Brief Review — CNN and Bidirectional GRU-Based Heartbeat Sound Classification Architecture for Elderly People
CNN+BiGRU for Heart Sound Classification
CNN and Bidirectional GRU-Based Heartbeat Sound Classification Architecture for Elderly People
CNN+BiGRU, by Nirma University, Dartmouth College, University of Petroleum and Energy Studies, Technical University of Gheorghe Asachi, University Politehnica of Bucharest, National Research and Development Institute for Cryogenic and Isotopic Technologies — ICSI Rm. Vâlcea
2023 MDPI Mathematics (Sik-Ho Tsang @ Medium)Heart Sound Classification
2013 … 2023 [2LSTM+3FC, 3CONV+2FC] [NRC-Net] [Log-MelSpectrum+Modified VGGNet] [CNN+BiGRU] [CWT+MFCC+DWT+CNN+MLP]
==== My Other Paper Readings Are Also Over Here ====
- Convolutional neural network and bi-directional gated recurrent unit (CNN + BiGRU) attention-based architecture is proposed for the classification of heartbeat sound.
Outline
- Prior Arts
- Dataset, Augmentation & Preprocessing
- Proposed CNN+BiGRU
- Results
1. Prior Arts

- The above shows a lot of Prior Arts. Hope I can read them later.
2. Dataset, Augmentation & Preprocessing
2.1. General Architecture

- Application Layer shows the application areas, which include hospitals, government offices, ambulances, nursing homes, and gymnasiums.
- Data Layer, deals with data acquisition in real time, such as a digital or analog stethoscope, electro-mechanical film (EMFi) transducer, smartphones.
- Intelligence Layer is the layer which includes the deep learning model.
2.2. CirCor Dataset
CirCor dataset is used. Authors have not read data for a patient with no clear description of the murmur’s presence or absence. This leads to acquiring audio clips with 499 murmur and 2508 normal recordings, with 3007 recordings obtained from 942 patients in total.
- To deal with this class imbalance problem, undersampling is performed. With the undersampling, 489 recordings for the murmur class and 489 randomly selected recordings for the normal class are used.
- This dataset is then divided into training and testing data by a ratio of 70:30.
2.3. Data Augmentation
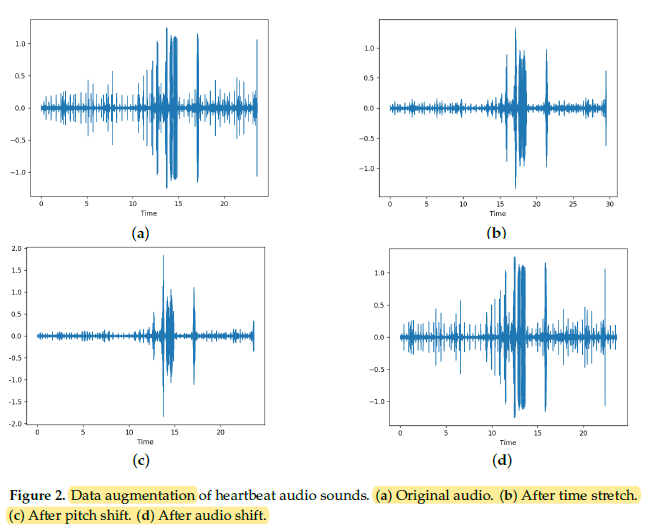
Time stretching, pitch shifting, and audio shifting are applied. The total training data becoming 3 times the original size of 684 clips.
- Time Stretching: If the selected rate is less than 1, the audio is slowed down and if it is greater than 1, it is sped up. It is randomized uniformly between 0.8 and 1.2. The probability of application of this transformation is set to 0.5.
- Pitch Shift: is done by changing the sound pitch up or down without altering the tempo. Semitones are randomly selected in the range of -4 to +4. The probability of application of this transformation is set to 0.5.
- Audio Shifting: is applied to shift the audio samples forward or backward, with or without any rollover. The shifting is done within a fraction of -0.5 to +0.5. The probability of application of this transformation is set to 0.5.
2.4. Preprocessing

