Review — DALL·E: Zero-Shot Text-to-Image Generation
DALL·E, or DALL-E, Using GPT-3 for Text-to-Image Generation
5 min readAug 30, 2022

Zero-Shot Text-to-Image Generation
DALL·E, by OpenAI
2021 ICLR, Over 500 Citations (Sik-Ho Tsang @ Medium)
Text-to-Image Generation, GPT-3, Transformer
- DALL·E is proposed for text-to-image generation, which is based on a 12-million-parameter GPT-3 that autoregressively models the text and image tokens as a single stream of data.
Outline
- DALL·E Overall Two-Stage Procedures
- Other Details, such as Datasets & Multi-GPU Training
- Experimental Results

- The goal is to train a Transformer, i.e. GPT-3, to autoregressively model the text and image tokens as a single stream of data.
1.1. Stage 1
- A discrete variational autoencoder (dVAE) is trained to compress each 256×256 RGB image into a 32×32 grid of image tokens, each element of which can assume 8192 possible values. This reduces the context size of the Transformer by a factor of 192 without a large degradation in visual quality, which exampled as above.
1.2. Stage 2
- 256 BPE-encoded text tokens are concatenated with the 32×32=1024 image tokens.
- An autoregressive Transformer to model the joint distribution over the text and image tokens.
1.3. Maximizing ELB
- The overall procedure can be viewed as maximizing the evidence lower bound (ELB) on the joint likelihood of the model distribution over images x, captions y, and the tokens z for the encoded RGB image.
- This distribution can be modeled using the factorization:

- With the lower bound of:

- where qφ denotes the distribution over the 32×32 image tokens generated by the dVAE encoder given the RGB image x,
- pθ denotes the distribution over the RGB images generated by the dVAE decoder given the image tokens, and
- pψ denotes the joint distribution over the text and image tokens modeled by the transformer.
2. Other Details, such as Datasets & Multi-GPU Training
2.1. Training Datasets
- To scale the model up to 12-billion parameters, i.e. GPT-3, a dataset of a similar scale to JFT-300M is created by collecting 250 million text-images pairs from the internet.
- This dataset does not include MS-COCO, but does include Conceptual Captions and a filtered subset of YFCC100M.
2.2. Mixed-Precision Training

- The solid line indicates the sequence of operations for forward propagation, and the dashed line the sequence of operations for backpropagation.
- The incoming gradient for each resblock is scaled by its gradient scale, and the outgoing gradient is unscaled before it is added to the sum of the gradients from the successive resblocks.
- The activations and gradients along the identity path are stored in 32-bit precision. The “filter” operation sets all Inf and NaN values in the activation gradient to zero.
- (Please feel free to read the paper directly for the details.)
2.3. Distributed Optimization
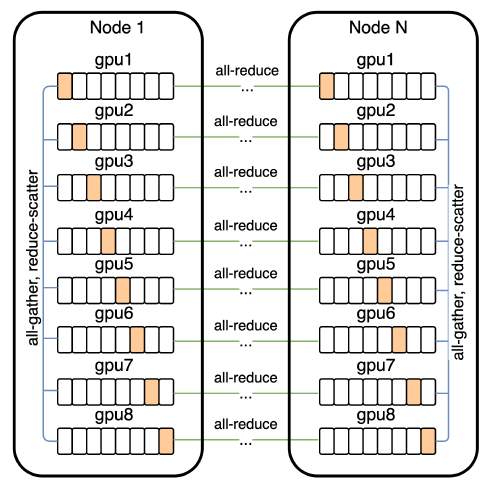
- The 12-billion parameter model consumes about 24 GB of memory when stored in 16-bit precision, which exceeds the memory of a 16 GB NVIDIA V100 GPU. Parameter sharding is needed. Each parameter array in the model is sharded among the eight GPUs on each machine.
- Averaging the gradient among the machines (all-reduce) makes the main bottleneck during training. PowerSGD (Vogels et al., 2019) is used to reduce this cost by compressing the gradients.
- (Please feel free to read the paper directly for the details.)
2.4. Sample Generation

