Brief Review — LoRA: Low-Rank Adaptation of Large Language Models
LoRA, Low-Rank LLM Fine-Tuning, Reduce Required Memory
3 min readMay 13, 2023
LoRA: Low-Rank Adaptation of Large Language Models,
LoRA, by Microsoft Corporation,
2022 ICLR, Over 280 Citations (Sik-Ho Tsang @ Medium)Language Model
1991 … 2022 [GPT-NeoX-20B] [GPT-3.5, InstructGPT] [GLM] [MT-NLG 530B] [Chinchilla] [PaLM] [AlexaTM] [BLOOM] [AlexaTM 20B] [OPT] [Switch Transformers] [LaMDA] 2023 [GPT-4]
==== My Other Paper Readings Are Also Over Here ====
- Full fine-tuning LLM, which retrains all model parameters, becomes less feasible. Using GPT-3 175B as an example — deploying independent instances of fine-tuned models, each with 175B parameters, is prohibitively expensive.
- Low-Rank Adaptation, or LoRA, is proposed, which freezes the pre-trained model weights and injects trainable rank decomposition matrices into each layer of the Transformer architecture, greatly reducing the number of trainable parameters for downstream tasks.
Outline
- LoRA
- Results
1. LoRA
1.1. Idea

- For a pre-trained weight matrix W0, its update is constrained by representing the latter with a low-rank decomposition:

- During training, W0 is frozen and does not receive gradient updates, while A and B contain trainable parameters.
- For h=W0x, the modified forward pass yields:

- A random Gaussian initialization is used for A and zero is used for B, so ΔW=BA is zero at the beginning of training.
- One of the advantages is that when deployed in production, we can explicitly compute and store W=W0+BA and perform inference as usual. No additional latency compared to other methods, such as appending more layers.
1.2. Implementation
- In the Transformer architecture, there are four weight matrices in the self-attention module (Wq, Wk, Wv, Wo) and two in the MLP module.
- LoRA only adapts the attention weights for downstream tasks and freezes the MLP modules.
For large Transformer, using LoRA reduces VRAM usage by up to 2/3.
On GPT-3 175B, using LoRA reduces the VRAM consumption during training from 1.2TB to 350GB.
2. Results

- The pre-trained RoBERTa base (125M) and RoBERTa large (355M) from the HuggingFace Transformers library is taken. DeBERTa XXL (1.5B) is also evaluated. They are fine-tuned by different fine-tuning approaches.
Using LoRA gets the best performance on GLUE at much of the time.
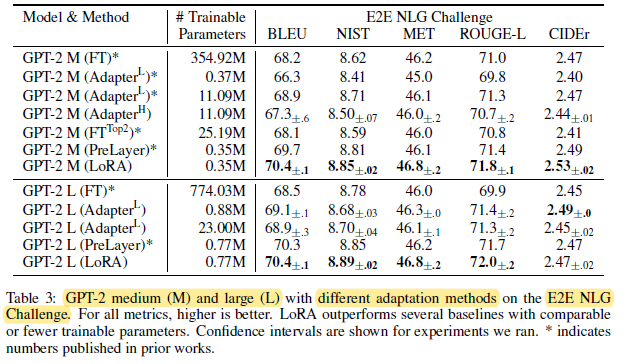
LoRA still prevails on NLG models, such as GPT-2 medium and large.

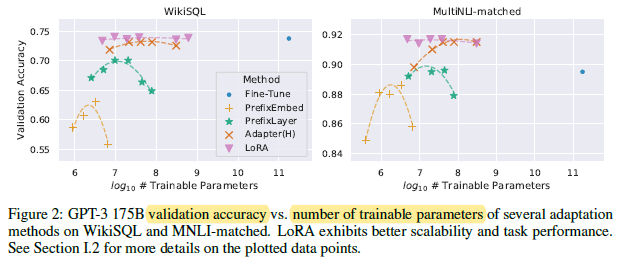
Using GPT-3, LoRA matches or exceeds the fine-tuning baseline on all three datasets.
- (This is a paper introduced by a colleague few months ago. I’ve just read it recently, lol.)
