contains images each paired with 5 independent captions.
- There are 3 phases for training:
- Task-Agnostic Pre-Training: VisualBERT is trained on COCO using two visually-grounded language model objectives. (1) Masked language modeling with the image. Some elements of text input are masked and must be predicted but vectors corresponding to image regions are not masked. (2) Sentence-image prediction. For COCO, where there are multiple captions corresponding to one image, we provide a text segment consisting of two captions. One of the caption is describing the image, while the other has a 50% chance to be another corresponding caption and a 50% chance to be a randomly drawn caption. The model is trained to distinguish these two situations.
- Task-Specific Pre-Training: Before fine-tuning VisualBERT to a downstream task, we find it beneficial to train the model using the data of the task with the masked language modeling with the image objective. This step allows the model to adapt to the new target domain.
- Fine-Tuning: This step mirrors BERT fine-tuning, where a task-specific input, output, and objective are introduced, and the Transformer is trained to maximize performance on the task.
- Pre-training on COCO generally takes less than a day on 4 GPU cards while task-specific pre-training and fine-tuning usually takes less.
2. Datasets & Variants
2.1. Datasets
- Four different types of vision-and-language applications are evaluated:
- Visual Question Answering (VQA 2.0) (Goyal et al., 2017),
- Visual Commonsense Reasoning (VCR) (Zellers et al., 2019),
- Natural Language for Visual Reasoning (NLVR2) (Suhr et al., 2019),
- Region-to-Phrase Grounding (Flickr30K) (Plummer et al., 2015).
2.2. Variants
- For task-agnostic pre-training, there are around 100k images with 5 captions each.
- The Transformer encoder in all models has the same configuration as BERTBASE: 12 layers, a hidden size of 768, and 12 self-attention heads.
- 3 VisualBERT variants are tested:
- VisualBERT: The full model with parameter initialization from BERT that undergoes pre-training on COCO, pre-training on the task data, and fine-tuning for the task.
- VisualBERT w/o Early Fusion: VisualBERT but where image representations are not combined with the text in the initial Transformer layer but instead at the very end with a new Transformer layer. This allows to test whether interaction between language and vision throughout the whole Transformer stack is important to performance.
- VisualBERT w/o COCO Pre-training: VisualBERT but where we skip task-agnostic pre-training on COCO captions. This allows to validate the importance of this step.
3. Experimental Results
3.1. VQA

- Given an image and a question, the task is to correctly answer the question.
- The model is trained on the 3,129 most frequent answers and image features from a ResNeXt-based Faster R-CNN pre-trained on Visual Genome is used.
VisualBERT outperforms Pythia v0.1 and v0.3, which are tested under a comparable setting.
3.2. VCR

- VCR consists of 290k questions derived from 110k movie scenes, where the questions focus on visual commonsense. The task is decomposed into two multi-choice sub-tasks wherein individual models are trained: question answering (Q→A) and answer justification (QA→R).
- Image features are obtained from a ResNet-50 and “gold” detection bounding boxes and segmentations provided in the dataset are used.
VisualBERT w/o COCO Pre-training outperforms R2C, which enjoys the same resource while VisualBERT further improves the results.
3.3. NLVR²
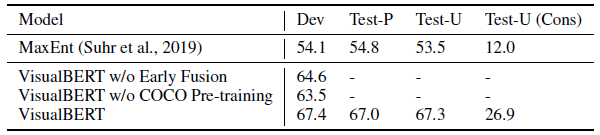
- NLVR² is a dataset for joint reasoning about natural language and images, with a focus on semantic diversity, compositionality, and visual reasoning challenges. The task is to determine whether a natural language caption is true about a pair of images. The dataset consists of over 100k examples of English sentences paired with web images.
- An off-the-shelf detector from Detectron is used to provide image features and 144 proposals per image are used.
VisualBERT w/o Early Fusion and VisualBERT w/o COCO Pre-training surpass the previous best model MaxEnt by a large margin while VisualBERT widens the gap.
3.4. Flickr30K

- Flickr30K Entities dataset tests the ability of systems to ground phrases in captions to bounding regions in the image. The task is, given spans from a sentence, selecting the bounding regions they correspond to. The dataset consists of 30k images and nearly 250k annotations.
- Image features from a Faster R-CNN pre-trained on Visual Genome are used. For task specific fine-tuning, an additional self-attention block is introduced and the average attention weights from each head are used to predict the alignment between boxes and phrases.
VisualBERT outperforms the current state-of-the-art model BAN.
3.5. Ablation Studies

- C1: drops the accuracy, which shows that pre-training on paired vision and language data is important.
- C2: drops the accuracy, which shows that multiple interaction layers between vision and language are important.
- C3: While it does seem weights from language-only pre-trained BERT are important, performance does not degrade as much as expect, arguing that the model is likely learning many of the same useful aspects about grounded language during COCO pre-training.
- Object 2 (The sentence-image prediction objective): has positive but less significant effect, compared to other components.
3.6. Qualitative Results

- The first column is 3 random examples where alignments match Flickr30k annotations while the second column is 3 random examples where alignments do not match.
VisualBERT is capable of detecting these dependency relationships without direct supervision.
Reference
[2019 arXiv] [VisualBERT]
VisualBERT: A Simple and Performant Baseline for Vision and Language
Visual/Vision/Video Language Model
2019 [VideoBERT] [VisualBERT]
