Review — CrossFormer: A Versatile Vision Transformer Hinging on Cross-scale Attention
CrossFormer: A Versatile Vision Transformer Hinging on Cross-scale Attention,
CrossFormer, by Zhejiang University, Tencent, and Columbia University,
2022 ICLR, Over 110 Citations (Sik-Ho Tsang @ Medium)Image Classification
1989 … 2023 [Vision Permutator (ViP)] [ConvMixer]
==== My Other Paper Readings Are Also Over Here ====
- CrossFormer are designed, with Cross-scale Embedding Layer (CEL), Long Short Distance Attention (LSDA), and Dynamic Position Bias module (DPB) proposed.
- CEL blends each embedding with multiple patches of different scales, providing the self-attention module itself with cross-scale features.
- LSDA splits the self-attention module into a short-distance one and a long-distance counterpart, which not only reduces the computational burden but also keeps both small-scale and large-scale features in the embeddings.
- Dynamic position bias module (DPB) is further proposed to make the Relative Position Bias (RPB) more flexible.
Outline
- CrossFormer
- Results
1. CrossFormer

1.1. Overall Architecture
- CrossFormer also employs a pyramid structure, which naturally splits the Transformer model into four stages.
- Each stage consists of a cross-scale embedding layer (CEL) and several CrossFormer blocks.
- A CEL receives last stage’s output (or an input image) as input and generates cross-scale embeddings. In this process, CEL (except that in Stage-1) reduces the number of embeddings to a quarter while doubles their dimensions for a pyramid structure.
- Then, several CrossFormer blocks, each of which involves long short distance attention (LSDA) and dynamic position bias (DPB), are set up after CEL.
- A specialized head follows after the final stage accounting for a specific task.
1.2. Cross-scale Embedding Layer (CEL)

- The first CEL, which is ahead of Stage-1, receives an image as input, then sampling patches using four kernels of different sizes. The stride of four kernels is kept the same.
- CELs for Stage-2/3/4 use two different kernels (2×2 and 4×4). Further, to form a pyramid structure, the strides of CELs for Stage-2/3/4 are set as 2×2 to reduce the number of embeddings to a quarter.
1.3. CrossFormer Block

- Each CrossFormer block consists of a long short distance attention module (LSDA, which involves a short distance attention (SDA) module or a long distance attention (LDA) module) and a multilayer perceptron (MLP).
1.3.1. (a) & (b) Long Short Distance Attention Module (LSDA)
- The self-attention module into two parts: short distance attention (SDA) and long distance attention (LDA).
- (a) SDA: Every G×G adjacent embeddings are grouped together. G=3 in the example.
- (b) LDA: With input of size S×S, the embeddings are sampled with a fixed interval I. Red/Yellow blocks are grouped for attention, as in the example.
1.3.2. (c) Dynamic Position Bias (DPB)
- Relative Position Bias (RPB): indicates embeddings’ relative position by adding a bias to their attention. Formally, the LSDA’s attention map with RPB becomes:
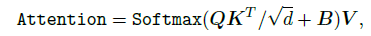
- The image/group size is restricted.
- (c) DPB: An MLP-based module called Dynamic Position Bias (DPB) to generate the relative position bias dynamically:
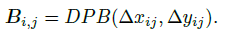
- Its non-linear transformation consists of three fully-connected layers with Layer Normalization and ReLU.
1.4. Model Variants
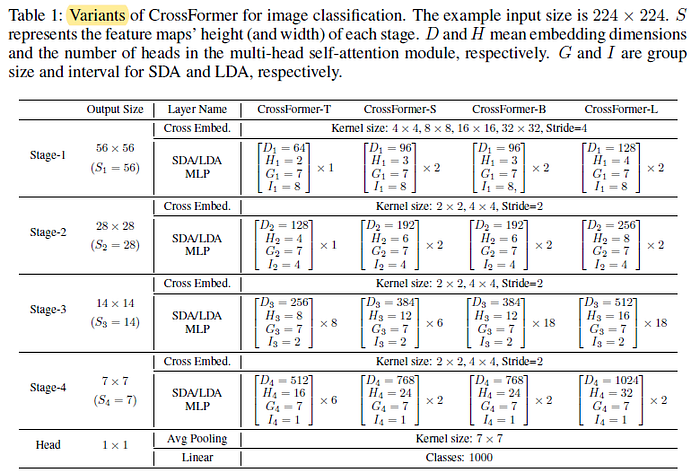
- CrossFormer’s four variants (-T, -S, -B, and -L for tiny, small, base, and large, respectively) are designed with different values of D, H, G, I.
2. Results
2.1. ImageNet

CrossFormer achieves the highest accuracy with parameters and FLOPs comparable to other state-of-the-art vision Transformer structures.
In specific, CrossFormer outperforms strong baselines DeiT, PVT, and Swin at least absolute 1.2% in accuracy on small models.
2.2. MS COCO
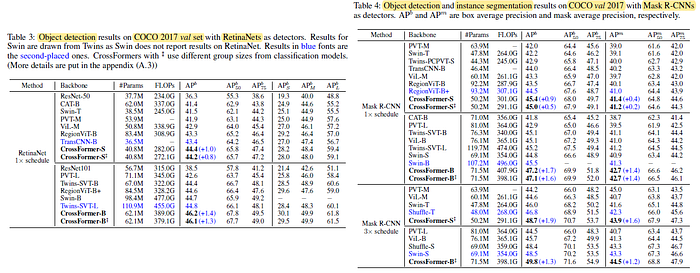
CrossFormer outperforms all the others on both tasks (detection and segmentation) with both model sizes (small and base).
Further, CrossFormer’s performance gain over the other architectures gets sharper when enlarging the model.
2.3. ADE20K

Similar to object detection, CrossFormer exhibits a greater performance gain over the others when enlarging the model.
For example, CrossFormer-T achieves 1.4% absolutely higher on IOU than Twins-SVT-B. CrossFormer-B achieves 3.1% absolutely higher on IOU than Twins-SVT-L.
2.4. Ablation Studies
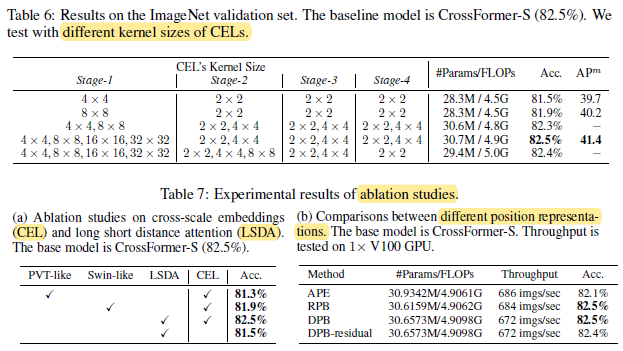
- Table 6: Cross-scale embeddings can bring a large performance gain, yet the model is relatively robust to different choices of kernel size.
- Table 7a: CrossFormer outperforms PVT-like and Swin-like self-attention mechanisms at least absolute 0.6% accuracy (82.5% vs. 81.9%).
- Table 7b: Both DPB and RPB outperform APE for absolute 0.4% accuracy. Residual connection does not help.
- Further, DPB achieves the same accuracy (82.5%) as RPB with an ignorable extra cost. Yet, DPB is more flexible than RPB and applies to variable image size or group size.
