Brief Review — Exploring the Boundaries of GPT-4 in Radiology
Evaluation of GPT-4 on Text-Based Radiology Reports
Exploring the Boundaries of GPT-4 in Radiology
GPT-4 in Radiology, by Microsoft Health Futures, and Harvard University
2023 EMNLP (Sik-Ho Tsang @ Medium)Medical/Clinical NLP/LLM
2017 … 2023 [MultiMedQA, HealthSearchQA, Med-PaLM] [Med-PaLM 2]
==== My Other Paper Readings Are Also Over Here ====
- GPT-4 is evaluated on the text-based applications for radiology reports.
Outline
- Experimental Setup
- Results
1. Experimental Setup
- Alongside GPT-4 (gpt-4–32k), two earlier GPT-3.5 models are evaluated: text-davinci-003 and ChatGPT (gpt-35-turbo).
- For each task, zero-shot prompting is started with and prompt complexity is progressively increased to include random few-shot (a fixed set of random examples), and then similarity-based example selection (Liu et al., 2022). For example selection, OpenAI’s general-domain text-embedding-ada-002 model is used to encode the training examples as the candidate pool to select n nearest neighbours for each test instance.
- For NLI, Chain-of-Thought (CoT) is also explored.
- For findings summarisation, ImpressionGPT is replicated (Ma et al., 2023), which adopts dynamic example selection and iterative refinement.
- To test the stability of GPT-4 output, self-consistency is applied for sentence similarity, NLI, and disease classification.
- Mean and standard deviation across five runs are reported.
2. Results
2.1. GPT-4 vs SOTA Radiology Models

The key finding is that GPT-4 outperforms or is on par with SOTA radiology models in the broad range of tasks considered.
- It is further noticed that different tasks require different prompting efforts and strategies.
2.2. Different Tasks in Details

As shown in Table 2, all the GPT models outperform BioViL-T, achieving new SOTA. In particular, GPT-4 significantly outperforms both text-davinci-003 and ChatGPT on MS-CXR-T, indicating an advanced understanding of disease progression.

GPT-4 with CoT achieves a new SOTA on RadNLI, outperforming DoT5 by 10% in macro F1. It is observed that CoT greatly helps in this task especially for GPT-3.5.
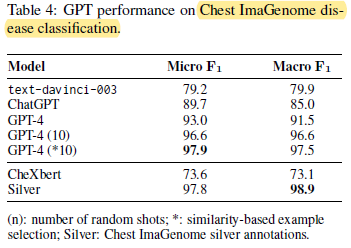
- As shown in Table 4, there is progressive improvement from text-davinci-003 to ChatGPT and then to GPT-4.
- GPT-4 zero-shot performance is improved with 10-shot random in-context examples. A further slight improvement is achieved with similarity-based example selection.
- (For other tasks in details, please feel free to read the paper directly.)
