Review — VideoBERT: A Joint Model for Video and Language Representation Learning

VideoBERT: A Joint Model for Video and Language Representation Learning, VideoBERT, by Google Research
2019 ICCV, Over 500 Citations (Sik-Ho Tsang @ Medium)
Vision Language Model, Video Captioning, Video Classification, BERT
- A joint visual-linguistic model is proposed to learn high-level features without any explicit supervision.
- VideoBERT builds upon the BERT and S3D model to learn bidirectional joint distributions over sequences of visual and linguistic tokens.
- VideoBERT can be used for numerous tasks, including action classification and video captioning.
Outline
- VideoBERT
- Experimental Results
1. VideoBERT
1.1. Usage

- The above 2 figures show the examples:
- Above: Given some recipe text divided into sentences, y=y1:T, we generate a sequence of video tokens x=x1:T by computing xt= arg max k p(xt=k|y) using VideoBERT.
- Below: Given a video token, the top three future tokens are forecasted by VideoBERT at different time scales.
1.2. BERT
- (Please skip this part if you know BERT well.)
- let x={x1, …, xL} be a set of discrete tokens. A joint probability distribution over this set is defined as follows:

- The above model is permutation invariant.
- The log potential (energy) functions for each location are defined by:

- where xl is a one-hot vector for the l-th token (and its tag), and:

- The function f(x\l) is a multi-layer bidirectional transformer model that takes an L×D1 tensor, containing the D1-dimensional embedding vectors corresponding to x\l, and returns an L×D2 tensor, where D2 is the size of the output of each transformer node.
- The model is trained to approximately maximize the pseudo log-likelihood:

- In practice, the log-loss (computed from the softmax predicted by the f function) stochastically optimized by sampling locations as well as training sentences.
- BERT accomplishes this by prepending every sequence with a special classification token, [CLS], and by joining sentences with a special separator token, [SEP]. The final hidden state corresponding to the [CLS] token is used as the aggregate sequence representation from which a label is predicted for classification task.
- A typical masked-out training sentence pair may look like this:
[CLS] let’s make a traditional [MASK] cuisine [SEP] orange chicken with [MASK] sauce [SEP]- where [mask] is to mask out some words randomly.
- The corresponding class label in this case would be c=1, indicating that the 2 sentences x and y are consecutive.
1.3. Proposed VideoBERT

- The linguistic sentence (derived from the video using Automatic Speech Recognition, ASR) is combined with the visual sentence to generate data such as this:
[CLS] orange chicken with [MASK] sauce [>] v01 [MASK] v08 v72 [SEP]- where v01, v08 and v72 are visual tokens, and [>] is a special token to combine text and video sentences.
1.3.1. Text Token
- For each ASR word sequence, an off-the-shelf LSTM-based language model is used to break the stream of words, and the text is tokenized into WordPieces using the vocabulary provided by BERT, which contains 30,000 tokens.
1.3.2. Visual Token
- To obtain the visual token, visual features are firstly extracted. S3D, a Kinetic-pretrained video classification model is used. The feature activations before the final linear classifier is taken and 3D average pooling is applied to obtain a 1024-dimension feature vector.
- The visual features are tokenized using hierarchical k-means. The number of hierarchy levels d=4 and the number of clusters per level k=12 are used which yields 1²⁴ = 20736 clusters in total.
1.3.3. Training

- Neighboring sentences are randomly concatenated into a single long sentence, to allow the model to learn semantic correspondence.
- A subsampling rate of 1 to 5 steps is randomly picked for the video tokens. This not only helps the model be more robust to variations in video speeds, but also allows the model to capture temporal dynamics over greater time horizons and learn longer-term state transitions.
- Three training regimes corresponding to the different input data modalities: text-only, video-only and video-text.
- For text-only and video-only, the standard mask-completion objectives are used for training the model.
- For text-video, the linguistic-visual alignment classification objective described above is used.
- The overall training objective is a weighted sum of the individual objectives.
The text objective forces VideoBERT to do well at language modeling; the video objective forces it to learn a “language model for video”, which can be used for learning dynamics and forecasting; and the text-video objective forces it to learn a correspondence between the two domains.
1.4. Model
- Pretrained BERTLARGE is used, which has 24 layers of Transformer blocks, where each block has 1024 hidden units and 16 self-attention heads.
- Video tokens are supported by appending 20,736 entries to the word embedding lookup table for each of new “visual words”.
2. Experimental Results
2.1. Dataset
- VideoBERT is used for instructional videos, and particularly focuses on cooking videos, since it is a well studied domain with existing annotated datasets.
- A set of publicly available cooking videos from YouTube is used for training. The total duration of this dataset is 23,186 hours, or roughly 966 days.
- VideoBERT is evaluated using the YouCook II dataset [38], which contains 2000 YouTube videos averaging 5.26 minutes in duration, for a total of 176 hours.
2.2. Zero-Shot Action Classification

- Zero-shot means the pretrained model does not train on YouCook II.
- The video clip is first converted into video tokens, and then visualized using their centroids.
- The above figure shows the results of predicting nouns and verbs given a video clip.

- The supervised framework S3D outperforms VideoBERT in top-1 verb accuracy, which is not surprising.
Zero-shot VideoBERT significantly outperforms both baselines.

- Random subsets of 10K, 50K and 100K videos are taken from the pretraining set.
The accuracy grows monotonically as the amount of data increases, showing no signs of saturation. This indicates that VideoBERT may benefit from even larger pretraining datasets.
2.3. Transfer Learning for Video Captioning
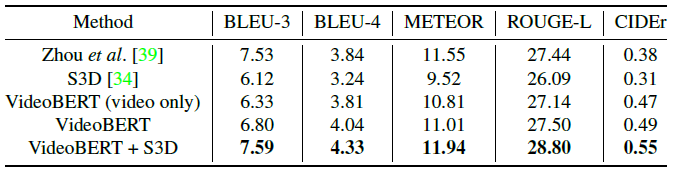
- To extract features given only video inputs, a simple fill-in-the-blank task is used by appending the video tokens to a template sentence:
now let’s [MASK] the [MASK] to the [MASK], and then [MASK] the [MASK].- The features for the video tokens and the masked out text tokens are extracted, then averaged and concatenated together, and the trained model is used by a supervised model in a downstream task.
- The video captioning model from [39] is used where the ground truth video segmentations are used to train a supervised model mapping video segments to captions.
- The same model from [39] is used, namely a transformer encoder-decoder, but the inputs to the encoder are replaced with the features derived from VideoBERT described above. The VideoBERT features are concatenated with average-pooled S3D features.
- The number of Transformer block layers is set to 2.
VideoBERT consistently outperforms the S3D baseline, especially for CIDEr. Furthermore, by concatenating the features from VideoBERT and S3D, the model achieves the best performance across all metrics.
- Below shows the qualitative results.

2.4. Visualized Results in Appendix



Reference
[2019 ICCV] [VideoBERT]
VideoBERT: A Joint Model for Video and Language Representation Learning
Visual/Vision/Video Language Model (VLM)
2019 [VideoBERT]
Video Classification / Action Recognition
2014 [Deep Video] [Two-Stream ConvNet] 2015 [DevNet] [C3D] 2016 [TSN] 2017 [Temporal Modeling Approaches] [4 Temporal Modeling Approaches] [P3D] [I3D] 2018 [NL: Non-Local Neural Networks] 2019 [VideoBERT]
Video Captioning
2019 [VideoBERT]
