Review — ADE20K: Semantic Understanding of Scenes Through the ADE20K Dataset (Semantic Segmentation)
ADE20K dataset is constructed as the benchmarks for scene parsing and instance segmentation

In this story, Semantic Understanding of Scenes Through the ADE20K Dataset, (ADE20K), by The Chinese University of Hong Kong, Massachusetts Institute of Technology, Peking University, and University of Toronto, is briefly reviewed. In this paper:
- ADE20K dataset is constructed as the benchmarks for scene parsing and instance segmentation.
- The effect of synchronized batch normalization is evaluated and it is found that a reasonably large batch size is crucial for the semantic segmentation performance.
This is a paper in 2019 IJCV over 500 citations. (Sik-Ho Tsang @ Medium)
Outline
- ADE20K Dataset
- Scene Parsing Benchmark
1. ADE20K Dataset

1.1. Annotation Details
- The dataset was annotated by a single expert annotator, providing extremely detailed and exhaustive image annotations.
- On average, the annotator labeled 29 annotation segments per image, compared to 16 segments per image labeled by external annotators (like workers from Amazon Mechanical Turk). (AMT is a platform to pay persons for annotations.)
- Furthermore, the data consistency and quality are much higher than that of external annotators.
- Images come from the LabelMe (Russell et al. 2008), SUN datasets (Xiao et al. 2010), and Places (Zhou et al. 2014) and were selected to cover the 900 scene categories defined in the SUN database.
- The worker provided three types of annotations: object and stuff segments with names, object parts, and attributes. All object instances are segmented independently.
- Segments in the dataset are annotated via polygons.
- In order to convert the annotated polygons into a segmentation mask, these are sorted in every image by depth layers. e.g.: Background classes like sky or wall are set as the farthest layer.
- Object parts are associated with object instances. Note that parts can have parts too, e.g.: The rim is a part of a wheel, which in turn is part of a car.
1.2. Number of Annotated Images

- After annotation, there are 20,210 images in the training set, 2000 images in the validation set, and 3000 images in the testing set.
- There are in total 3169 class labels annotated, among which 2693 are object and stuff classes while 476 are object part classes.
- In the dataset, 76% of the object instances have associated object parts, with an average of 3 parts per object.
- The class with the most parts is building, with 79 different parts. On average, 10% of the pixels correspond to object parts.
2. Scene Parsing Benchmark
2.1. Baseline Performance

- The top 150 categories ranked by their total pixel ratios in the ADE20K dataset are selected to build a scene parsing benchmark of ADE20K, termed as SceneParse150.
- Several semantic segmentation networks are evaluated: SegNet, FCN-8s, (DilatedVGG, DilatedResNet), two cascade networks, i.e. Cascade-SegNet and Cascade-DilatedNet.
- As seen, using the cascade framework, the performance is further improved. In terms of mean IoU, Cascade-SegNet and Cascade-DilatedVGG outperform SegNet and DilatedVGG by 6% and 2.5%, respectively.

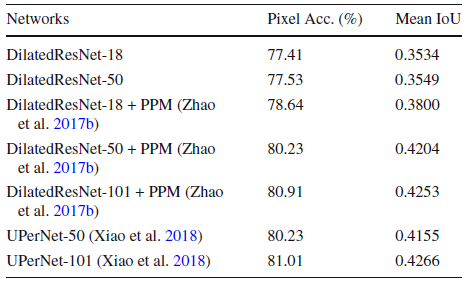
- PPM is Pyramid Pooling Module used in PSPNet, which aggregates multi-scale contextual information in the scene.
- UPerNet adopts architecture like Feature Pyramid Network to incorporate multi-scale context more efficiently.
Both PPM (PSPNet) and UPerNet, which utilizing multi-scale context has a higher accuracy.
2.2. Effect of Batch Normalization for Scene Parsing
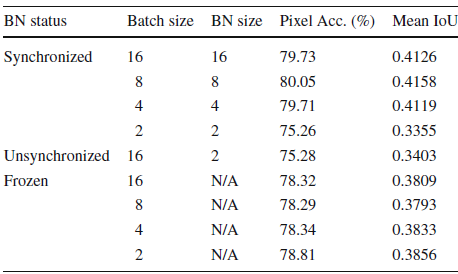
- The above results are obtained by Dilated ResNet-50 with Pyramid Pooling Module used in PSPNet.
- As shown above, a small batch size such as 2 lower the score of the model significantly by 5%. Thus training with a single GPU with limited RAM or with multiple GPUs under unsynchronized BN is unable to reproduce the best reported numbers.
- The possible reason is that the BN statics, i.e., mean and standard variance of activations may not be accurate when the batch size is not sufficient.
- The baseline framework is trained with 8 GPUs and 2 images on each GPU.
- Synchronized BN is adopted for the baseline network, i.e., the BN size should be the same as the batch size.
- Besides the synchronized BN setting, the unsynchronized BN setting and frozen BN setting are also reported. The former one means that the BN size is the number of images on each GPU; the latter one means that the BN layers are frozen in the backbone network, and removed from the PPM (in PSPNet).
Thus, a reasonably large batch size is essential for matching the highest score of the-state-or-the-art models.
2.3. Instance Segmentation Benchmark
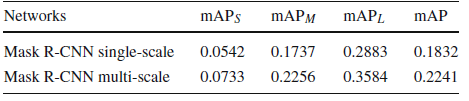
- 100 foreground object categories are selected from the full dataset, termed as InstSeg100.
- Mask R-CNN with FPN is tested.
- It is a strong baseline, giving correct detections and accurate object boundaries. Some typical errors are object reflections in the mirror.
Reference
[2019 IJCV] [ADE20K]
Semantic Understanding of Scenes Through the ADE20K Dataset
Semantic Segmentation
2015: [FCN] [DeconvNet] [DeepLabv1 & DeepLabv2] [CRF-RNN] [SegNet] [DPN]
2016: [ENet] [ParseNet] [DilatedNet]
2017: [DRN] [RefineNet] [ERFNet] [GCN] [PSPNet] [DeepLabv3] [LC] [FC-DenseNet] [IDW-CNN] [DIS] [SDN] [Cascade-SegNet & Cascade-DilatedNet]
2018: [ESPNet] [ResNet-DUC-HDC] [DeepLabv3+] [PAN] [DFN] [EncNet]
2019: [ResNet-38] [C3] [ESPNetv2] [ADE20K]
2020: [DRRN Zhang JNCA’20]
