[Paper] Hide-and-Seek (Weakly Supervised Object Localization & Action Localization)
Outperforms Backprop & CAM for WSOL. C3D Features Used with Hide-and-Seek for Weakly Supervised Action Localization

In this story, Hide-and-Seek: Forcing a Network to be Meticulous for Weakly-supervised Object and Action Localization (Hide-and-Seek), by University of California, is shortly presented. In this paper:
- Weakly-Supervised Object Localization (WSOL) is to localize the object while there is no object bounding box label but only the image-level label.
- The main idea is to hide patches in a training image randomly, forcing the network to seek other relevant parts when the most discriminative part is hidden.
- Thus, only input image needs to be modified during training.
This is a paper in 2017 ICCV with over 300 citations. (Sik-Ho Tsang @ Medium)
Outline
- Hide-and-Seek
- Weakly-Supervised Object Localization (WSOL)
- Weakly-Supervised Action Localization
1. Hide-and-Seek

- Left: For each training image, we divide it into a grid of S×S patches. Each patch is then randomly hidden with probability phide and given as input to a CNN to learn image classification.
- The hidden patches change randomly across different epochs.
- The values for the hidden area are set to be the expected pixel value of the training data.
- Right: During testing, the full image without any hidden patches is given as input to the trained network.
- The reason to use Hide-and-Seek is that:
Existing methods are prone to localizing only the most discriminative object parts, since those parts are sufficient for optimizing the classification task.
To enforce the network to learn all of the relevant parts of an object, the proposed key idea is to randomly hide patches of the input image.
2. Weakly-Supervised Object Localization (WSOL)

- Top-1 Clas: Top-1 Classification accuracy.
- Top-1 Loc: Top-1 localization accuracy.
- GT-known Loc: Localization accuracy with already known object label.
- AlexNet-GAP (CAM), is used as the baseline.
- Alex-HaS-N is our approach, in which patches of size N×N are hidden with 0.5 probability during training.
- AlexNet-HaS-Mixed: During training, for each image in every epoch, the patch size N to hide is chosen randomly from 16, 32, 44 and 56 as well as no hiding (full image).
- Since different sized patches are hidden, the network can learn complementary information about different parts of an object
- AlexNet-HaS-Mixed achieves the best results for Top-1 Loc.
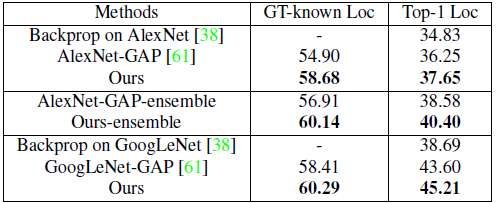
- Proposed HaS performs 3.78% and 1.40% points better than AlexNet-GAP in CAM on GT-known Loc and Top-1 Loc, respectively. For GoogLeNet, our model gets a boost of 1.88% and 1.61% points compared to GoogLeNet-GAP
- for GT-known Loc and Top-1 Loc accuracy, respectively.
- To produce the final localization for an image, authors average the CAMs obtained using AlexNet-HaS-16, 32, 44, and 56, while for classification, authors average the classification probabilities of all four models as well as the probability obtained using AlexNet-GAP.
- This ensemble model gives a boost of 5.24 % and 4.15% over AlexNet-GAP (CAM) for GT-known Loc and Top-1 Loc, respectively.
- For a more fair comparison, five independent AlexNet-GAPs are ensembled to create an ensemble baseline.
- The proposed ensemble outperforms this strong baseline (AlexNet-GAP-ensemble) by 3.23% and 1.82% for GT-known Loc and Top-1 Loc, respectively.

- The class activation map (CAM) and bounding box obtained by AlexNet-HaS approach is visualized.
- For example, in the first, second, and fifth rows, AlexNet-GAP only focuses on the face of the animals, whereas HaS method also localizes parts of the body.
- Similarly, in the third and last rows, AlexNet-GAP misses the tail for the snake and squirrel while ours gets the tail.
3. Weakly-Supervised Action Localization

- For action localization, C3D fc7 features are computed using a model pre-trained on Sports 1 million dataset.
- 10 feats/sec are computed (each feature is computed over 16 frames).
- C3D features are fed as input to a CNN with two conv layers followed by a global max pooling and softmax classification layer.
- Each conv layer has 500 kernels of size 1×1, stride 1. For any hidden frame, mean C3D feature is assigned.
- For thresholding, 50% of the max value of the CAM is chosen. All continuous segments after thresholding are considered predictions.
- Video-HaS randomly hides frame segments while learning action classification, with a baseline that sees the full video (Video-full).
- The above shows the result on THUMOS validation data. Video-HaS consistently outperforms Video-full for action localization task, which shows that hiding frames forces our network to focus on more relevant frames, which ultimately leads to better action localization.
There are also numerous ablation experiments. If interested, please feel free to visit the paper.
Reference
[2017 ICCV] [Hide-and-Seek]
Hide-and-Seek: Forcing a Network to be Meticulous for Weakly-supervised Object and Action Localization
Weakly Supervised Object Localization (WSOL)
2014 [Backprop] 2016 [CAM] 2017 [Hide-and-Seek]
