Brief Review — Learning Representations from Heart Sound: A Comparative Study on Shallow and Deep Models
ML & DL Model Study on Heart Sounds Shenzhen (HSS) Dataset

Learning Representations from Heart Sound: A Comparative Study on Shallow and Deep Models
ML & DL Model Study on HSS, by Ministry of Education (Beijing Institute of Technology), Beijing Institute of Technology, The University of Tokyo, Shenzhen University General Hospital, Technical University of Munich, Wenzhou Medical University First Affiliated Hospital, Imperial College London
2024 SPJ Cyborg Bionic Syst. (Sik-Ho Tsang @ Medium)Phonocardiogram (PCG)/Heart Sound Classification
2013 … 2023 … [CTENN] [Bispectrum + ViT] 2024 [MWRS-BFSC + CNN2D]
==== My Other Paper Readings Are Also Over Here ====
- On HSS Dataset, the tasks are redefined and a comprehensive investigation on shallow and deep models is made in this study.
- First, the heart sound recording is segmented into shorter recordings (10 s), which makes it more similar to the human auscultation case.
- Second, the classification tasks are redefined. Besides using the 3 class categories (normal, moderate, and mild/severe) adopted in HSS, a binary classification task is added in this study, i.e., normal and abnormal.
Outline
- HSS Dataset & Tasks
- ML Model Study
- DL Model Study
- Benchmarking Results
- Limitations
1. HSS Dataset & Tasks

- All of the original audio recordings in HSS were segmented into 10-s-based long clips with 5-s neighboring overlaps. Totally, 170 subjects are participated.
- All are recorded via an electronic stethoscope from 4 locations of the body.
- There are 2 subtasks, i.e., Task 1: Classification of normal, mild, and moderate/severe heart sounds; Task 2: Classification of normal, and abnormal (which includes the labels of mild or moderate/severe) heart sounds.
2. ML Model Study
2.1. Classic ML Models

