Brief Review — Heart Sound Classification Network Based on Convolution and Transformer
Convolution and Transformer Encoder Neural Network (CTENN)
Heart Sound Classification Network Based on Convolution and Transformer
CTENN, by Nanjing University of Posts and Telecommunications, and Nation-Local Joint Project Engineering Laboratory of RF Integration & Micropackage
2023 MDPI J. Sensors (Sik-Ho Tsang @ Medium)Phonocardiogram (PCG)/Heart Sound Classification
2013 … 2023 [2LSTM+3FC, 3CONV+2FC] [NRC-Net] [Log-MelSpectrum+Modified VGGNet] [CNN+BiGRU] [CWT+MFCC+DWT+CNN+MLP] [LSTM U-Net (LU-Net)] [DL Overview] [MFCC + k-NN / RF / ANN / SVM + Grid Search] [Long-Short Term Features (LSTF)] [WST+1D-CNN and CST+2D-CNN Ensemble]
==== My Other Paper Readings Are Also Over Here ====
- Convolution and Transformer Encoder Neural Network (CTENN) is proposed, which simplifies preprocessing, automatically extracting features using a combination of a one-dimensional convolution (1D-Conv) module and a Transformer encoder.
Outline
- Convolution and Transformer Encoder Neural Network (CTENN)
- Results
1. Convolution and Transformer Encoder Neural Network (CTENN)

1.1. Preprocessing
- A fourth-order Butterworth bandpass digital filter with a passband of 25 Hz to 400 Hz was used for filtering/denoising.
- The signal is normalized by:

- The signal is downsampled to 2000 Hz.
- Finally, each wav file is divided into several fragments according to 2.5s. The segmentation is to directly cut the heart sound signal into fixed-length segments without detection. A heart sound signal cycle is approximately 0.8 s, but due to individual differences, it is set to 2.5 s, which ensures at least 1–2 heart cycle periods. To increase the amount of data, the overlap of the sliding window is set to 50%.
- 80:10:10 ratio is used for train val test split.
1.2. CTENN Model

- The network mainly consists of three modules:
The preprocessed one-dimensional heart sound sequence input is sequentially passed through the one-dimensional convolution module, the Transformer encoder, and the fully connected module and then outputs the classification result.
- The one-dimensional convolutional module contains three 1D-conv layers for feature extraction, three Maxpooling layers for data compression, and two BatchNormalization layers for normalization.
- The output of the convolutional module is a two-dimensional signal of [625×64].
- The fully connected module contains three Dense layers for data compression and classification and a GlobalAveragePooling layer for transforming multi-dimensional features into one-dimensional features.
2. Results
2.1. Datasets
- Dataset a: The 2016 PhysioNet/CinC Challenge dataset.
- Dataset b: Yaseen GitHub Dataset.
- Dataset c: Two datasets are added from PASCAL Heart Sound Classification Challenge.
2.2. SOTA Comparisons
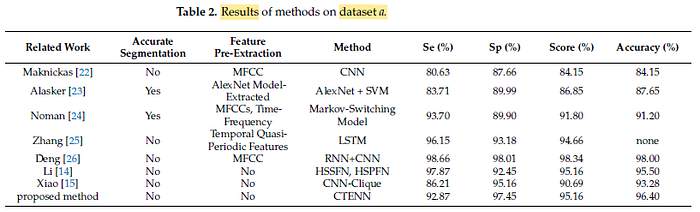
- From Table 2, we can see that the accuracy of methods [22–24] is not very high, indicating that the accuracy of segmentation has a significant impact on the classification accuracy.
Compared with the best-performing method [26], CTENN only had 0.16 less accuracy, but because CTENN did not perform feature extraction on the heart sound signal, it can be easily applied to various heart sound classification devices.
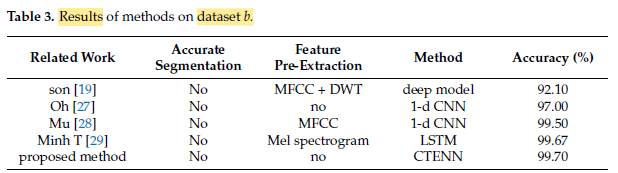
As the dataset b is balanced, the recognition accuracy of each model is excellent, and the difference between the classification methods does not have a significant impact on the recognition rate, as shown in Table 3.

The proposed method still achieved an accuracy of 95.7%, which is the highest among these methods, with a high score of 94.25, indicating that our proposed method is very stable.