Brief Review — A-HRNet: Attention Based High Resolution Network for Human Pose Estimation

A-HRNet: Attention Based High Resolution Network for Human Pose Estimation,
A-HRNet, by University of Massachusetts Lowell,
2020 TransAI (Sik-Ho Tsang @ Medium)Human Pose Estimation
2014 … 2018 [PersonLab] 2019 [HRNet / HRNetV1] 2021 [HRNetV2, HRNetV2p] [Lite-HRNet]
==== My Other Paper Readings Are Also Over Here ====
Outline
- A-HRNet
- Results
1. A-HRNet
1.1. Overall Architecture

- The original architecture is HRNet, btu with attention added at the red arrows as shown above.
1.2. Attention Block

- (Please feel free to read SENet for more details.)
- Suppose that the size of the input feature map is Dw×Dh×c, in which c is the number of channels and Dw×Dh is the feature map size, the computing cost for the channel attention branch is:

- where s is the scale parameter for the channel attention branch.
- s=4 in the paper.
- The computing cost for the main convolutional branch is:

Thus, the computing cost for the channel attention branch is much smaller than that of the main branch:
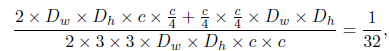
2. Results
2.1. COCO

All the models using attention branches achieve better AP scores than the original HRNet without attention branches.

A-HRNet achieves an AP score of 77.7, outperforming all other methods. Note that the model is trained on COCO train2017 set from scratch without extra data.
Compared to DNANet [11], the proposed model improves the AP score by 0.8 points with fewer number of parameters and GFLOPs.
2.2. Rehabilitation Activities

The proposed model considerably outperforms the original HRNet with the same training settings.
