Brief Review — T0: Multitask Prompted Training Enables Zero-Shot Task Generalization
T0, Fine-Tuned From T5 Using Multi-Task Learning
Multitask Prompted Training Enables Zero-Shot Task Generalization
T0, by Numerous Organizations
2022 ICLR, Over 500 Citations (Sik-Ho Tsang @ Medium)Language Model
1991 … 2023 [GPT-4] [LLaMA] [LIMA] [Koala] [BloombergGPT] [GLM-130B] [UL2] [PaLM 2]
==== My Other Paper Readings Are Also Over Here ====
- Can zero-shot generalization instead be directly induced by explicit multitask learning? To test this question at scale, a system is developed for easily mapping any natural language tasks into a human-readable prompted form.
- A large set of supervised datasets are converted such that each sample is with multiple prompts with diverse wording. These prompted datasets allow for benchmarking the ability of a model to perform completely held-out tasks.
- A pretrained encoder-decoder model, T5, is then fine-tuned on this multitask mixture.
Outline
- Datasets & Tasks
- Unified Prompt Format
- T0
- Results
1. Datasets & Tasks

- NLP datasets are partitioned into tasks. The term “task” is used to refer to a general NLP ability that is tested by a group of specific datasets.
Excluding non-English datasets and special domain knowledge datasets, this yields 12 tasks and 62 datasets with publicly contributed prompts as above.
- To test zero-shot generalization, All constituent datasets of four tasks are held out: natural language inference (NLI), coreference resolution, sentence completion, and word sense disambiguation.
- BIG-bench, which is a recent community-driven benchmark to create a diverse collection of difficult tasks, is also used for evaluation later on.
2. Unified Prompt Format
2.1. Multiple Prompt Formats

- A templating language and an application are developed that make it easy to convert diverse datasets into prompts.
- A prompt is defined as consisting of an input template and a target template, along with a collection of associated metadata.
- The templates are functions mapping a data example into natural language for the input and target sequences. Practically, the templates allow the user to mix arbitrary text with the data fields, metadata, and other code for rendering and formatting raw fields.
Each data example is materialized with many different prompt templates as shown above.
- To develop prompts, an interface is built for interactively writing prompts on datasets. Aan open call is put on in the research community for users to contribute prompts. 36 contributors affiliated with 24 institutions in 8 countries participated.
2.2. Public Pool of Prompts (P3)
- Finally, a set of prompts is collected: Public Pool of Prompts (P3).
- As of writing of this paper by authors, P3 contains 2073 prompts for 177 datasets (11.7 prompts per dataset on average). Prompts used in experiments are all sourced from P3 except for BIG-bench, the prompts of which are provided by its maintainers.
3. T0

- LM-adapted T5 model, referred to as T5+LM from Prompt Tuning, is used for fine-tuning.
T0: is trained on the multitask mixture as collected and described above.
T0+: is the same model with identical hyperparameters except trained on a mixture that adds GPT-3’s evaluation datasets.
T0++: further adds SuperGLUE to the training mixture (except RTE and CB), which leaves NLI and the BIG-bench tasks as the only held-out tasks.
4. Results
4.1. Generalization

T0 matches or exceeds the performance of all GPT-3 models on 9 out of 11 held-out datasets.
- Notably, neither T0 nor GPT-3 is trained on natural language inference, yet T0 outperforms GPT-3 on all NLI datasets, even though our T5+LM baseline does not.
4.2. BIG-Bench
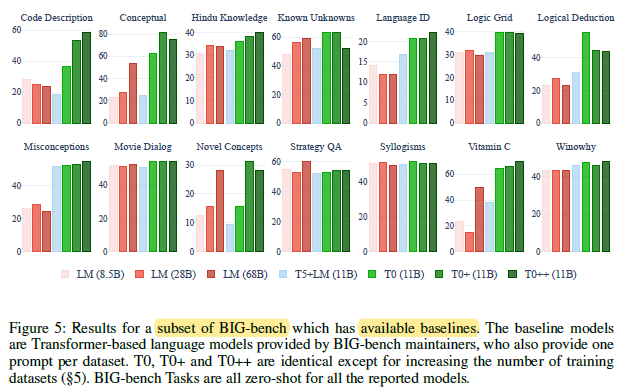
At least one of the T0 variants outperform all baseline models on all tasks except for StrategyQA.
- In most cases, the performance of the proposed models improves as the number of training datasets increases (i.e., T0++ outperforms T0+ which outperforms T0).
4.3. Further Studies
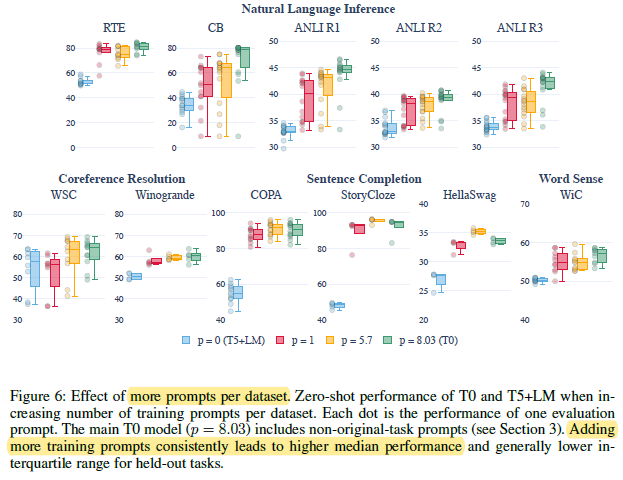
Increasing prompt numbers p from 1 to an average of 5.7 does yield additional improvement in both median (increases for 8/11 datasets) and spread (decreases for 7/11 datasets). This reinforces the hypothesis that training on more prompts per dataset leads to better and more robust generalization to held-out tasks.
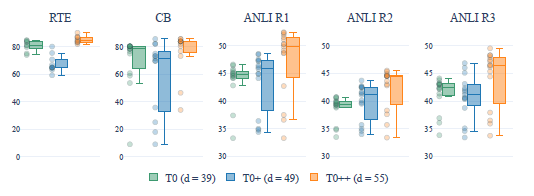
As dataset number d increases from 49 to 55, the median performance of all datasets again increases, but the spread only decreases for 2 out of 5 datasets. Although further investigation is needed, it appears that increasing d does not consistently make the model more robust to the wording of prompts.
