BTS-ST: Swin Transformer Network for Segmentation and Classification of Multimodality Breast Cancer Images
BTS-ST: Swin Transformer Network for Segmentation and Classification of Multimodality Breast Cancer Images,
BTS-ST, by COMSATS University Islamabad,
2023 J. KNOSYS (Sik-Ho Tsang @ Medium)Biomedical Image Segmentation
2015 … 2022 [UNETR] [Half-UNet] [BUSIS] [RCA-IUNet] [Swin-Unet] [DS-TransUNet] [UNeXt] [AdwU-Net] 2023 [DCSAU-Net] [RMMLP]
==== My Other Paper Readings Are Also Over Here ====
- BTS-ST is proposed, which incorporates Swin-Transformer into traditional CNNs-based U-Net to improve global modeling capabilities.
- To improve the feature representation capability of irregularly shaped tumors, Spatial Interaction block (SIB) is proposed, encoding spatial knowledge in the Swin Transformer block by developing pixel-level correlation.
- Feature Compression block (FCB) is designed to prevent information loss and compress smaller-scale features in patch token down sampling of Swin Transformer.
- Finally, a Relationship Aggregation block (RAB) is developed as a bridge between dual encoders to combine global dependencies from Swin Transformer into the features from CNN hierarchically.
Outline
- BTS-ST
- Results
1. BTS-ST
1.1. Overall Architecture

- For the primary encoder, the image x is fed to ResNet-18 with half compression on the channels, with RAB used.
- For auxiliary encoder, Swin Transformer is used as backbone, with SIB and FCB used.
- For decoder, the encoding–decoding features are concatenated using skip connection layers, with convolutions and upsamling using linear interpolation, to predict the mask.
1.2. Swin Transformer Block with Spatial Interaction block (SIB)

- (For Swin Transformer, please feel free to read the story directly.)
- (a): Standard Vision Transformer block with global self-attention yet with quadratic complexity proportional to token/image size.
- (b) Swin Transformer block reduces Transformer’s global modeling capabilities due to the use of windows for self-attention. This may affect some of the cases, such as the obstacle of ground objects in breast tumor images resulting fuzzy borders that need some spatial information to be removed.
(c) Spatial Interaction block (SIB) is added in parallel to resolve the above problem.

- First, the feature z is input into a dilated convolution of 3×3 with dilation size=2, with BN and GELU. Additionally, the number of channels is decreased to c1/2 in order to lower the computational cost.
- Then, the feature map statistics in the spatial direction are then obtained by applying the global average pooling (GAP) method (horizontal and vertical):
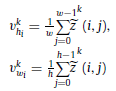
- The, they are multiplied to obtained attention map M, and dimension of M required to be expanded using 1×1 convolutional operation, with BN and GLU (or GEGLU/GELU? Need to look up the codes to confirm) to match dimensions, added back to the output of Swin Transformer block (SW-TB):
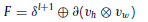
1.3. Feature Compression Block (FCB)
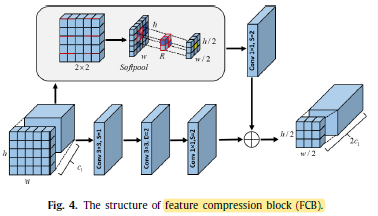
- FCB is used in the image patch token down-sampling process, which has has two branches.
- The first is a bottleneck block with dilated convolution, which by enlarging the receptive field of the convolution, extensively collects the characteristics and hierarchical information of smaller regions.
- Specifically, 1×1 conv, 3×3 dilated conv, and 1×1 conv are used to decrease the feature scale, which outputs feature maps F1.
- Another branch present SoftPool operation to achieve finer downsampling:
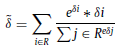
- Features after the soft-pooling operation are fed to the convolution operation to achieve the output F2:
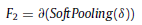
- As a result, the two branches are combined equally to provide the output L of FCB by element-wise addition:
In essence, one branch purpose is to achieve smaller-scale features, and the other branch purpose is to maintain details, both branch’s are essential.
1.4. Relational Aggregation Block (RAB)
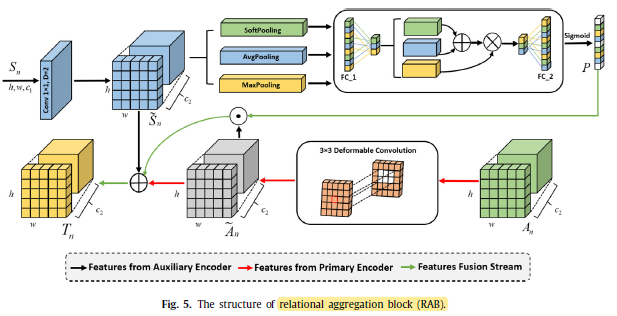
- Global features of the auxiliary encoders are embedded into the local features acquired from the primary encoder in order to highlight the significant and more representative channels from the whole feature maps.
- Three pooling techniques to get a more detailed channel dependence.
- First, average and max-pooling are applied and transferred the results to a share FC layer l1, then added together.
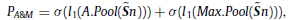
- with σ is ReLU.
- In addition, a SoftPool pooling is also applied and added to a FC layer, denoted as PS, to generate the global weight descriptor at the same time. The entire operation can be explained as follow:
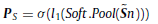
- PA&M and PS are fused together as below:
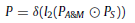
- Here, δ represent the sigmoid activation, l2 show the FC layer with incremental size, and ⊙ show element wise multiplication.
- When the refined features are connected to the residual structure, the output feature Tn of the RAB:
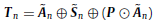
1.5. Sequential Classification Block (SCB)
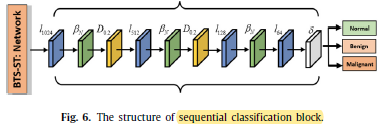
- In the classification task, the primary decoder of the proposed architecture (Fig. 2) is skipped and replaced with a sequential classification block.
- Where, l1024, l512, l128, and l64 represents the linear layers in a sequential classification block. βN is BN. δ is sigmoid. Here, two dropouts D0.7, and D0.5 are also introduced.
- The final classification results are represented as three different classes of breast tumor images, as above.
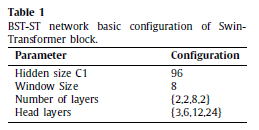
- For segmentation, Dice loss is used.
- For classification, cross entropy loss is used.
2. Results
2.1. Ablation Studies



