Review — GPT-3.5, InstructGPT: Training Language Models to Follow Instructions With Human Feedback
ChatGPT is a Sibling Model to InstructGPT, It is Also Called GPT-3.5. Later on, GPT-4 is Also Published.

Training Language Models to Follow Instructions With Human Feedback,
GPT-3.5 or InstructGPT, by OpenAI,
2022 NeurIPS, Over 180 Citations (Sik-Ho Tsang @ Medium)
Natural Language Processing, NLP, LLM, GPT, GPT-2, GPT-3, GPT-3.5, ChatGPT, GPT-41991 … 2021 [Performer] [gMLP] [Roformer] 2022 [GPT-NeoX-20B] [GPT-3.5, InstructGPT]
==== My Other Previous Paper Readings ====
- Recently, ChatGPT has a very hot topic not just among researchers, but also heavily discussed in forums and demonstrated in many YouTube channels, etc. Indeed, ChatGPT is a sibling model to InstructGPT.
- Large language models (LLMs) is not aligned with users, which can generate outputs that are untruthful, toxic, or simply not helpful to the user. This is simply because LLMs are trained to predict the next words or masked words only.
- InstructGPT is proposed to align the model. To try ChatGPT: https://openai.com/blog/chatgpt/
- Later on, GPT-4 is also published, which supports image modality.
Outline
- InstructGPT
- Results
1. InstructGPT
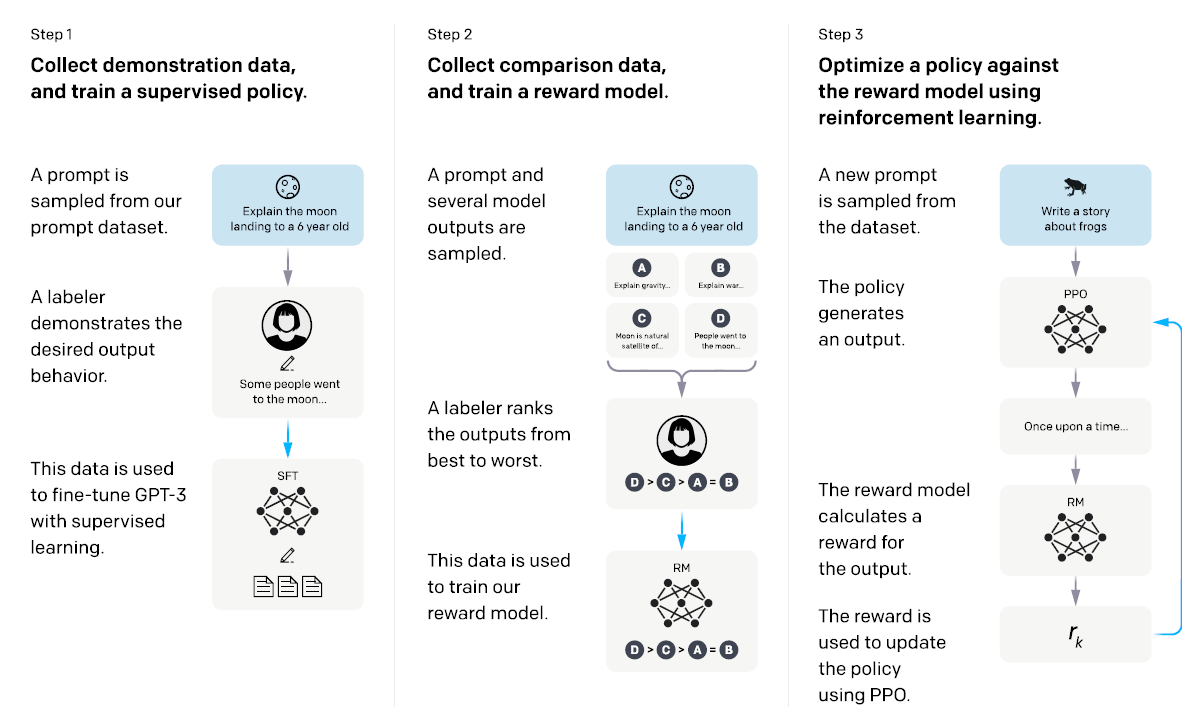
1.1. Overall Pipeline
- A pretrained language model, i.e. GPT-3 here, is used as starting point. The steps mainly follow Human Feedback Model.
- Step 1: Collect demonstration data, and train a supervised policy. The labelers provide demonstrations of the desired behavior on the input prompt distribution. Then, a pretrained GPT-3 model is fine-tuned on this data using supervised learning.
- Step 2: Collect comparison data, and train a reward model. A dataset of comparisons between model outputs is collected, where labelers indicate which output they prefer for a given input. Then, a reward model is trained to predict the human-preferred output.
- Step 3: A policy is optimized against the reward model using PPO. The output of the RM is used as a scalar reward. The supervised policy is fine-tuned to optimize this reward using the PPO algorithm.
- Steps 2 and 3 can be iterated continuously; more comparison data is collected on the current best policy, which is used to train a new RM and then a new policy.
1.2. Dataset Generation

