Review — Vision Permutator: A Permutable MLP-Like Architecture for Visual Recognition
ViP, 2023 TPAMI, for A Good Start of New Year 2023
Vision Permutator: A Permutable MLP-Like Architecture for Visual Recognition,
Vision Permutator (ViP), by Nankai University, National University of Singapore, Sea AI Lab,
2023 TPAMI, Over 60 Citations (Sik-Ho Tsang @ Medium)Image Classification
1989–2021 … 2022 [ConvNeXt] [PVTv2] [ViT-G] [AS-MLP] [ResTv2] [CSWin Transformer] [Pale Transformer] [Sparse MLP] [MViTv2] [S²-MLP]
==== My Other Paper Readings Are Also Over Here ====
- Vision Permutator (ViP), a MLP-like network, is proposed, which separately encodes the feature representations along the height and width dimensions with linear projections.
- This allows ViP to capture long-range dependencies and meanwhile avoid the attention building process in Transformers. The outputs are then aggregated in a mutually complementing manner to form expressive representations.
Outline
- Vision Permutator (ViP)
- Experimental Results
1. Vision Permutator (ViP)

1.1. Overall Architecture
- ViP takes an image of size 224×224 as input and uniformly splits it into a sequence of image patches (14×14 or 7×7). All the patches are then mapped into linear embeddings (or called tokens) using a shared linear layer.
- Tokens are fed into a sequence of Permutators to encode both spatial and channel information. The resulting tokens are finally averaged along the spatial dimensions, followed by a fully-connected layer for class prediction.
1.2. Permutator
- Permutator consists of two components: Permute-MLP and Channel-MLP.
- The Channel-MLP module shares a similar structure to the feed forward layer in Transformers that comprises two fully-connected layers with a GELU activation in the middle.
- For spatial information encoding, ViT proposes to separately process the tokens along the height and width dimensions.
- Given an input C-dim tokens X, the permutator is formulated as:

- where LN refers to LayerNorm. The output Z will serve as the input to the next Permutator block until the last one.
1.3. Permute-MLP

- Permute-MLP consists of three branches, each of which is in charge of encoding information along either the height, or width, or channel dimension.
- C: The channel information encoding is simple as we only need a fully-connected layer with weights WC to perform a linear projection with respect to the input X, yielding XC.
- H: To encode the spatial information along the height dimension (H), given the input X of size H×W×C, it is first split into S segments along the channel dimension, yielding {XH1, XH2, …, XHS}, then concatenated along the channel dimension as the output of the permutation operation.
- Next, a fully-connected layer with weight WH of size C×C is connected to mix the height information.
- To recover the original dimensional information to X, we only need to perform the height-channel permutation operation once again, outputting XH.
- W: Similar operation along the width dimension.
- Then, the summation of all the token representations from the three branches is fed into a new fully-connected layer to attain the output of the Permute-MLP layer ^X:
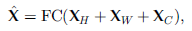
- where FC denotes a fully-connected layer with weight WP.
1.4. Weighted Permute-MLP
- For the above equation, it just simply added together.
- To have the weighting, ResNeSt split attention can be used.
1.5. Model Variants
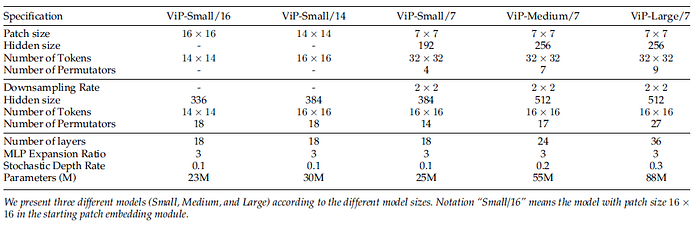
- Three different versions of Vision Permutator (ViP) are designed, denoted as ‘ViP-Small’, ‘ViP-Medium’, and ‘ViP-Large’ respectively, according to their model size.
- For all models, the MLP expansion ratio is set to 3 following T2T-ViT.
- Positional encoding is NOT used.
2. Experimental Results
2.1. ImageNet

- The proposed ViP-Small/7 model with only 25M parameters achieves top-1 accuracy of 81.5%.
This result is already better than most of the existing MLP-like models and comparable to the best one gMLP-B which has 73M parameters, far more than the proposed ViP.
- Similar improvement can also be observed on ImageNet-ReaL and ImageNet-V2, reflecting that ViP can better prohibit overfitting compared to other models.
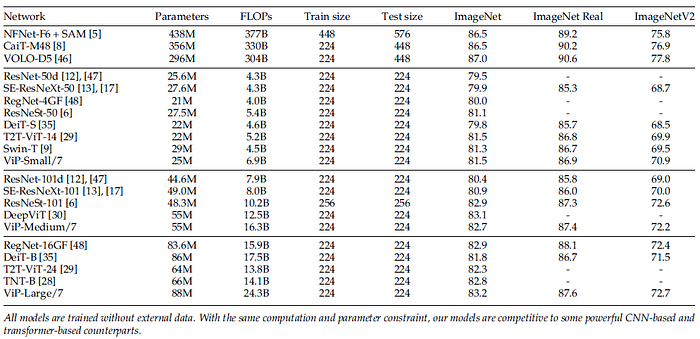
Compared with classic CNNs, like ResNets, SE-ResNeXt, and RegNet, Vision Permutator with similar model size constraint receives better results.
Compared to some Transformer-based models, such as DeiT, T2T-ViT, and Swin Transformers, ViPs are also better.
- However, there is still a large gap between recent state-of-the-art CNN- and Transformer-based models, such as NFNet, CaiT and VOLO [46]. There is still a large room for improving MLP-like models.
2.2. Ablation Study

- Authors further reduce the initial patch size from 14×14 to 7×7.
Compared to ViP-Small/14, ViP-Small/7 adopts 4 Permutators to encode fine-level token representations (with 32×32 tokens). Such a slight modification can largely boost the performance and reduce the number of learnable parameters.

Increasing the number of layers and hidden dimension yields better results for our Vision Permutator.
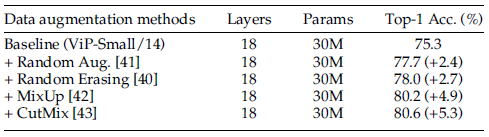
Data augmentation is extremely important in training Vision Permutator.
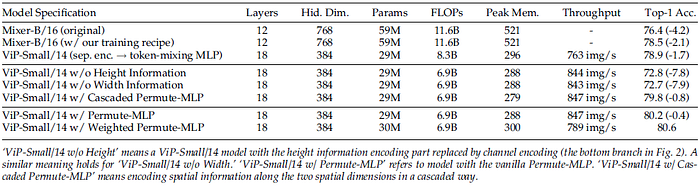
Discarding either height information encoding or width information encoding leads to worse performance (80.2% versus 72.8% or 72.7%).
The weighted Permute-MLP using ResNeSt split attention can further improve the performance from 80.2% to 80.6%.
2.3. Transfer Learning

- The proposed Vision Permutator performs well in transfer learning to small classification datasets.
Authors mentioned one of the future works is to have applications in downstream tasks, such as object detection and semantic segmentation.
