Review — YOLOv7: Trainable Bag-of-Freebies Sets New State-of-the-Art for Real-Time Object Detectors
YOLOv7, Train From Scratch, Outperforms All Object Detectors
YOLOv7: Trainable Bag-of-Freebies Sets New State-of-the-Art for Real-Time Object Detectors, YOLOv7, by Institute of Information Science
2023 CVPR, Over 300 Citations (Sik-Ho Tsang @ Medium)
Object Detection, YOLO Series
- Unlike the previous YOLOv5 and YOLOv6, YOLOv7 comes from the author of YOLOv4 Alexey Bochkovskiy.
- Extended efficient layer aggregation networks (E-ELAN), model scaling, and a set of trainable bag-of-freebies are used.
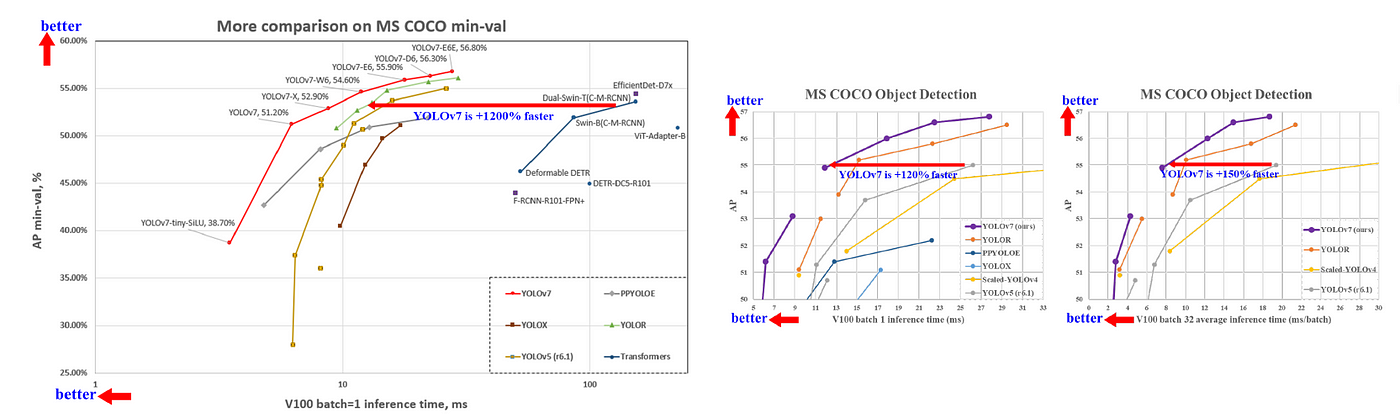
- YOLOv7 surpasses all known object detectors in both speed and accuracy in the range from 5 FPS to 160 FPS and has the highest accuracy 56.8% AP among all known real-time object detectors with 30 FPS or higher on GPU V100.
Outline
- Extended Efficient Layer Aggregation Networks (E-ELAN)
- Model Scaling for Concatenation-Based Models
- Trainable Bag-of-Freebies
- SOTA Comparisons
1. Extended Efficient Layer Aggregation Networks (E-ELAN)

1.1. Prior Blocks
- (a) VoVNet: An aggregation block in VoVNet.
- (b) CSPVoVNet: is proposed in Scaled-YOLOv4, which is a variation of VoVNet. The gradient path is analyzed in order to enable the weights of different layers to learn more diverse features.
- (Please read VoVNet, and Scaled-YOLOv4 if interested.)

- (c) ELAN: is from an unknown reference [1], in which I cannot google about it, which is also being asked in the post by author in Reddit.
- By controlling the shortest longest gradient path, a deeper network can learn and converge effectively.
1.2. Proposed E-ELAN
- (d) E-ELAN: The proposed extended ELAN (E-ELAN) does not change the gradient transmission path of the original architecture at all.
- Group convolution is used to expand the channel and cardinality of computational blocks.
- The feature map calculated by each computational block will be shuffled into g groups, then concatenate them together.
- Finally, g groups of feature maps are added to perform merge cardinality.
In addition to maintaining the original ELAN design architecture, E-ELAN can also guide different groups of computational blocks to learn more diverse features.
2. Model Scaling for Concatenation-Based Models

- From (a) to (b): It is observed that when depth scaling is performed on concatenation-based models, the output width of a computational block also increases. This phenomenon will cause the input width of the subsequent transmission layer to increase.
- (c) Proposed Model Scaling: When performing model scaling on concatenation-based models, only the depth in a computational block needs to be scaled, and the remaining of transmission layer is performed with corresponding width scaling.
The proposed compound scaling method can maintain the properties that the model had at the initial design and maintains the optimal structure.
3. Trainable Bag-of-Freebies
3.1. Re-Parameterized Convolution

