Brief Review — CheXtransfer: Performance and Parameter Efficiency of ImageNet Models for Chest X-Ray Interpretation
CheXtransfer, Data-Centric Analysis on Chest X-Ray
CheXtransfer: Performance and Parameter Efficiency of ImageNet Models for Chest X-Ray Interpretation
CheXtransfer, by Stanford University
2021 CHIL (Sik-Ho Tsang @ Medium)
Medical Imaging, Medical Image Classification, Image Classification
- Deep learning methods for chest X-ray interpretation typically rely on pretrained models developed for ImageNet.
- In this work, authors compare the transfer performance and parameter efficiency of 16 popular convolutional architectures on a large chest X-ray dataset (CheXpert) to investigate these assumptions.
- This is a paper from Andrew Ng’s research group.
Outline
- CheXtransfer Results
- Truncated Models Results
1. CheXtransfer Results
1.1. Summary

- Leftmost: Scatterplot and best-fit line for 16 pretrained models showing no relationship between ImageNet and CheXpert performance.
- Second Left: CheXpert performance relationship varies across architecture families much more than within.
- Second Right: Average CheXpert performance improves with pretraining.
- Rightmost: Models can maintain performance and improve parameter efficiency through truncation of final blocks.
1.2. Details

There is no monotonic relationship between ImageNet and CheXpert performance without pretraining (Spearman 𝜌 = 0.08) or with pretraining (Spearman 𝜌 = 0.06).

- The logarithm of the model size has a near linear relationship with CheXpert performance when no pretraining (Spearman 𝜌 = 0.79).
- However once with pretraining, the monotonic relationship is weaker (Spearman 𝜌 = 0.56).

Most models benefit significantly from ImageNet pretraining. Smaller models tend to benefit more than larger models (Spearman 𝜌 = −0.72).
2. Truncated Models Results

- Networks compose of repeated blocks, each block is constructed with convolutional layers.
- Performance is evaluated by truncating the blocks and appending the classification layer (Global average pooling then fully connected layer) at the end.
For all four model families, truncating the final block leads to no significant decrease in CheXpert AUC but can save 1.4× to 4.2× the parameters.
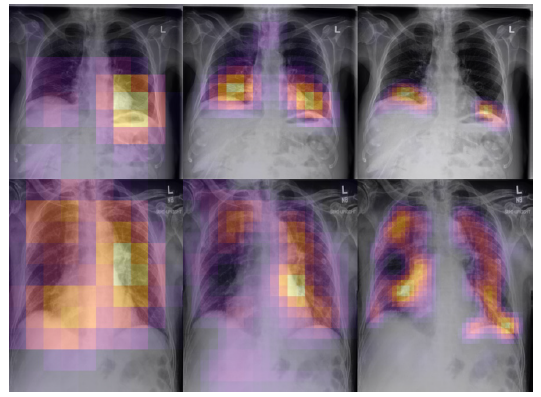
- As an additional benefit, architectures that truncate pooling layers will also produce higher-resolution class activation maps by Grad-CAM.
- The higher-resolution class activation maps (CAMs) may more effectively localize pathologies with little to no decrease in classification performance. In clinical settings, improved explainability through better CAMs may be useful for validating predictions and diagnosing mispredictions.
One of the topics that Prof. Andrew Ng focuses, is the data-centric issue in AI. Here, by collaborating with radiologists, the data-centric issue is studied in the field of medical X-ray imaging.
Reference
[2021 CHIL] [CheXtransfer]
CheXtransfer: Performance and Parameter Efficiency of ImageNet Models for Chest X-Ray Interpretation
1.8. Biomedical Image Classification
2017 [ChestX-ray8] 2019 [CheXpert] [Rubik’s Cube] 2020 [VGGNet for COVID-19] [Dermatology] [ConVIRT] [Rubik’s Cube+] 2021 [MICLe] [MoCo-CXR] [CheXternal] [CheXtransfer]