All components contribute for higher performance.
2.2. SOTA Comparisons
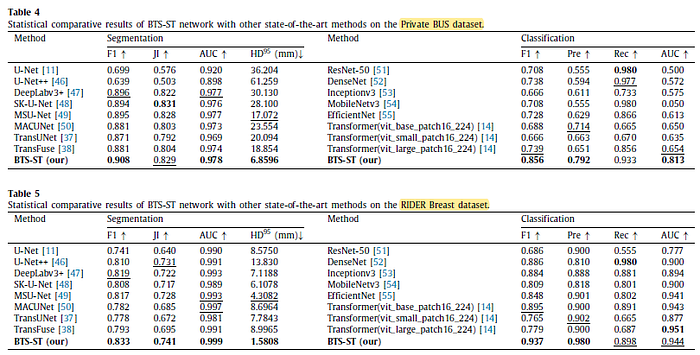

The proposed BTS-ST network achieved the highest result in most cases.
2.3. Computational Complexity

In Mean FPSs, BTS-ST achieved 24.862 FPSs, which is comparatively superior to DeepLabv3+, SK-Unet, and TransUNet.
However, U-Net achieved 57.900 Mean FPSs which is better than all other networks.
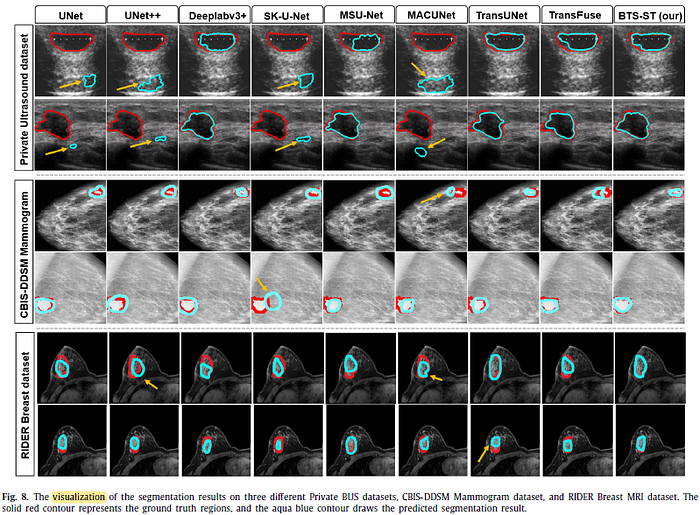
2.4. Visualizations
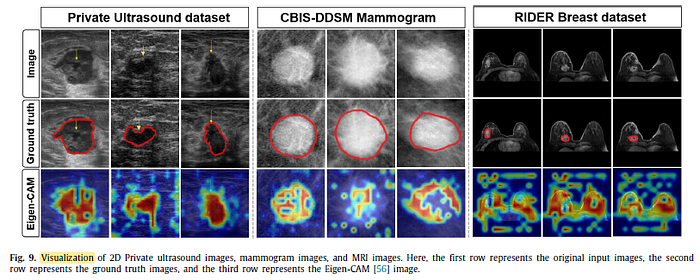
The network learns the pattern properly and makes a decision based on specific patterns.
