Review — Comparing ChatGPT and GPT‑4 performance in USMLE soft skill assessments
Comparing ChatGPT and GPT‑4 performance in USMLE soft skill assessments
ChatGPT & GPT‑4 on USMLE, by Chaim Sheba Medical Center, Tel-Aviv University, Icahn School of Medicine at Mount Sinai
2023 Nature Sci. Rep. (Sik-Ho Tsang @ Medium)Medical/Clinical NLP/LLM
2017 … 2023 [MultiMedQA, HealthSearchQA, Med-PaLM] [Med-PaLM 2] [GPT-4 in Radiology]
==== My Other Paper Readings Are Also Over Here ====
- This study aimed to evaluate ChatGPT and GPT-4 on USMLE questions involving communication skills, ethics, empathy, and professionalism.
- 80 USMLE-style questions involving soft skills, taken from the USMLE website and the AMBOSS question bank.
- A follow-up query was used to assess the models’ consistency.
Outline
- Medical Questions Datasets
- Prompt & Follow-Up Query
- Results
1. Medical Questions Datasets
- A set of 80 multiple-choice questions is designed to mirror the requirements of the USMLE examinations. This question set was compiled from two reputable sources.
1.1. USMLE
- The first source is a set of sample test questions for Step1, Step2CK, and Step3, released between June 2022 and March 2023, available at the official USMLE website.
- All example test questions are screened and 21 questions are selected that did not require scientific medical knowledge, but required communication and interpersonal skills, professionalism, legal and ethical issues, cultural competence, organizational behavior, and leadership.
1.2. AMBOSS
- The second source is AMBOSS, a widely recognized question bank for medical practitioners and students, from which an additional 59 questions are selected.
- The chosen questions include Step1, Step2CK, and Step3-type questions, dealing with ethical scenarios.
- AMBOSS also provides performance statistics from its past users, allowing a comparative analysis of LLMs’ performance against that of medical students and physicians.
2. Prompt & Follow-Up Query
2.1. Prompt
- A prompt structure is formatted, which included the question text followed by the multiple-choice answers separated by a new line.
2.2. Follow-Up Query
- Following the model’s response, a follow-up question “Are you sure?” is asked, which is allowed to evaluate the consistency and stability of the model.
- If a model changes its answer, it may indicate that it possesses some level of ‘uncertainty’ about its initial response.
3. Results
3.1. Accuracy


- ChatGPT accuracy for USMLE sample test and AMBOSS questions was 66.6% and 61%, respectively, with an overall 62.5% accuracy.
GPT-4 demonstrated superior performance, with an accuracy of 100% and 86.4% for USMLE sample test and AMBOSS questions, respectively, and an overall accuracy of 90%.
3.2. Consistency
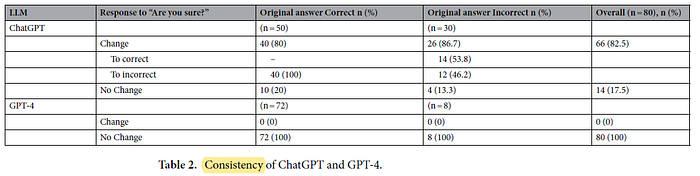
GPT-4 exhibited 0% change rate.
- In contrast, ChatGPT demonstrated a significantly higher rate of self-revision, altering its original answers 82.5% of the time when given the chance.
- When ChatGPT revised incorrect original responses, it was found that the model rectified the initial error and produced the correct answer in 53.8% of those cases.
3.3. LLM vs Human
- AMBOSS’s user statistics reported an average correct response rate of 78% by its users for the same questions.
ChatGPT showed lower accuracy than human users, 61%, while GPT-4 had a higher accuracy rate of 86.4%.
