Review — Convolutional Sequence to Sequence Learning (ConvS2S)
ConvS2S as Convolutional Network, Outperforms GNMT
In this story, Convolutional Sequence to Sequence Learning, (ConvS2S), by Facebook AI Research, is briefly reviewed. In this story:
- An architecture is proposed which is entirely based on convolutional neural networks (CNN).
- Computations can be fully parallelized during training.
- Gated linear units (GLU) eases gradient propagation and
- Each decoder layer equipped with a separate attention module.
This is a paper in 2017 ICML with over 2500 citations. (Sik-Ho Tsang @ Medium)
Outline
- ConvS2S: Network Architecture
- Experimental Results
1. ConvS2S: Network Architecture

- At the top part, it is the encoder. At the bottom part, it is the decoder.
- The encoder RNN processes an input sequence x=(x1, …, xm) of m elements and returns state representations z=(z1, ..., zm).
- The decoder RNN takes z and generates the output sequence y=(y1, …, yn) left to right, one element at a time.
To generate output yi+1, the decoder computes a new hidden state hi+1 based on the previous state hi, an embedding gi of the previous target language word yi, as well as a conditional input ci derived from the encoder output z.
- The above architecture will be mentioned below part by part.
1.1. Position Embeddings

- Input elements x=(x1,…,xm) are embedded in distributional space as w=(w1,…,wm).
- The absolute positions of input elements p=(p1,…,pm) are embedded.
- Both w and p are combined to obtain input element representations e=(w1+p1,…,wm+pm). Thus, position-dependent word embedding is used.

- Similarly at decoder, position Embeddings g are used, as shown above.
1.2. Convolutions and Residual Connections


- Both encoder and decoder networks share a simple block structure.
- Each block/layer contains a one dimensional convolution followed by a non-linearity.
- At decoder, asymmetric triangle shape means that future words are not used for convolution.
- Stacking several blocks on top of each other increases the number of input elements represented in a state. For instance, stacking 6 blocks with kernel width k=5 results in an input field of 25 elements, i.e. each output depends on 25 inputs.
1.3. Gated Linear Unit (GLU)
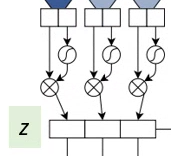
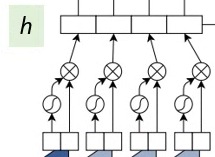
- The output of the convolution is divided into 2 parts A and B and goes through the Gated Linear Unit (GLU):
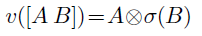
- where ⊗ is the point-wise multiplication and σ is the sigmoid function.
- (For GLU, please feel free to read GCNN if interested.)
- The output of GLU at the encoder is z.
- The output of GLU at the decoder is h.
- In addition, residual Connections are added from the input of each convolution to the output of the block (Recall that v is GLU):
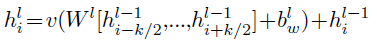
1.4. Multi-Step Attention
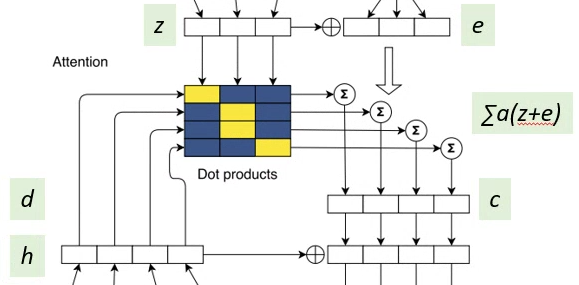
- Before computing the attention, the current decoder state hli is combined with an embedding of the previous target element gi to obtain the decoder summary dli (No corresponding blocks in the figure):
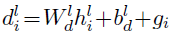
- Dot product of the decoder summary d and the encoder output z is performed (Center array in blue and yellow colors).
- The attention weight alij is obtained by using softmax on the dot product elements (Output of the center array).
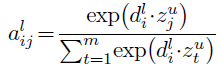
- Finally, conditional input ci is calculated which is the sum of attention weighted of (z+e):
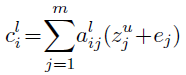
- Recall that zuj is the output of the convolution at encoder and ej is the embedding at the encoder. Encoder outputs zuj represent potentially large input contexts and ej provides point information about a specific input element that is useful when making a prediction.
1.5. Output
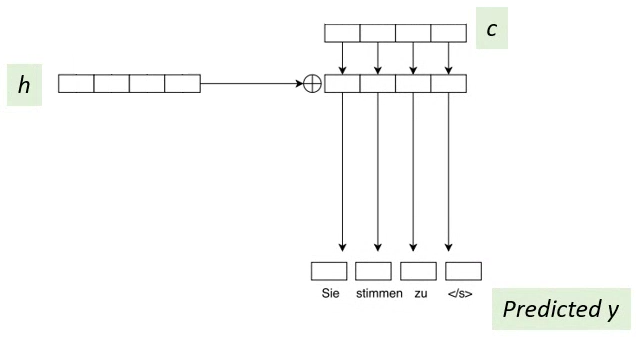
- Once cli has been computed, it is simply added to the output of the corresponding decoder layer hli, to get the predicted output.
1.6. Others
- Normalization is performed to scale the output of residual blocks as well as the attention to preserve the variance of activations.
- Careful weight initialization is done due to the normalization.
2. Experimental Results
2.1. Single Model

- On WMT’16 English-Romanian, ConvS2S has 20 layers in the encoder and 20 layers in the decoder, both using kernels of width 3 and hidden size 512 throughout.
ConvS2S outperforms the WMT’16 winning entry by 1.9 BLEU.
- On WMT’14 English to German translation, the proposed ConvS2S encoder has 15 layers and the decoder has 15 layers, both with 512 hidden units in the first ten layers and 768 units in the subsequent three layers, all using kernel width 3. The final two layers have 2048 units which are just linear mappings with a single input.
The ConvS2S model outpeforms GNMT by 0.5 BLEU.
- On WMT’14 English-French translation, ConvS2S has a bit different settings with different numbers of hidden units.
On WMT’14 English-French translation, ConvS2S improves over GNMT in the same setting by 1.6 BLEU on average. ConvS2S also outperforms GNMT’s reinforcement (RL) models by 0.5 BLEU.
2.2. Ensemble Model
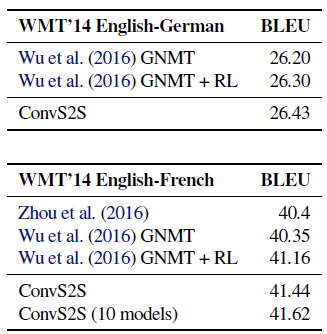
ConvS2S outperforms the best current ensembles on both datasets.
Convolution has limited receptive field, which makes it difficult to learn dependencies between distant positions.
There are also many other results and ablation studies in the paper. Please feel free to read if interested.
Reference
[2017 ICML] [ConvS2S]
Convolutional Sequence to Sequence Learning
Natural Language Processing (NLP)
Sequence Model: 2014 [GRU] [Doc2Vec]
Language Model: 2007 [Bengio TNN’07] 2013 [Word2Vec] [NCE] [Negative Sampling] 2016 [GCNN/GLU]
Sentence Embedding: 2015 [Skip-Thought]
Machine Translation: 2014 [Seq2Seq] [RNN Encoder-Decoder] 2015 [Attention Decoder/RNNSearch] 2016 [GNMT] [ByteNet] [Deep-ED & Deep-Att] 2017 [ConvS2S]
Image Captioning: 2015 [m-RNN] [R-CNN+BRNN] [Show and Tell/NIC] [Show, Attend and Tell]
