Brief Review — UL2R, U-PaLM: Transcending Scaling Laws with 0.1% Extra Compute

Transcending Scaling Laws with 0.1% Extra Compute
UL2R, U-PaLM, by Google
2022 arXiv v2 (Sik-Ho Tsang @ Medium)LM Tuning / Prompting
2020 [Human Feedback Model] 2021 [T5+LM, Prompt Tuning] 2022 [GPT-3.5, InstructGPT] [LoRA] [Chain-of-Thought Prompting] [T0] [FLAN] [Flan-PaLM] 2023 [LIMA]
==== My Other Paper Readings Are Also Over Here ====
- UL2Restore (UL2R) is proposed, which is a method to continue training a SOTA LLM (e.g., PaLM) on a few more steps with UL2’s mixture-of-denoiser objective. UL2R substantially improves existing language models and their scaling curves with almost negligible extra computational costs and no new sources of data.
- U-PaLM model family of 8B, 62B, and 540B scales, is established by training PaLM with UL2R. An approximately 2× computational savings rate is achieved.
- Later, U-PaLM is further instruction-finetuned as Flan-U-PaLM.
Outline
- UL2Restore (UL2R)
- U-PaLM
- Results
1. UL2Restore (UL2R)
The key idea is UL2R or UL2Restore to continue training an existing causal language model with a mixture of new objectives — specifically, the UL2 training objective mixture.
- This restoration is expected to only cost roughly 0.1% to 1% of the original training FLOPs and requires no new data sources, making it highly efficient and convenient.
The UL2 objective combines prefix language modeling and long-short span corruption (e.g., infilling) tasks, that can teach LLM to leverage bidirectional attention (i.e., PrefixLM) or leverage infilling-style pretraining.
2. U-PaLM
2.1. Improved Scaling Properties on Few-shot Learning

U-PaLM substantially outperforms the original PaLM models both at 8B scale and 540B scale. Note that the dotted lines represent a pathway before and after UL2R training.
- UL2R training improves the scaling curve of PaLM substantially, i.e., UL2R provides a more compute-efficient performance improvement compared to training the original PaLM models for longer with the standard causal language modeling objective.
2.2. BigBench

U-PaLM outperforms PaLM on 19 out of the 21 tasks at 540B scale.
2.3. Chain-of-Thought (CoT) Reasoning
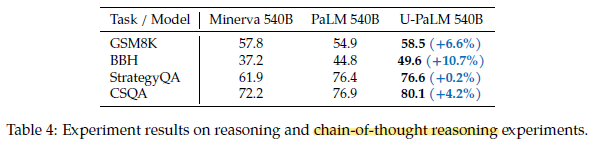
- All tasks are run with chain-of-thought (CoT) prompting.
U-PaLM 540B outperforms both PaLM 540B and Minverva 540B.
2.4. Infilling Ability
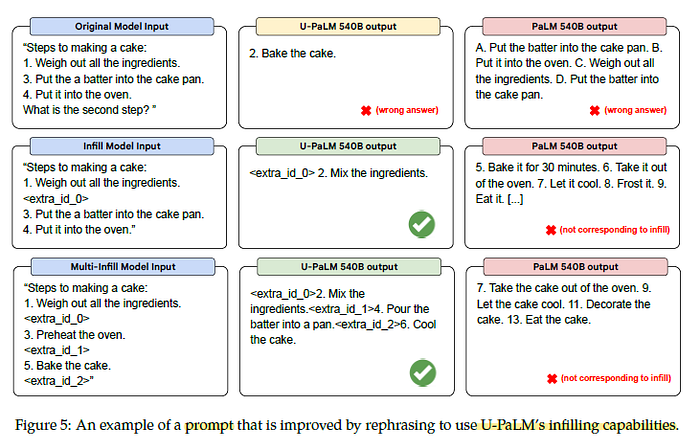
With UL2R training which uses UL2 objective, which has the infilling objective, the second and third examples demonstrate U-PaLM’s ability to infill multiple slots.
