Review — GPT-4
Accept Image and Text as Inputs

GPT-4 Technical Report,
GPT-4, by OpenAI,
2023 OpenAI (Sik-Ho Tsang @ Medium)
Large Language Model, LLM, Image-Text Foundation Model, Vision Language Model, Visual Language Model, VLMLanguage Model
2021 [Performer] [gMLP] [Roformer] [PPBERT] [DeBERTa] [DeLighT] [Transformer-LS] [R-Drop] 2022 [GPT-NeoX-20B] [GPT-3.5, InstructGPT] [GLM]
Visual/Vision/Video Language Model (VLM)
2022 [FILIP] [Wukong] [LiT] [Flamingo]
==== My Other Paper Readings Are Also Over Here ====
- GPT-4, a large-scale, multimodal model is proposed, which can accept image and text inputs and produce text outputs.
- GPT-4 is a Transformer-based model pre-trained to predict the next token in a document.
- GPT-4 exhibits human-level performance on various professional and academic benchmarks, including passing a simulated bar exam with a score around the top 10% of test takers.
Outline
- GPT-4 Amazing Cases
- GPT-4 Performance
- GPT-4 Limitations, Risks & Mitigations
- GPT-4 Loss Prediction
- In the report, I believe it is due to the model security issue, NO details provided about the architecture (including model size), hardware, training compute, dataset construction, training method, etc.
Differences
- One key difference between models is the context length. The standard GPT-4 model offers 8,000 tokens for the context. OpenAI also offers an extended 32,000 token context-length model.
- The snapshots are referred to the specific date in the model name, such as
gpt-4-0314orgpt-4-32k-0314. The March 14th snapshot will be available until June 14th.
1. GPT-4 Amazing Cases
1.1. Be My Eyes

“Be My Eyes” App accept image and text as input, then the app will answer the question according to the image and text via GPT-4.
1.2. Morgan Stanley

The bot can answer in details like a human.
1.3. Duolingo
Similar for Duolingo app for language learning.
1.4. Visual Inputs

GPT-4 can answer what is happening in the figures.

Left: It can answer a physics question with snapshot provided.
Right: Summarizing a paper with snapshot provided.
1.5. Pure Text Inputs


Closed-end multiple choice question is supported.
Open-end question is also supported. (Not shown here)
2. GPT-4 Performance
2.1. Professional Benchmarks

- GPT-4 is tested on a diverse set of benchmarks, including simulating exams that were originally designed for humans. Exam questions included both multiple-choice and free-response questions. Separate prompts are designed for each format, and images were included in the input for questions which required it.
GPT-4 exhibits human-level performance on the majority of these professional and academic exams. Notably, it passes a simulated version of the Uniform Bar Examination with a score in the top 10% of test takers.
2.2. Academic Benchmarks
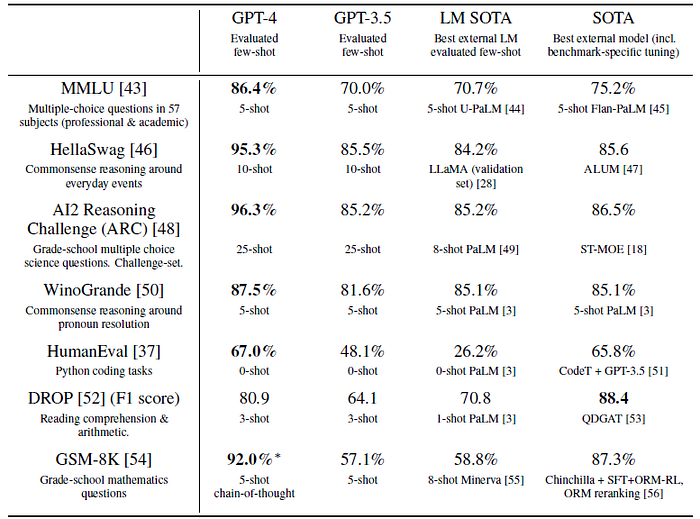
GPT-4 considerably outperforms existing language models, as well as previously state-of-the-art (SOTA) systems, on academic benchmarks.

- Figure provided above, summarizing the performance on academic and professional exams.
GPT-4 outperforms GPT-3.5 on most exams tested.
2.3. Multilingual Performance
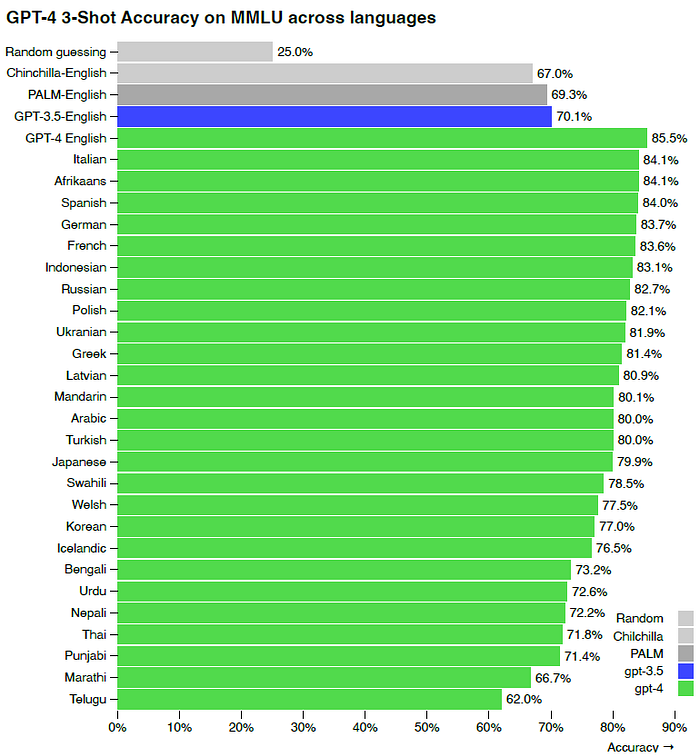
GPT-4 outperforms the English-language performance of GPT 3.5 and existing language models (Chinchilla [2] and PaLM [3]) for the majority of languages that tested, including low-resource languages such as Latvian, Welsh, and Swahili.
3. GPT-4 Limitations, Risks & Mitigations
3.1. Limitations