- The prompt dataset consists primarily of text prompts submitted to the OpenAI API, specifically those using an earlier version of the InstructGPT models (trained via supervised learning on a subset of the demonstration data) on the Playground interface.
- To train the very first InstructGPT models, labels are asked to write prompts themselves.
- The distribution of use-case categories for API prompts is as shown above. Most of the use-cases have are generative, rather than classification or QA. Some examples are also shown as above.
- To produce the demonstration and comparison data, and to conduct the main evaluations, a team of about 40 contractors is hired on Upwork and through ScaleAI.
- Labelers are required to do their best to infer the intent of the user who wrote the prompt, and ask them to skip inputs where the task is very unclear.
- Moreover, the labelers also take into account the implicit intentions such as truthfulness of the response, and potentially harmful outputs such as biased or toxic language, guided by the instructions.
1.3. Step 1: Supervised Fine-Tuning (SFT)
- GPT-3 is fine-tuned on the labeler demonstrations using supervised learning for 16 epochs.
1.4. Step 2: Reward Model (RM)
- Starting from the SFT model with the final unembedding layer removed, a model is trained to take in a prompt and response, and output a scalar reward.
- For each prompt, (K 2) comparisons are produced for each prompt, shown to a labeler to generate the dataset D, as equated below.
- RM is trained on a dataset of comparisons between two model outputs on the same input. They use a cross-entropy loss, with the comparisons as labels — the difference in rewards represents the log odds that one response will be preferred to the other by a human labeler.
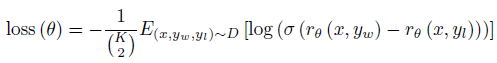
- where rθ(x, y) is the scalar output of the reward model for prompt x and completion y with parameters θ, yw is the preferred completion out of the pair of yw and yl, and D is the dataset of human comparisons.
1.5. Reinforcement Learning (RL)
- The SFT model is fine-tuned on the environment using PPO (Schulman et al., 2017).
- The environment is a bandit environment which presents a random customer prompt and expects a response to the prompt. Given the prompt and response, it produces a reward determined by the reward model and ends the episode. These models are “PPO”.
- With mixing the pretraining gradients into the PPO gradients, these models are “PPO-ptx”.
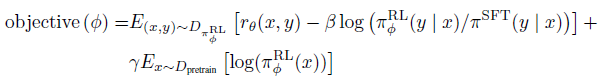
- where πRLϕ is the learned RL policy, πSFT is the supervised trained model, and Dpretrain is the pretraining distribution. The KL reward coefficient, β, and the pretraining loss coefficient, γ, control the strength of the KL penalty and pretraining gradients respectively.
- For “PPO” models, γ is set to 0.
2. Results
2.1. Comparison with GPT-3

