[Paper] Dropout: A Simple Way to Prevent Neural Networks from Overfitting (Image Classification)
A Very Famous Regularization Approach to Prevents Co-Adaptation so as to Reduce Overfitting
In this paper, Dropout: A Simple Way to Prevent Neural Networks from Overfitting (Dropout), by University of Toronto, is shortly presented.
- The key idea is to randomly drop units (along with their connections) from the neural network during training.
- This prevents units from co-adapting too much.
This is firstly appeared in 2012 arXiv with over 5000 citations. And it is used in AlexNet (2012 NIPS), with over 73000 citations and got the first place in 2012 ImageNet competition. Finally, it is published in 2014 JMLR with over 23000 citations. (Sik-Ho Tsang @ Medium)
Outline
- Dropout
- Experimental Results
1. Dropout
1.1. General Idea

- Left: When using the neural network at the left, if there are some neurons which are quite strong, the network will depend those neurons too much making others weak and unreliable.
- Right: An example of a thinned net produced by applying dropout to the network on the left. Crossed units have been dropped.
1.2. Training & Testing

- Left: At training time, it has p that it will not be used.
- Right: At test time, the weights of this network are scaled-down versions of the trained weights.
- If a unit is retained with probability p during training, the outgoing weights of that unit are multiplied by p at test time as shown in the above figure.
It is conjectured that co-adaptations do not generalize to unseen data.
Dropout prevents co-adaptation by making the presence of other hidden units unreliable.
2. Experimental Results
2.1. MNIST

- All dropout nets use p = 0.5 for hidden units and p = 0.8 for input units.
- The best performing neural networks without dropout obtains 1.6% error rate. With dropout the error reduces to 1.35%.
- With other kinds of improvement such as using ReLU, more neurons, max-norm constraint, Maxout, 0.94% error rate is achieved.

- The same architectures trained with and without dropout have drastically different test errors as seen as by the two separate clusters of trajectories. Dropout gives a huge improvement across all architectures.
2.2. Street View House Numbers (SVHN)
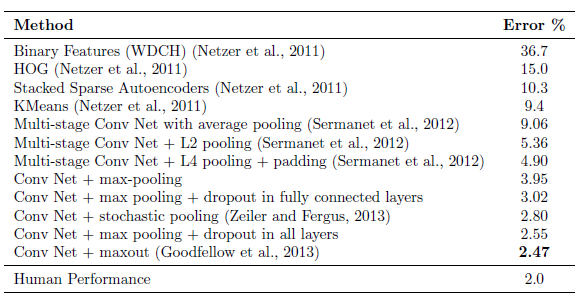
- The best architecture is LeNet which has three convolutional layers followed by 2 fully connected hidden layers. All hidden units were ReLUs.
- The best performing convolutional nets that do not use dropout achieve an error rate of 3.95%.
- Adding dropout only to the fully connected layers reduces the error to 3.02%.
- Adding dropout to the convolutional layers as well further reduces the error to 2.55%.
Dropout in the lower layers still helps because it provides noisy inputs for the higher fully connected layers which prevents them from overfitting.
- Even more gains can be obtained by using Maxout units.
2.3. CIFAR

- The best Conv Net without dropout obtains an error rate of 14.98% on CIFAR-10.
- Using dropout in the fully connected layers reduces that to 14.32% and adding dropout in every layer further reduces the error to 12.61%.
- Error is further reduced to 11.68% by replacing ReLU units with Maxout units.
- On CIFAR-100, dropout reduces the error from 43.48% to 37.20% which is a huge improvement.
2.4. ImageNet

- AlexNet based on convolutional nets and dropout won the ILSVRC-2012 competition.
- While the best methods based on standard vision features achieve a top-5 error rate of about 26%, convolutional nets with dropout achieve a test error of about 16%.
There are also results for speech and test datasets, as well as detailed studies and discussions about Dropout. Please feel free to read the paper especially 2014 JMLR one.
(I’ve just felt that it’s seems missing something if I write stories about other regularization methods later on, though I think many people have already known about Dropout…)
References
[2012 arXiv] [Dropout]
Improving neural networks by preventing co-adaptation of feature detectors
[2014 JMLR] [Dropout]
Dropout: A Simple Way to Prevent Neural Networks from Overfitting
Image Classification
1989–1998: [LeNet]
2012–2014: [AlexNet & CaffeNet] [Maxout] [Dropout] [NIN] [ZFNet] [SPPNet]
2015: [VGGNet] [Highway] [PReLU-Net] [STN] [DeepImage] [GoogLeNet / Inception-v1] [BN-Inception / Inception-v2]
2016: [SqueezeNet] [Inception-v3] [ResNet] [Pre-Activation ResNet] [RiR] [Stochastic Depth] [WRN] [Trimps-Soushen]
2017: [Inception-v4] [Xception] [MobileNetV1] [Shake-Shake] [Cutout] [FractalNet] [PolyNet] [ResNeXt] [DenseNet] [PyramidNet] [DRN] [DPN] [Residual Attention Network] [IGCNet / IGCV1] [Deep Roots]
2018: [RoR] [DMRNet / DFN-MR] [MSDNet] [ShuffleNet V1] [SENet] [NASNet] [MobileNetV2] [CondenseNet] [IGCV2] [IGCV3] [FishNet] [SqueezeNext] [ENAS] [PNASNet] [ShuffleNet V2] [BAM] [CBAM] [MorphNet] [NetAdapt] [mixup] [DropBlock]
2019: [ResNet-38] [AmoebaNet] [ESPNetv2] [MnasNet] [Single-Path NAS] [DARTS] [ProxylessNAS] [MobileNetV3] [FBNet]
