Brief Review — Heart Sound Classification Using Wavelet Analysis Approaches and Ensemble of Deep Learning Models
WST+1D-CNN and CST+2D-CNN Ensemble
Heart Sound Classification Using Wavelet Analysis Approaches and Ensemble of Deep Learning Models
WST+1D-CNN and CST+2D-CNN Ensemble, by Chosun University
2023 MDPI Appl. Sci. (Sik-Ho Tsang @ Medium)Phonocardiogram (PCG)/Heart Sound Classification
2013 … 2023 [2LSTM+3FC, 3CONV+2FC] [NRC-Net] [Log-MelSpectrum+Modified VGGNet] [CNN+BiGRU] [CWT+MFCC+DWT+CNN+MLP] [LSTM U-Net (LU-Net)] [DL Overview] [MFCC + k-NN / RF / ANN / SVM + Grid Search] [Long-Short Term Features (LSTF)]
==== My Other Paper Readings Are Also Over Here ====
- Wavelet scattering transform (WST) and continuous wavelet transform (CWT) are extracted as the features to input 1D-convolutional neural network (CNN) and 2D-CNN respectively.
- The final classification result is obtained from the ensemble of 1D-CNN and 2D-CNN.
Outline
- WST+1D-CNN and CST+2D-CNN Ensemble
- Results
1. WST+1D-CNN and CST+2D-CNN Ensemble

1.1. Segmentation

- To perform signal segmentation, each dataset is read, the division time interval of the original PCG signal is set, and the division is automatically performed using MATLAB’s ‘for’ loop so that the divided signals do not overlap.
- The minimum signal of the PhysioNet/CinC 2016 Challenge Dataset was 5.31 s, cut into 5-s segments and stored, and signals shorter than 5 s were not used.
- For PASCAL dataset, 3 s intervals are used.
1.2. Feature Extraction

- WST is used as input features to 1D-CNN.
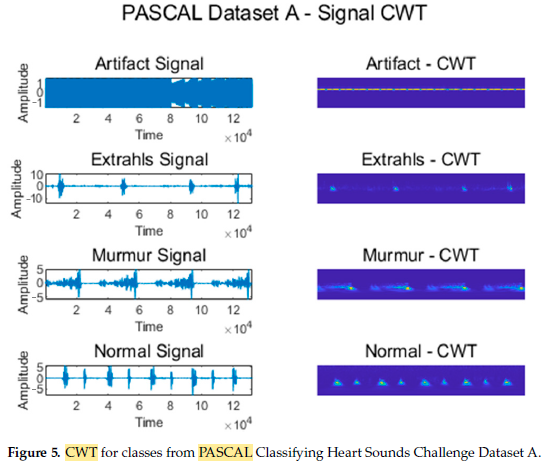
- CWT is used as input features to 2D-CNN.
1.3. 1D-CNN and 2D-CNN Models
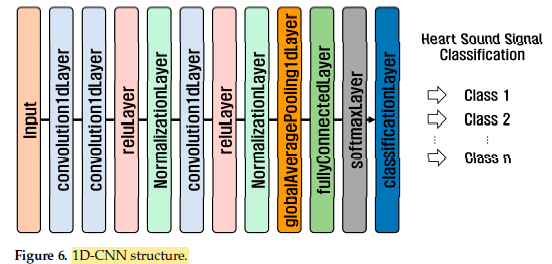
- The structure of a 1D-CNN consists of an input layer, convolution layer, activation function, pooling layer, flatten layer, fully connected layer, and output layer.
- For 2D-CNN, pretrained GoogleNet, ResNet50, and ResNet101 are used.
1.4. Ensemble
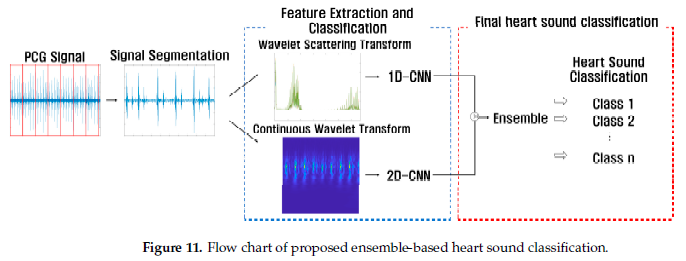
- The final soft labels from 1D-CNN and 2D-CNN are combined to be the final prediction.
2. Results

The ensemble of 1D-CNN and 2D-CNN outperforms the sole 1D-CNN and the sole 2D-CNN.
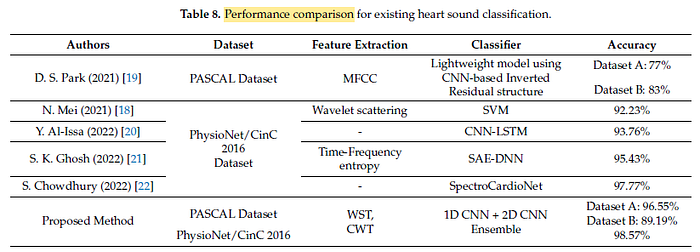
The ensemble accuracy of 1D-CNN and 2D-CNN is improved over the accuracy of existing feature extraction methods and deep learning-based heart sound classification.
