Brief Review — CrossFormer++: A Versatile Vision Transformer Hinging on Cross-scale Attention
Uses PGS & ACL, Improves CrossFormer
CrossFormer++: A Versatile Vision Transformer Hinging on Cross-scale Attention,
CrossFormer++, by Zhejiang University, Zhejiang Lab, Hong Kong University of Science and Technology, and Tencent,
2023 arXiv v1 (Sik-Ho Tsang @ Medium)Image Classification
1989 … 2023 [Vision Permutator (ViP)] [ConvMixer]
==== My Other Paper Readings Are Also Over Here ====
- Two issues that affect Vision Transformers’ performance are found, i.e., the enlarging self-attention maps and amplitude explosion.
- CrossFormer++ is proposed by incorporating with progressive group size (PGS) paradigm and amplitude cooling layer (ACL) into CrossFormer.
- (Please kindly read CrossFormer for more details.)
Outline
- CrossFormer++
- Results
1. CrossFormer++
1.1. Progressive Group Size (PGS) Paradigm

- CrossFormer is used to compute its average attention maps.
- Specifically, the attention maps of a certain group can be represented as:

- where B, H, G represent batch size, number of heads, and group size, respectively.
- The attention map of a token at image b, head h, and position (i, j) is represented as:

- For the token at position (i, j), the attention map averaged over batches and multi-heads is:

As shown in the figure above, the attention regions gradually expand from shallow to deep layers. For example, tokens in the first two stages mainly attend to regions of size 4 × 4 around themselves. The results indicate that tokens from shallow layers prefer local dependencies, while those from deep layers prefer global attentions.
Thus, PGS paradigm, i.e., adopting a smaller group size in shallow layers to lower the computational budget and a larger group size in deep layers for global attention.
1.2. Amplitude Cooling Layer (ACL)

- As shown in Fig. 5 above, for a CrossFormer-B model, the amplitude increases greatly as the block goes deeper. In particular, the maximal output for the 22nd block becomes over 3000.
The extreme value makes the training process unstable and hinders the model from converging.
It is conjectured that all block’s outputs are gradually accumulated through the residual connections in the model.
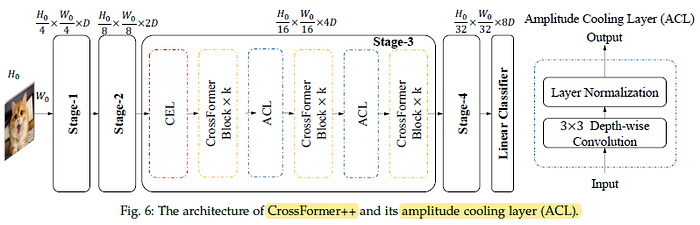
- Similar to CEL, ACL does not use any residual connection, is inserted.
It only consists of a depth-wise convolution layer and a normalization layer. ACL can also cool down the amplitude.
1.3. Model Variants
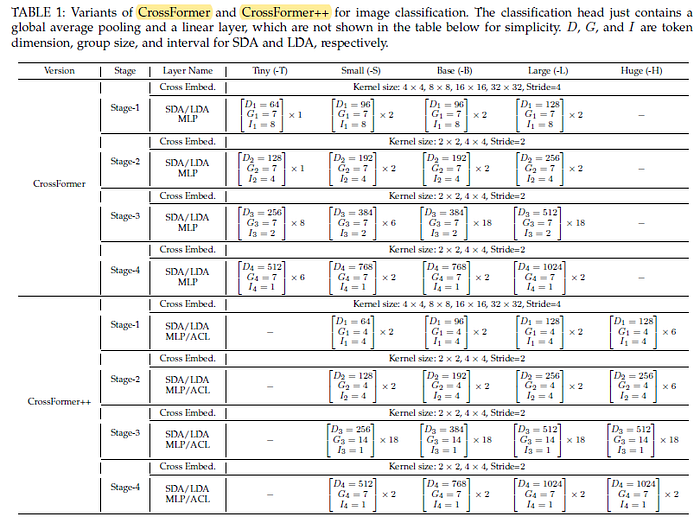
- CrossFormer++ focuses more on larger models, so the “Tiny (-T)” version is ignored, and a new “Huge (-H)” version is constructed.
2. Results
2.1. ImageNet