- GPT-4 has similar limitations as earlier GPT models. It still is not fully reliable (it “hallucinates” facts and makes reasoning errors).
GPT-4 significantly reduces hallucinations relative to previous GPT-3.5 models (which have themselves been improving with continued iteration). GPT-4 scores 19 percentage points higher than the latest GPT-3.5 on the internal, adversarially-designed factuality evaluations.
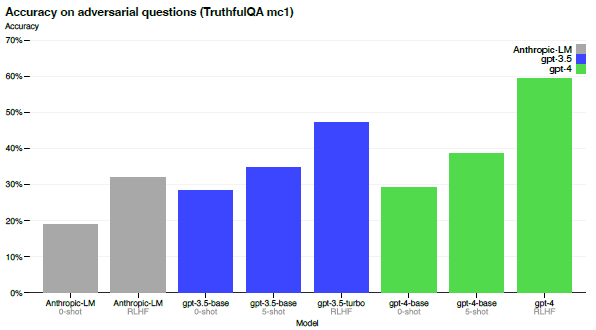
- The GPT-4 base model is only slightly better at this task than GPT-3.5.
However, after Reinforcement Learning from Human Feedback (RLHF) post-training, large improvements are observed over GPT-3.5.
3.2. Risks & Mitigations

- OpenAI spends significant effort towards improving the safety and alignment of GPT-4.
- Adversarial Testing via Domain Experts: 50 experts from domains such as long-term AI alignment risks, cybersecurity, biorisk, and international security adversarially tested the model. Recommendations and training data gathered from these experts fed into the mitigations and improvements for the model.
Additional data is colleceted to improve GPT-4’s ability to refuse requests on how to synthesize dangerous chemicals, as above.


- Model-Assisted Safety Pipeline: The approach to safety consists of two main components, an additional set of safety-relevant RLHF training prompts, and rule-based reward models (RBRMs).
RBRMs are a set of zero-shot GPT-4 classifiers. These classifiers provide an additional reward signal to the GPT-4 policy model during RLHF fine-tuning that targets correct behavior, such as refusing to generate harmful content or not refusing innocuous requests, as above.
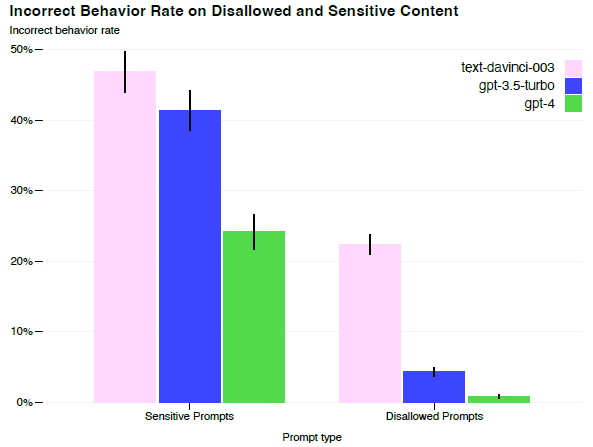
On the RealToxicityPrompts dataset, GPT-4 produces toxic generations only 0.73% of the time, while GPT-3.5 generates toxic content 6.48% of time.
4. GPT-4 Loss Prediction

- GPT-4’s final loss is predicted on the internal codebase (not part of the training set) by fitting a scaling law:
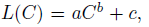
- This prediction was made shortly after the run started, without use of any partial results. The fitted scaling law predicted GPT-4’s final loss with high accuracy.
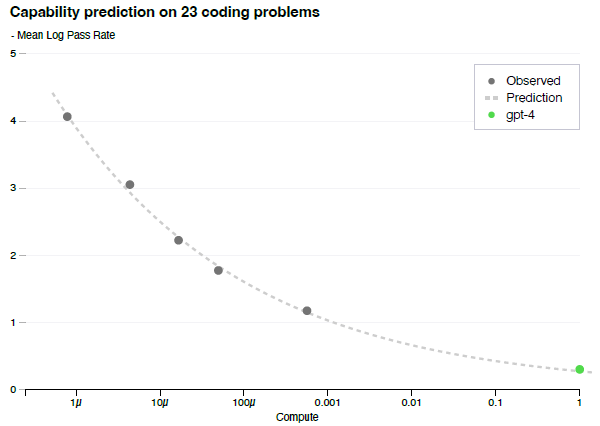
- To predict a more interpretable metric of capability, an approximate power law relationship is found on a subset of HumanEval dataset.
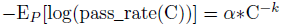
It successfully predicted the pass rate as above.
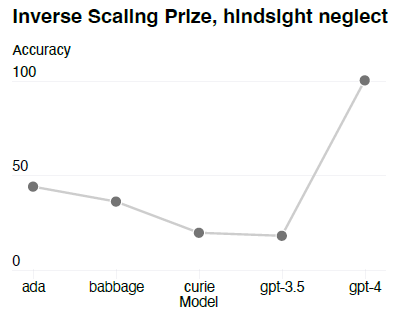
- Some tasks are still challenging to predict, GPT-4 reverses the trend, as shown on one of the tasks called Hindsight Neglect.
Authors believe that accurately predicting future capabilities is important for safety. Going forward authors plan to refine these methods and register performance predictions across various capabilities before large model training begins, and hope this becomes a common goal in the field.