- At the first step, low-level descriptors (LLDs) will be extracted from the audio signals.
- Then, the ComParE feature set LLDs are obtained using Statistical Functionals or Bag-of-Audio-Words (BoAW) Approach as below.
- Finally, SVM is used.
2.1.1. Statistical Functionals
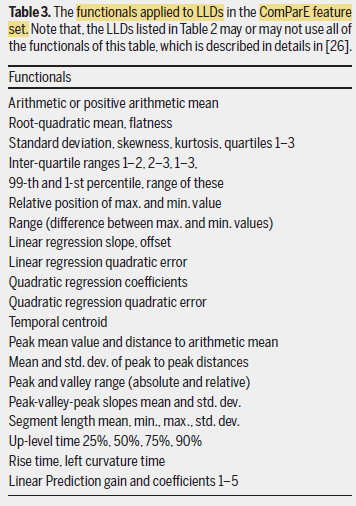
- The statistical functionals (func.), containing the mean, standard deviation, extremes, etc., are calculated from a given period of one audio clip.
The default func. configuration in the ComParE feature set is used as above, which results in 6,373 features by applying func. to the LLDs and their first delta values.
- Finally, SVM is used.
2.1.2. Bag-of-Audio-Words (BoAW) Approach
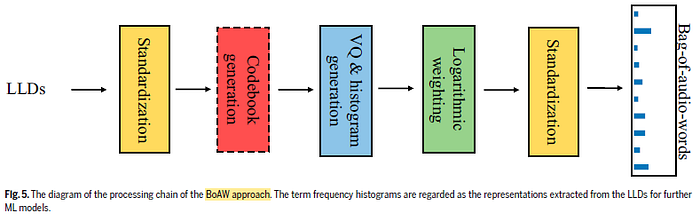
- The bag-of-audio-words (BoAW) approach was derived from the concept of bag-of-words.
- When calculating the histograms, each LLD/delta is assigned to the 10 audio words from the codebook having the lowest Euclidean distance.
- In this study, both BoAW representations from the LLDs and their deltas are concatenated.
- Finally, SVM is used.
3. DL Model Study
- 3 typical DL methods, i.e., the deep spectrum transfer learning method (see Fig. 6) by using pretrained DL models, recurrent sequence-to-sequence autoencoders (S2SAE), and end-to-end (E2E) learning models.
3.1. Deep Spectrum Transfer Learning
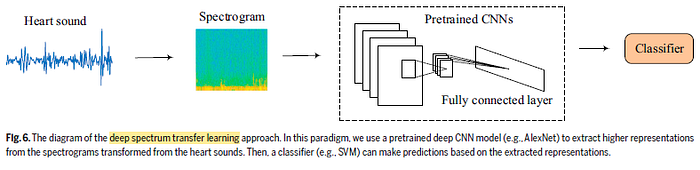
- In this method, heart sound signals are firstly transformed into Mel-spectrograms (128 Mel frequency bands are computed) using a Hanning window with 32-ms width and 16-ms overlap.
- Then, the spectrograms are fed into pretrained deep convolutional neural networks.
- Finally, the activations of the “avg_pool” later of the network are extracted as the higher representations for building the ML model (SVM in this study).
- For the pretrained CNNs, ResNet-50, VGG-16, VGG-19, AlexNet, and GoogLeNet, are evaluated.
3.2. Recurrent S2SAEs
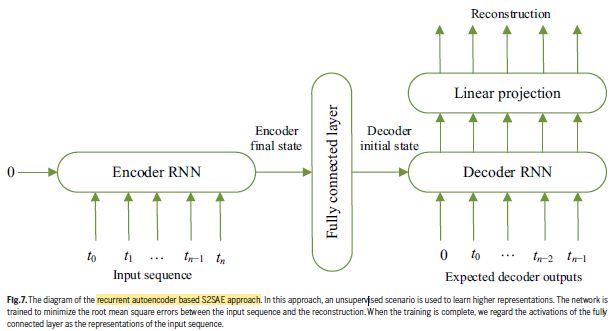
- First, Mel-scale spectrograms are generated from the raw heart sound.
- Then, power levels are clipped below certain predefined thresholds in those spectrograms to eliminate some background noise.
- Then, in an unsupervised scenario, i.e., without any labels, a distinct recurrent S2SAE is trained on each of those sets of spectrograms.
- Finally, the learnt representations of a spectrogram are concatenated to be the feature vector for the corresponding instance.
3.3. End-to-end (E2E) Learning
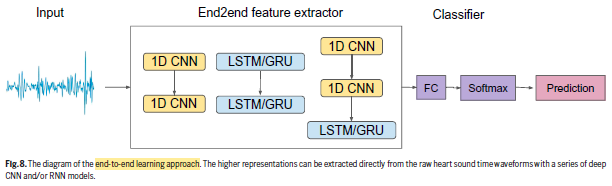
- The E2E model utilizes a series of CNNs and/or recurrent neural networks (RNNs) to extract higher representations directly from the raw heart sound audio waveforms.
- (However, it seems that only some simple/shallow CNNs and RNNs are used here.)
4. Benchmarking Results

We can see that, for both Task 1 and Task 2, the ComParE feature set-based models dominate the best performances.
- A late fusion (by majority vote) of the best 4 models reaches a comparable performance. For Task 1, the best fusion model yields to the best single model (UAR: 47.2% versus 48.8%). For Task 2, the best fusion model has a very slight improvement compared to the best single model (UAR: 58.7% versus 58.6%).
5. Limitations
- The extreme data imbalance characteristic is still the first challenge for limiting the current performances of all the models.
- Secondly, fundamental studies on heart sound feature analysis are lacking. More advanced signal processing should be investigated such as tunable-Q wavelet transformation [55], scaled spectrogram, and tensor decomposition [56].
- Thirdly, the big gap between the performances on the dev and the test sets should be overcome.
- Last but not least, more attentions and contributions should be attracted to this field.