Compared with CrossFormer, CrossFormer++ brings about 0.8% accuracy improvement in average.
- For example, CrossFormer-B achieves 83.4% in accuracy, while CrossFormer++-B reaches 84.2% with a negligible extra computational budget.
Moreover, CrossFormer++ outperforms all existing Vision Transformers with similar parameters and a comparable computational budget.
2.2. MS COCO
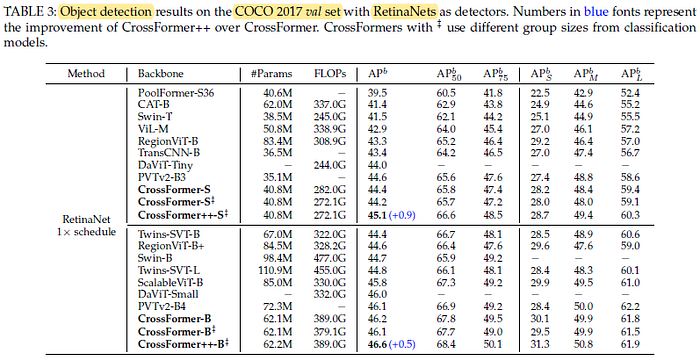
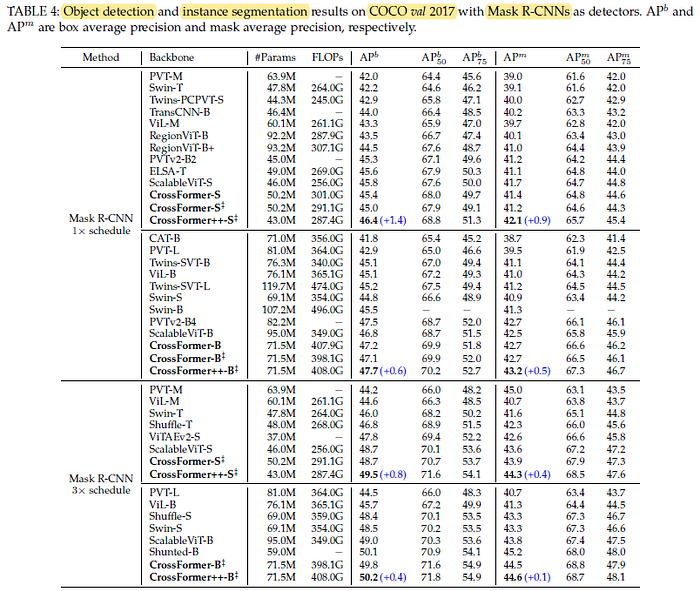
CrossFormer++ surpasses CrossFormer by at least 0.5% AP and outperforms all existing methods.
- Further, its performance gain over the other architectures gets sharper when enlarging the model, indicating that CrossFormer++ enjoys greater potentials.
2.3. ADE20K
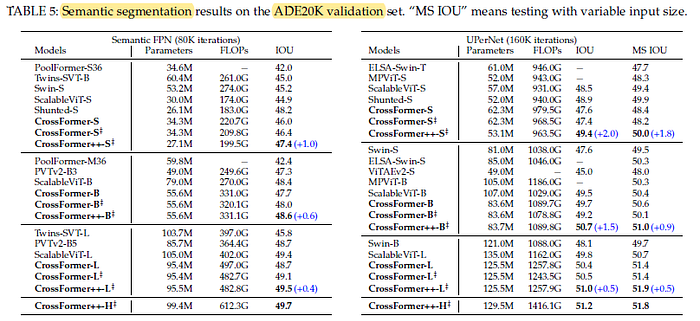
CrossFormer++ shows a more significant advantage than CrossFormer when using a more powerful segmentation head.
- CrossFormer++S outperforms CrossFormer-S by 1.0 AP when using Semantic FPN (47.4 vs. 46.4), while outperforms 2.0 AP when using UPerNet as the segmentation head.
- (Please feel free to read the paper directly for ablation studies. The paper seems to be submitted to journal according to the draft format.)