- RepVGG: RepConv actually combines 3×3 convolution, 1×1 convolution, and identity connection in one convolutional layer.
- (Please read RepVGG if interested.)
- When RepConv is directly applied to ResNet and DenseNet and other architectures, its accuracy will be significantly reduced.
- Proposed: RepConv without identity connection (RepConvN) is used to design the architecture of planned re-parameterized convolution.
When a convolutional layer with residual or concatenation is replaced by re-parameterized convolution, there should be no identity connection.
3.2. Coarse for Auxiliary and Fine for Lead Loss

- The head is responsible for the final output as the lead head, and the head used to assist training is called auxiliary head.
- (a) Normal: Only final heads are used for loss estimation.
- (b) Model with Auxiliary Head: With deep supervision, there are auxiliary heads from the intermediate layers to guide the network.
- (c) Independent: Researchers often use the quality and distribution of prediction output by the network, and then consider together with the ground truth.
- The mechanism that considers the network prediction results together with the ground truth and then assigns soft labels as “label assigner”.
- (d) Lead Head Guided Label Assigner: By letting the shallower auxiliary head directly learn the information that lead head has learned, lead head will be more able to focus on learning residual information that has not yet been learned.
- (e) Coarse-to-Fine Lead Head Guided Label Assigner: Similar to (d), however, two different sets of soft label are generated, i.e., coarse label and fine label.
- Fine label is the same as the soft label generated by lead head guided label assigner.
Coarse label is generated by allowing more grids to be treated as positive target by relaxing the constraints of the positive sample assignment process.
3.3. Other Trainable Bag-of-Freebies
- Batch normalization is in conv-bn-activation topology: The purpose of this is to integrate the mean and variance of batch normalization into the bias and weight of convolutional layer at the inference stage.
- Implicit knowledge in YOLOR [81] combined with convolution feature map in addition and multiplication manner: Implicit knowledge in YOLOR can be simplified to a vector by pre-computing at the inference stage.
- This vector can be combined with the bias and weight of the previous or subsequent convolutional layer.
- EMA model: EMA is a technique used in Mean Teacher, and EMA model is only used purely as the final inference model.
4. SOTA Comparisons

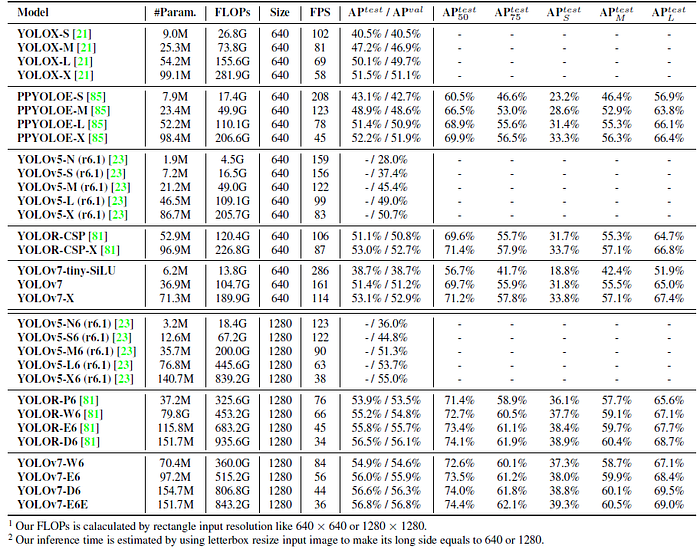
If compared with YOLOv4, YOLOv7 has 75% less parameters, 36% less computation, and brings 1.5% higher AP.
- If compared with state-of-the-art YOLOR-CSP, YOLOv7 has 43% fewer parameters, 15% less computation, and 0.4% higher AP.
- In the performance of tiny model, compared with YOLOv4-tiny-31, YOLOv7-tiny reduces the number of parameters by 39% and the amount of computation by 49%, but maintains the same AP.
On the cloud GPU model, YOLOv7 can still have a higher AP while reducing the number of parameters by 19% and the amount of computation by 33%.
- Comparing YOLOv7-tiny-SiLU with YOLOv5-N (r6.1), the proposed method is 127 fps faster and 10.7% more accurate on AP.
- In addition, YOLOv7 has 51.4% AP at frame rate of 161 fps, while PPYOLOE-L with the same AP has only 78 fps frame rate. In terms of parameter usage, YOLOv7 is 41% less than PPYOLOE-L.
- YOLOv7-D6 has close inference speed to YOLOR-E6, but improves AP by 0.8%. YOLOv7-E6E has close inference speed to YOLOR-D6, but improves AP by 0.3%.
YOLOv7 has the best speed-accuracy trade-off comprehensively.
There is a bunch of ablation experiments. Please feel free to read the paper directly.
References
[2023 CVPR] [YOLOv7]
YOLOv7: Trainable Bag-of-Freebies Sets New State-of-the-Art for Real-Time Object Detectors
[2022] [Being Ask About Reference [1] in Reddit]
https://www.reddit.com/r/MachineLearning/comments/w078id/p_yolov7_trainable_bagoffreebies_sets_new/
Object Detection
2014 … 2021 [Scaled-YOLOv4] [PVT, PVTv1] [Deformable DETR] 2022 [PVTv2] 2023 [YOLOv7]
