[Paper] ACoL: Adversarial Complementary Learning (Weakly Supervised Object Localization)
End-to-End Network for WSOL, Overperforms CAM & Hide-and-Seek

In this story, Adversarial Complementary Learning for Weakly Supervised Object Localization, ACoL, by University of Technology Sydney, University of Illinois Urbana-Champaign, and National University of Singapore, is presented. In this paper:
- Weakly Supervised Object Localization (WSOL) is to have object localization while without object bounding box labels, but with only image-level label, for training.
- A simple network architecture is proposed which includes two parallel-classifiers for object localization. Classification while also dynamically localizing some discriminative object regions during the forward pass.
- An adversarial learning, the two parallel-classifiers are forced to leverage complementary object regions for classification and can finally generate integral object localization together.
This is a paper in 2018 CVPR with over 170 citations. (Sik-Ho Tsang @ Medium)
Outline
- ACoL: Network Architecture
- Ablation Study
- Experimental Results
1. ACoL: Network Architecture

- Conventionally, a deep classification network usually leverages the unique pattern of a specific category for recognition and the generated object localization maps can only highlight a small region of the target object instead of the entire object.
The proposed ACoL aims at discovering the integral object regions through an adversarial learning manner.
1.1. ACoL Architecture
- The proposed ACoL, including three components, Backbone, Classifier A and Classifier B.
- Backbone: A fully convolutional network acting as a feature extractor.
- The feature maps from Backbone are then fed into the following parallel classification branches.
- Both branches consist of the same number of convolutional layers followed by a GAP layer and a softmax layer for classification.
In particular, the input features of Classifier B are erased with the guidance of the mined discriminative regions produced by Classifier A.
- The discriminative regions are identified by conducting a threshold on the localization maps of Classifier A.
- The corresponding regions within the input feature maps for Classifier B are then erased in an adversarial manner via replacing the values by zeros.
- More precisely, the regions that are larger than a threshold δ is erased.
- Such an operation encourage Classifier B to leverage features from other regions of the target object for supporting image-level labels.
- Finally, the integral localization map of the target object will be obtained by combining the localization maps produced by the two branches. Max function is used as the fusing operation.
- The whole process is trained in an end-to-end way. Both classifiers adopt the cross entropy loss function for training.
1.2. VGGNet and GoogLeNet
- The proposed ACoL using VGGNet and GoogLeNet are used.
- Particularly, remove the layers after conv5–3 (from pool5 to prob) of VGG-16 network and the last inception block of GoogLeNet.
- Then, add two convolutional layers of kernel size 3 × 3, stride 1, pad 1 with 1024 units and a convolutional layer of size 1 × 1, stride 1 with 1000 units (200 and 256 units for CUB-200–2011 and Caltech-256 datasets, respectively).
- Finally, a GAP layer and a softmax layer are added on the top of the convolutional layers.
1.3. Testing
- During testing, The fused object maps are extracted according to the predicted class and resize them to the same size with the original images by linear interpolation.
- For fair comparison, we apply the same strategy detailed in CAM to produce object bounding boxes based on the generated object localization maps.
- In particular, first segment the foreground and background by a fixed threshold. Then, seek the tight bounding boxes covering the largest connected area in the foreground pixels.
2. Ablation Study

- Two findings are observed.
- The proposed complementary branch (Classifier B) successfully works collaboratively with Classifier A.
- A well-designed threshold is needed. A too large threshold cannot effectively encourage Classifier B to discover more useful regions and a too small threshold may bring background noises.
- A cascade network of three classifiers is also tested.
- In particular, the third classifier is added and its input feature maps are erased/guided by the fused object localization maps from both Classifier A and B. But there is no significant improvement.
3. Experimental Results
3.1. Classification