- For each model, labelers calculate how often its outputs are preferred to a baseline 175B SFT.
- The models generalize to the preferences of “held-out” labelers that did not produce any training data.
Labelers significantly prefer InstructGPT outputs over outputs from GPT-3.
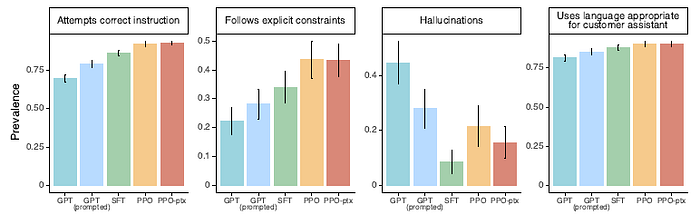
- Compared to GPT-3, InstructGPT outputs are more appropriate in the context of a customer assistant, more often follow explicit constraints defined in the instruction (e.g. “Write your answer in 2 paragraphs or less.”), are less likely to fail to follow the correct instruction entirely, and make up facts (‘hallucinate’) less often in closed-domain tasks.
These results suggest that InstructGPT models are more reliable and easier to control than GPT-3.
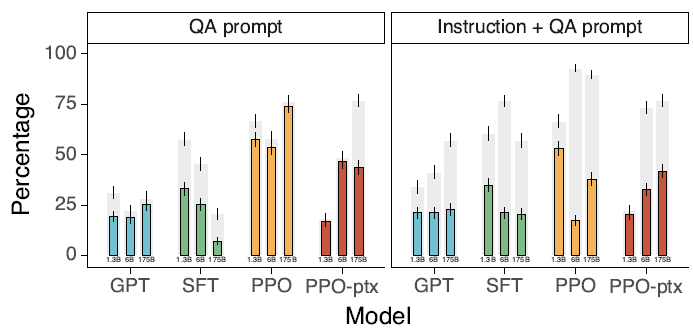
2.2. Are Public NLP Datasets Useful?
- While 175B GPT-3 baselines are fine-tuned on public NLP datasets FLAN and T0, their scores are not high.
- Because InstructedGPT is trained using open-ended generation and brainstorming which consist of about 57% of the prompt dataset according to labelers. Also, it can be difficult for public NLP datasets to obtain a very high diversity of inputs.
Public NLP datasets are not reflective of how the language models are used.
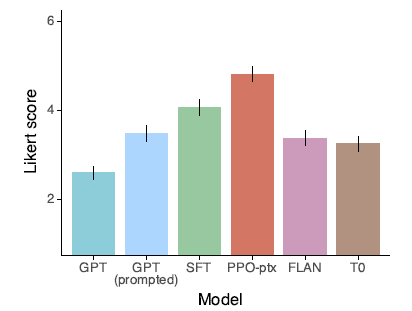
2.3. Truthfulness on TruthfulQA Dataset
InstructGPT models show improvements in truthfulness over GPT-3.
2.4. Toxicity on RealToxicityPrompts Dataset
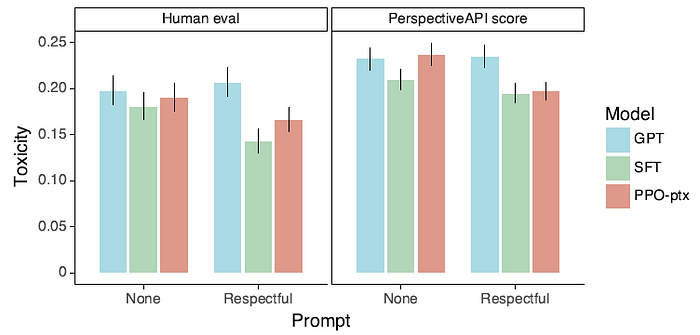
- When instructed to produce a safe and respectful output (“respectful prompt”), InstructGPT models generate less toxic outputs than those from GPT-3 according to the Perspective API.
InstructGPT shows small improvements in toxicity over GPT-3, but not bias.
2.5. Qualitative Results

- The model is not explicitly trained for codes or other languages.
- 175B PPO-ptx model is able to reliably answers questions about code, and can also follow instructions in other languages.
InstructGPT models show promising generalization to instructions outside of the RLHF finetuning distribution.

- Prompt 1: When given an instruction with a false premise, the model sometimes incorrectly assumes the premise is true.
- Prompt 2: The model can overly hedge.
InstructGPT still makes simple mistakes.
To align the model, large amount of human forces is needed to judge whether the sentences are truthful, not toxic, or helpful, etc.
The paper has 68 pages. I have only presented some of them. If interested, please feel free to read the paper directly. There also other sections such as impacts, limitations, etc.
References
[OpenAI Blog] [InstructGPT] https://openai.com/blog/instruction-following/
[OpenAI Blog] [ChatGPT] https://openai.com/blog/chatgpt/