Data pre-processing involves filtering, normalizing, and downsampling the given audio signal.
- Filtering is performed on a given audio dataset to remove noise generated due to various environmental conditions during the recording process.
- Normalization is done to improve the training process by normalizing every category of heartbeat sound in the range of +1 to -1.
- Down-sampling of the signal is accomplished to a sampling rate of 22,050, along with a bandpass filter having a frequency range of 30 to 1200 Hz.
3. Proposed CNN+BiGRU
3.1. Feature Extraction
- Authors try to train it directly on the raw time series data it would lead to a vanishing gradient problem and a very long training time.
- Another alternative is to employ a chromagram [56], which is also a feature extraction method like MFCC, but which leads to unstable training.
Hence, MFCC is the preferred feature extractor.
3.2. CNN+BiGRU Model
- The DL model consisting of CNN + BiGRU with an attention model for inference on the audio sample.
- In the input layer, MFCCs with 70 coefficients are used as input.
- Before passing the GRU units to work upon the time series data, 2D convolution layers are applied with batch normalization and Dropout with a probability of 0.3 to prevent overfitting and leaky ReLU with a parameter value of 0.3 as the non-linearity.
- The CNN layer is expected to extract key MFCC coefficients and provide to the BiGRU layers in the form of time series data [57,58].
- From this data, the BiGRU learns important features and passes them to another BiGRU layer via a Dropout (to prevent overfitting) to provide final features extracted from MFCCs to a feed-forward neural network (FFNN) to make the prediction. The FFNN’s first layer uses tanh activation, whereas the second layer uses sigmoid activation as it is a binary classification problem.
4. Results
4.1. Proposed Method Performance

The overall validation accuracy of the proposed CNN+BiGRU with an attention model is superior to the other models.
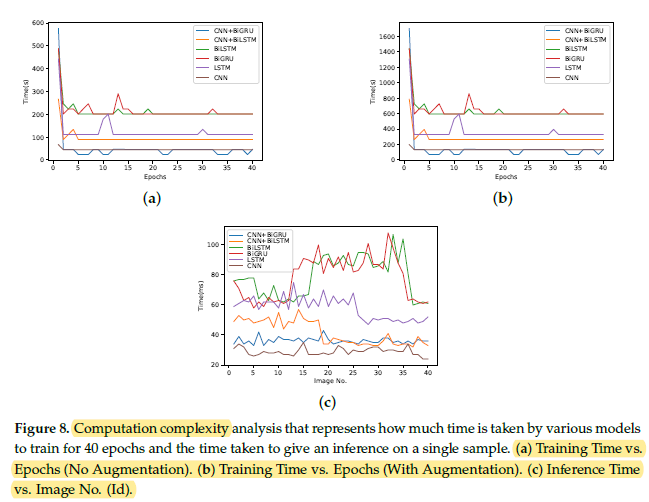
The proposed architecture has much less computational time complexity for training than other models.
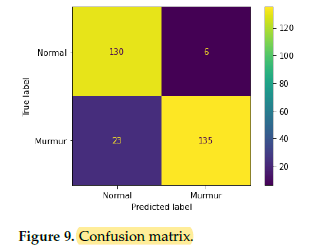
4.2. Ablation Studies
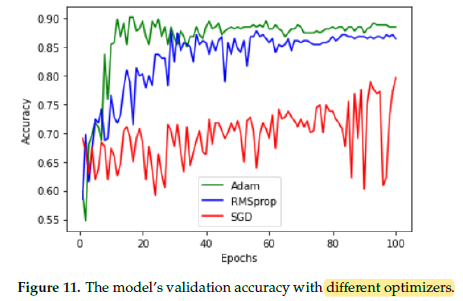
Adam [60] optimizer produces the best results.
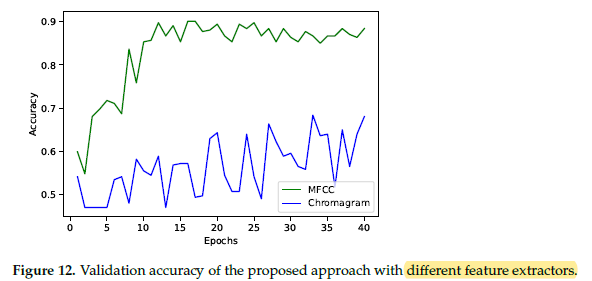
Training with MFCC is very stable and converges quickly.
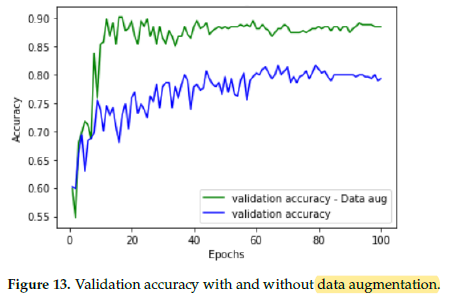
Data augmentation improves the validation accuracy to a great extent a and helps combat overfitting.