- GoogLeNet-ACoL and VGGNet-ACoL achieve slightly better classification results than GoogLeNet-GAP and VGGNet-GAP, respectively, and are comparable to the original GoogLeNet and VGGNet.
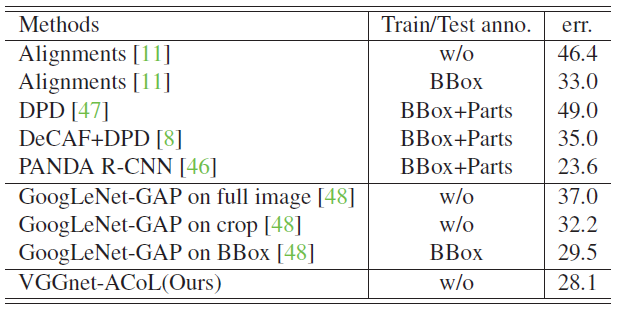
- VGGNet-ACoL achieves the lowest error 28.1% among all the methods without using bounding box.
The proposed method can enable the networks to achieve equivalent classification performance with the original networks. It is attributed to the erasing operation which guides the network to discover more discriminative patterns.
3.2. Localization
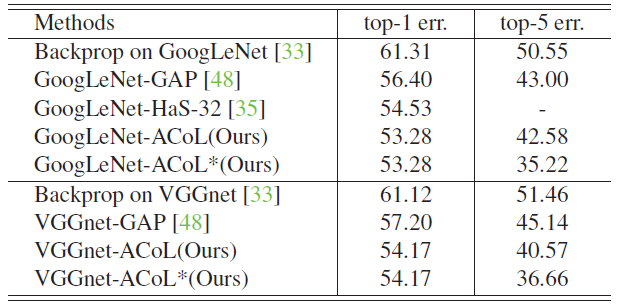
- The proposed ACoL approach outperforms all baselines.
- VGGNet-ACoL is significantly better than VGGNet-GAP and GoogLeNet-ACoL also achieves better performance than GoogLeNet-HaS-32.
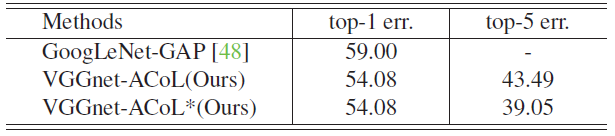
- Again, the proposed method outperforms GoogLeNet-GAP by 4.92% in Top-1 error.
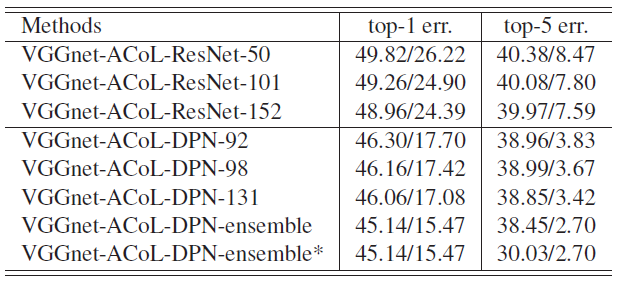
- SOTA network ResNet and DPN are used.
- A boost to 45.14% in Top-1 error and 38.45% in Top-5 error obtained when applying the classification results generated from the ensemble DPN.
- In addition, the Top-5 localization performance (indicated by *) is boosted by only selecting the bounding boxes from the top three predicted classes following CAM.
- VGGNet-ACoL-DPN-ensemble* achieves 30.03% on ILSVRC.
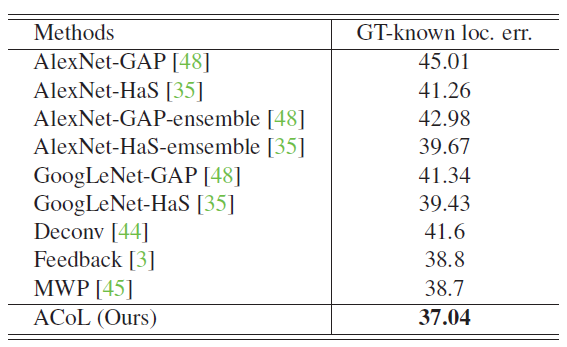
- The influence caused by classification results is eliminated and compare the localization accuracy using ground-truth labels.
- The proposed ACoL approach achieves 37.04% in Top-1 error and surpasses the other approaches.
3.3. Visualization


- For each image above, object localization maps from Classifier A (middle left), Classifier B (middle right) and the fused maps (right) are shown.
- The proposed two classifier (A and B) can discover different parts of target objects so as to locate the entire regions of the same category in a given image.
Reference
[2018 CVPR] [ACoL]
Adversarial Complementary Learning for Weakly Supervised Object Localization
Weakly Supervised Object Localization (WSOL)
2014 [Backprop] 2016 [CAM] 2017 [Hide-and-Seek] 2018 [ACoL]
