Brief Review — Deep attention-based neural networks for explainable heart sound classification
CNN+Attention

Deep attention-based neural networks for explainable heart sound classification
CNN+Attention, by University of Augsburg, Leibniz University Hannover, Beijing Institute of Technology, University of Hong Kong — Shenzhen Hospital, Shenzhen University General Hospital, Wenzhou Medical University First Affiliated Hospital, The University of Tokyo, Imperial College London
2022 J. MLWA, Over 20 Citations (Sik-Ho Tsang @ Medium)Heart Sound Classification
2013 … 2022 [CirCor Dataset] [CNN-LSTM] [DsaNet] [Modified Xception] [Improved MFCC+Modified ResNet] [Learnable Features + VGGNet/EfficientNet] [DWT + SVM] [MFCC+LSTM] [DWT+ 1D-CNN] 2023 [2LSTM+3FC, 3CONV+2FC] [NRC-Net]
==== My Other Paper Readings Are Also Over Here ====
- Deep neural network with an attention mechanism is proposed for for classifying 3 categories of heart sounds, i. e., normal, mild, and moderate/severe.
Outline
- Proposed CNN+Attention
- Results
1. Proposed CNN+Attention
1.1. HSS Dataset

- HSS dataset is used.
First, a series of 936 × 64 log Mel spectrograms are extracted from the audio signals in the HSS corpus using a Hamming window of 256 samples width with 50% overlap and 64 Mel frequency bins.
Then, the Log Mel spectrogram is fed into a CNN model.
- During training, all models are learnt with an Adam optimiser and a batch size of 32.
1.2. Proposed CNN+Attention Model

Backbone: The CNN models consist of 4 convolutional layers with output channels 64, 128, 256, and 256. Each convolutional layer is followed by a local max-pooling layer with 2 × 2 kernels.
- (If you know SENet concept well, you can read the above figure and skip the below passages for quick read.)
Attention at Head: The global attention pooling consists of two components: the top one has a convolution layer, and the bottom one is comprised of a convolutional layer and a normalisation operation.
- In the top component, the convolutional layer is set up with 1 × 1 kernels and an output channel of the class number.
- In the bottom component, the convolutional layer has the same hyperparameters as that in the top one.
- Afterwards, to calculate the weight tensor of 𝒉𝑀, an activation function is employed to rectify the values of the feature map from the convolutional layer in the bottom component. Both softmax and sigmoid functions can rectify the values into the interval of [0, 1].
- Further, normalisation is applied to the rectified feature map 𝐹 using:
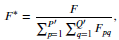
- where 𝐹∗ is the output of the bottom component.
- Next, the feature map from the top component is multiplied with 𝐹∗, leading to an element-wise product, which is then summed to a vector with the length equalling the number of classes.
- Finally, log softmax is employed to fit the chosen negative log-likelihood (NLL) loss function.
1.3. RNN+Attention Model
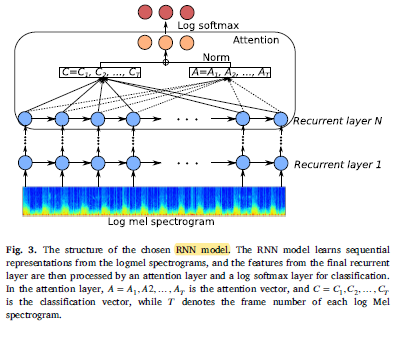
- Both LSTM–RNN and GRU–RNN models contain 3 recurrent layers with output dimensions 256, 1 024, and 256.
- In a similar way to the attention mechanism in CNNs, the left component (corresponding to the top one in Fig. 2) herein contains a one-dimensional convolutional layer, in which the kernel size is 1 and the output channel number is equal to the class number, leading to a classification tensor 𝐶 of size 𝑇 × 𝑐𝑙𝑎𝑠𝑠 𝑛𝑢𝑚𝑏𝑒𝑟.
- The right component (corresponding to the bottom one in Fig. 2) consists of a convolutional layer with the same setting as that in the left component and a normalisation procedure.

- Model architecture details are shown above.
2. Results
2.1. Settings
- To investigate the effect of the balanced training set on the DL models, authors compare the results on the original imbalanced HSS data and balanced HSS training data produced by a random upsampling strategy aiming at class balance.
- The unweighted average recall (UAR) is employed as the main evaluation metric:
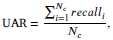
2.2. Ablation Studies
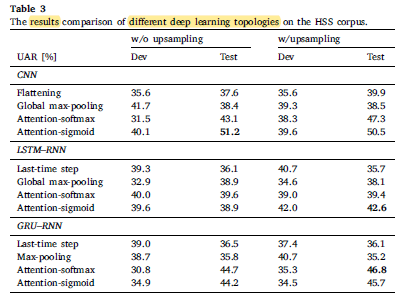
Attention-based mechanism can significantly improve the corresponding DL models in recognising heart sound.
- The best result (a UAR of 51.2%) is achieved by the CNN model with an attention mechanism (using a sigmoid function).
- For RNN, the best results for LSTM–RNN and GRU–RNN are 42.6% UAR and 46.8% UAR, respectively.
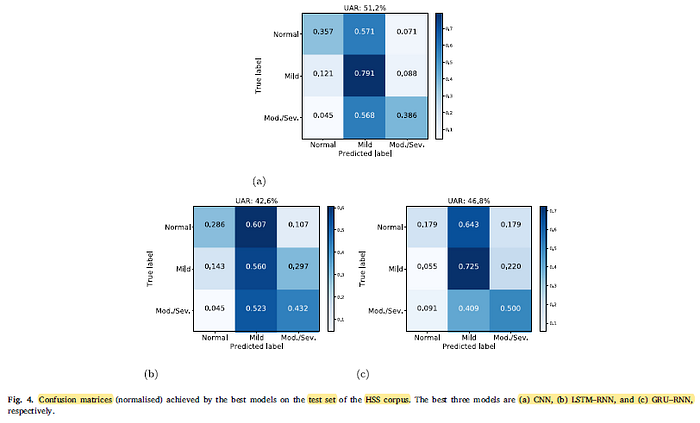
The best CNN and GRU–RNN models outperform the best LSTM–RNN model in recognising the ‘Mild’ type of heart sounds.
- For all the three models, both the ‘Normal’ and ‘Mod./Sev.’ types of heart sounds are incorrectly recognised as the ‘Mild’ type of heart sounds.

The area under the ROC curve (AUC) of the CNN is the highest.
2.3. SOTA Comparisons
The upsampling strategy can slightly improve the performances of the best RNN models.
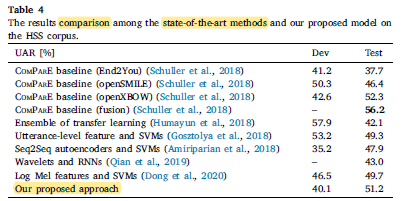
Compared to other state-of-the-art studies, the proposed method can perform better than most performances achieved by single models (cf. Table 4).
- Notably, the best performance 56.2% on the test set is achieved by the ConParE baseline with fusion methods, indicating fusion of multiple models is helpful to improve the performance. As the aim of this paper is to verify the effectiveness of attention and explain the attention models, the single models are used for comparison rather than embedding multiple models.
