Brief Review — Heartbeat Sound Signal Classification Using Deep Learning
LSTM on PASCAL Dataset-B
4 min readNov 4, 2023
Heartbeat Sound Signal Classification Using Deep Learning
LSTM MDPI J. Sensors’19, by Khwaja Fareed University of Engineering and Information Technology, Yeungnam University, Kunsan National University
2019 MDPI J. Sensors (Sik-Ho Tsang @ Medium)Heart Sound Classification
2013 [PASCAL] 2018 [RNN Variants] [SVM, DNN, kNN] 2023 [2LSTM+3FC, 3CONV+2FC] [NRC-Net]
==== My Other Paper Readings Are Also Over Here ====
- PASCAL Dataset-B contains 3 categories Normal, Murmur and Extra-systole heartbeat sound.
- In the purposed framework, the noise is removed from the heartbeat sound signal by applying the band filter. After that the size of the sampling rate of each sound signal is fixed. Then down-sampling techniques are applied to get more discriminant features and the dimension of the frame rate is also reduced.
- Finally, LSTM is trained on the preprocessed signal.
Outline
- Proposed Approach
- Results
1. Proposed Approach
1.1. PASCALDataset-B Dataset

- PASCAL Dataset-B collected from a clinical trial in hospitals using a digital stethoscope (DigiScope)
- This Dataset-B contains 461 samples subdivided into three groups, i.e., Normal, Murmur and Extra-systole.
- Each sample of Dataset-B carries 4000 sampling frequency rates i.e., file 1 contains total sample 26,551 (6.6 s), file 2 contains total samples 38,532 (9.6 s).

- Figure 3 shows the normal sound wave with a precise shape of lub dub that has no noise.
- In murmur sound wave, showed a noise between lub to dub or dub to lub and extra-systole has a different shape like a lub-lub dub or lub dub-dub as appearing in Extra-systole sound wave.

- The corresponding spectrogram is also shown.

- A summary of prior arts, which work on PASCAL dataset.
1.2. Preprocessing, Training and Testing

- First of all, the Dataset-B is split into two sets with a ratio of 70 and 30 percent training and test data.
- Then, the pre-processing techniques are applied to eliminate the noise by applying a band-pass filter (50–800 Hz frequency).
- After that, the size of the heartbeat sound signal is fixed by converting sampling frames into a 50,000 frame for each heartbeat sound file.
- Then, down-sampling techniques are applied to reduce the sampling frame rate 50,000 to 782 frames of the heartbeat sound signal by using decimate techniques.
- Later, the classification algorithm is applied for training, i.e., Decision Tree (DT), Random Forest (RF), Linear Support Vector Classifier (LSVC), Multi-Layer Perceptron (MLP) and Recurrent Neural Network (RNN).
- Finally, the trained model obtained from the training phase is used to predict the heartbeat sound signal.
- Some of the intermediate results are shown below.
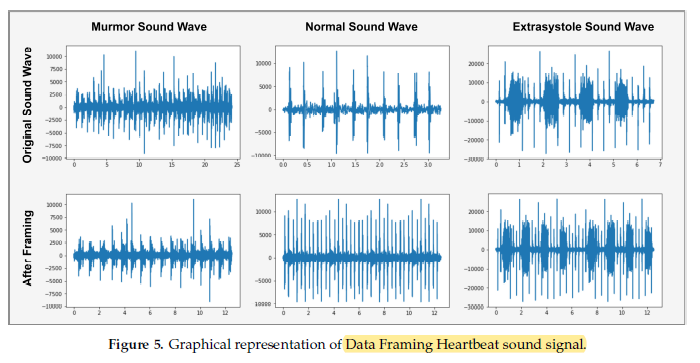
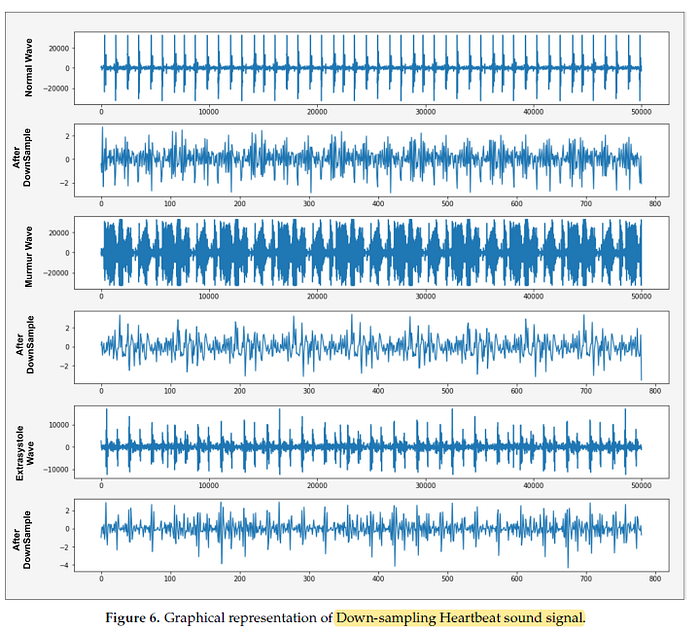
1.3. Proposed LSTM
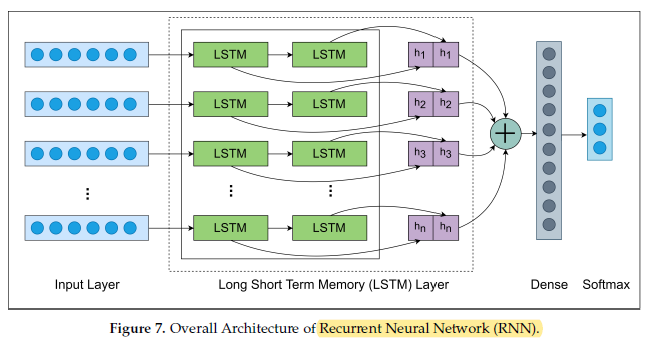
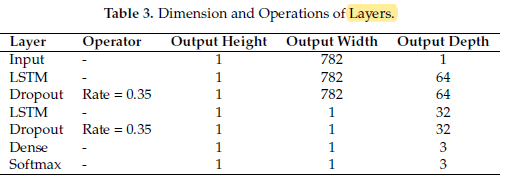
- The proposed RNN (Recurrent Neural Network) architecture applied in this research that consists of various layers such that Input, LSTM, Dropout, Dense and Softmax layer.
2. Results
- The objective of this study is to classify different heartbeat signals automatically.
- Dataset-B is converted into two datasets that consist of two different times i.e., 27.8-s and 12.5-s. Each sample of 27.8-s datasets contains 111,468 frames and 12.5-s dataset contains 50,000 frames.
- (But how they are split into train/test set, it is not so clear in the paper.)


LSTM-based RNN model obtains the highest accuracy.

Increasing the Dropout rate increases the accuracy and decreases the loss. 0.35 is the ideal Dropout rate that gives the best results in the proposed model.