- The samples drawn from the Transformer (GPT-3) are reranked using a pretrained contrastive model (Radford et al., 2021). Given a caption and a candidate image, the contrastive model assigns a score based on how well the image matches the caption.
- The above figure shows the effect of increasing the number of samples N from which the top k images are selected. Unless otherwise stated, N=512.
3. Experimental Results
3.1. Human Evaluation

- Given a caption, the sample from the proposed DALL·E model receives the majority vote for better matching the caption 93% of the time.
- It also receives the majority vote for being more realistic 90% of the time.
3.2. Quantitative Results
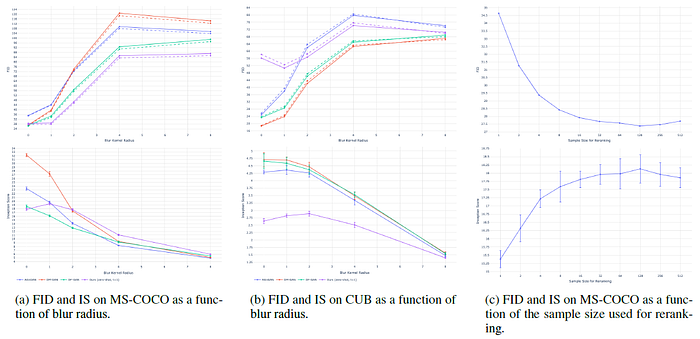
- (a) MS-COCO: FID and IS are computed after applying a Gaussian filter with varying radius to both the validation images and samples from the models.
- The proposed DALL·E model obtains an FID score on MS-COCO within 2 points of the best prior approach.
DALL·E model achieves the best FID by a margin of about 6 points with a slight blur of radius 1. DALL·E also obtains the highest IS when the blur radius is greater than or equal to two.
- (b) CUB: But DALL·E model fares significantly worse on the CUB dataset, for which there is a nearly 40-point gap in FID between DALL·E model and the leading prior approach.
DALL·E is less likely to compare favorably on specialized distributions such as CUB, i.e. a bird-species fine-grained image classification dataset.

- Some samples are shown on CUB dataset, as above.
- (c) MS-COCO (Function of sample size): Clear improvements in FID and IS are shown for MS-COCO as the sample size used for reranking with the contrastive model is increased.
This trend continues up to a sample size of 32.
3.3. More Text-to-Image Generation Results

- Each of DALL·E model samples is the best of 512 as ranked by the contrastive model, as shown above.
3.4. More Results from OpenAI Blog

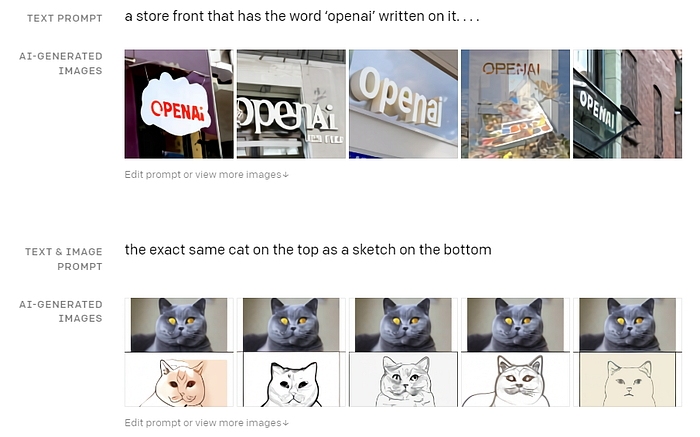
Later, DALL·E 2 is invented.
References
[2021 ICLR] [DALL·E]
Zero-Shot Text-to-Image Generation
[OpenAI Blog] [DALL·E]
https://openai.com/blog/dall-e/
5.2. Text-to-Image Generation
2021 [DALL·E]
