Brief Review — Conceptual Captions: A Cleaned, Hypernymed, Image Alt-text Dataset For Automatic Image Captioning
Conceptual Captions, Over 3M <Image, Caption> Pairs

Conceptual Captions: A Cleaned, Hypernymed, Image Alt-text Dataset For Automatic Image Captioning,
Conceptual Captions, by Google AI,
2018 ACL, Over 700 Citations (Sik-Ho Tsang @ Medium)
Vision Language Model (VLM), Image Captioning, Transformer
- Conceptual Captions, an image captioning dataset, is proposed, which has an order of magnitude more images than the MS-COCO dataset.
- An image captioning model is proposed as baseline, where Inception-ResNet-v2, as in Inception-v4, is used for image-feature extraction and Transformer for sequence modeling.
Outline
- Conceptual Captions: Dataset Generation Process
- Image Captioning Model
- Results
1. Conceptual Captions: Dataset Generation Process

- This pipeline processes billions of Internet webpages in parallel. From these webpages, it extracts, filters, and processes candidate <image, caption> pairs.
1.1. Image-based Filtering
- It only keeps JPEG images where both dimensions are greater than 400 pixels. Ratio cannot be smaller or larger than 2. Images that trigger pornography or profanity detectors are excluded.
- These filters discard more than 65% of the candidates.
1.2. Text-based Filtering
- It harvests Alt-text from HTML webpages.
- Google Cloud Natural Language APIs are used to analyze candidate Alt-text. Heuristics are also introduced.
- These filters only allow around 3% of the incoming candidates to pass to the later stages.
1.3. Image & Text-based Filtering
- Google Cloud Vision APIs are used to assign class labels to images. Images are generally assigned between 5 to 20 labels. These labels are matched against the candidate text.
- Candidates for which none of the text tokens can be mapped to the content of the image, are filtered out.
1.4. Text Transformation with Hypernymization

- Some rules are shown above.
- e.g.: named-entities are identified, matched against the KG entries, and substitute with their hypernym, using the Google Knowledge Graph (KG) Search API.
- Around 20% of samples are discarded during this transformation because it can leave sentences too short or inconsistent.
- These remaining <image, caption> pairs contain around 16,000 entity types.
1.5. Conceptual Captions Quality
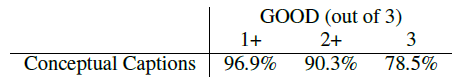
- A random sample of 4K examples are extracted from the test split.
- Out of 3 annotations, over 90% of the captions receive a majority (2+) of GOOD judgments. This indicates that the above pipeline produces high-quality image captions.
1.6. Dataset
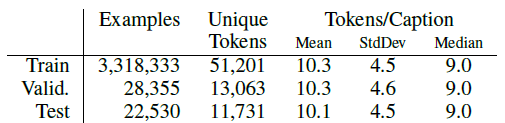
The training set consists of slightly over 3.3M examples, while there are slightly over 28K examples in the validation set and 22.5K examples in the test set.
- The size of the training set vocabulary (unique tokens) is 51,201.
2. Image Captioning Model

- A deep CNN that takes a (preprocessed) image and outputs a vector of image embeddings X.
- An Encoder module that takes the image embeddings and encodes them into a tensor H.
- A Decoder model that generates outputs zt at each step t, conditioned on H as well as the decoder inputs Y1:t.
- Inception-ResNet-v2, as in Inception-v4, as the CNN component.
- Two sequence models are tried: One is modified Show and Tell (RNN-based model). One is based on Transformer (T2T).
The goal is to produce baseline results.
3. Results
3.1. Qualitative Results

- e.g.: For the left-most image, COCO-trained models use “group of men” to refer to the people in the image; Conceptual-based models use the more appropriate and informative term “graduates”.
3.2. Human Evaluation
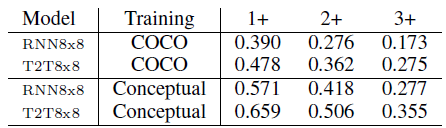
Conceptual-based models are superior. In 50.6% (for the T2T8x8 model) of cases, a majority of annotators (2+) assigned a GOOD label.
3.3. Auto Metric
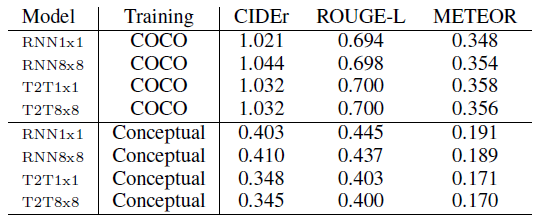
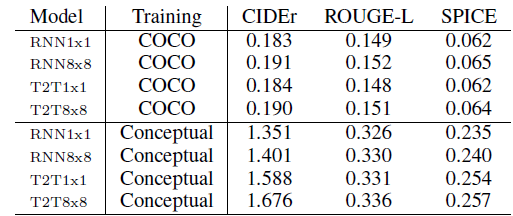
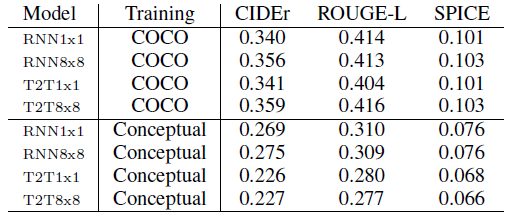
- For all metrics, higher number means closer distance between the candidates and the ground-truth captions.
- Different test sets are tried.
The automatic metrics fail to corroborate the human evaluation results.
Reference
[2018 ACL] [Conceptual Captions]
Conceptual Captions: A Cleaned, Hypernymed, Image Alt-text Dataset For Automatic Image Captioning
5.1. Visual/Vision/Video Language Model (VLM)
2018 [Conceptual Captions] 2019 [VideoBERT] [VisualBERT] [LXMERT] 2020 [ConVIRT]
5.2. Image Captioning
2015 [m-RNN] [R-CNN+BRNN] [Show and Tell/NIC] [Show, Attend and Tell] [LRCN] 2017 [Visual N-Grams] 2018 [Conceptual Captions]
