Review — Multi-Task Learning for Segmentation and Classification of Tumors in 3D Automated Breast Ultrasound Images
CMSVNetIter, V-Net with Multi-Task Learning and Iterative Training Strategy

Multi-Task Learning for Segmentation and Classification of Tumors in 3D Automated Breast Ultrasound Images,
CMSVNetIter, by Beijing Jiaotong University, University of North Carolina, Peking University People’s Hospital, ShanghaiTech University, and Korea University
2021 JMEDIA, Over 90 CItations (Sik-Ho Tsang @ Medium)
Medical Imaging, Medical Image Analysis, Multi-Task Learning, Image Segmentation, Image Classification
- It is argued that learning both classification and segmentation tasks jointly is able to improve the outcomes of both tasks.
- The proposed framework consists of two sub-networks: an encoder-decoder network for segmentation and a light-weight multi-scale network for classification.
- An iterative training strategy is proposed to refine feature maps.
Outline
- CMSVNet Model Architecture
- Iterative Feature Refinement & Loss Function
- Experimental Results
1. CMSVNet Model Architecture

1.1. Segmentation
- V-Net is used as backbone, which consists of three parts: (i) an encoding path, (ii) a decoding path, and (iii) skip connections between them.
- The encoding path employs four down-sampling operations to extract high-level semantic features.
- The decoding path utilizes four up-sampling operations to restore the feature maps to the original input size.
- Skip connections connect feature maps from the encoding path to the decoding path to propagate spatial information and refine segmentation outcomes.
- Convolution of 3×3×3 kernel size is used. BN and ReLU are used.
- Convolution of 2×2×2 kernel size with stride of 2 is used for downsampling instead of pooling.
1.2. Classification

- Feature maps from Stage 4 to Stage 6 in V-Net are fused as classification features.
- Channel-wise global average pooling (GAP) to convert feature maps from different stages to the same size in each channel.
- Generally, the amplitudes of features from the deeper layers are smaller than the shallow layers. Normalization is performed before connection:

- where c is the channel number, xi is the global feature from each channel, and ˆxi is the normalized feature.
2. Iterative Feature Refinement & Loss Function
2.1. Iterative Feature Refinement

- Line 3: In the initial iteration, the input to the multi-task learning network is a 3D ABUS volume.
- Line 5: In subsequent iterations, the input volume is modulated via addition with the probability map from the last iteration.
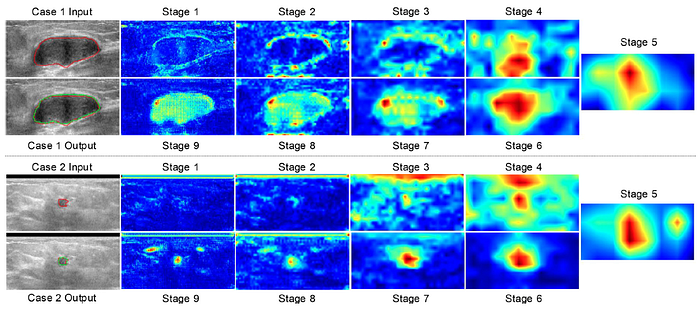
- Stage 9 feature map as shown above is used as input in the subsequent iterations via addition.
2.2. Multi-Task Loss Function
- A modified weighted focal loss, as from RetinaNet, is used as the classification loss function:
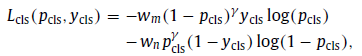
- where pcls and ycls are the predicted volume classification probability from the proposed network and the ground truth class of this volume ( ycls=0 for benign and ycls=1 for malignant). γ=2.
- wm and wn are weights for malignant and benign cases:
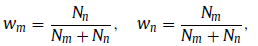
- where Nn and Nm are the numbers of benign and malignant volumes, respectively.
- For segmentation, a segmentation loss based on the Dice coefficient is utilized to emphasize shape similarity:

- where Lseg is the segmentation loss, Pseg and Yseg denote the predicted segmentation map from the proposed network and the la- beled tumor map.
- The multi-task loss is defined as:
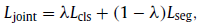
3. Experimental Results
3.1. Dataset, Methods, & Metrics
3.1.1. Dataset

- A total number of 170 volumes from 107 patients were collected.
- Four-fold cross-validation is used for all experiments.
- Tumor regions were cropped with the size of 64 ×32 ×64 mm³ based on tumor centers.
3.1.2. Methods

- V-Net & ClsNet: The single-task models ClsNet and V-Net were trained as the classification and the segmentation baseline models, respectively.
- CVNet: For multi-task learning, a single-scale classification branch is added to V-Net, which used the feature map from Stage 5 as the classification feature,
- CVNetIter: CVNet is trained using the iterative feature-refining strategy with the number of iterations, N=2.
- CMSVNet: Multi-scale classification branch is used.
- CMSVNetIter: Finally, CMSVNet model is trained using the iterative feature-refining strategy with the number of iterations N=2.
3.1.3. Metrics
- Segmentation: Dice similarity coefficient (DSC), Jaccard index (JI), and 95th percentage of the asymmetric Hausdorffdistance (95HD).

- Classification: Receiver operating characteristic (ROC), area under ROC curve (AUC), recall (REC), precision (PRE), accuracy (ACC), false positive rate (FPR), and F1-score (F1).
3.2. Segmentation Results

When N=2, the iterative training strategy yields the best performance with DSC, JI, and 95HD at 0.754, 0.628, and 3.870 mm, respectively. N=2 is used in remaining experiments.
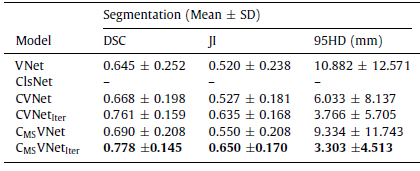
The proposed CMSVNetIter model outperforms other models in all metrics with DSC, JI, and 95HD at 0.778, 0.650, and 3.303 mm, respectively.
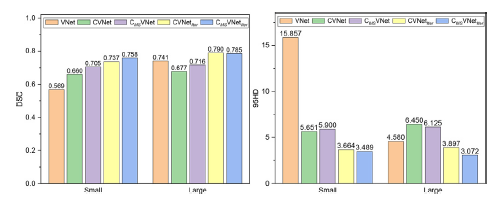
CMSVNetIter achieves the best performance for small tumors with DCS at 0.758 and 95HD at 3.489 mm,
Both CMSVNetIter and CVNetIter perform better for large tumors.

Compared with other methods, CMSVNetIter is capable of adapting to tumors of various sizes.
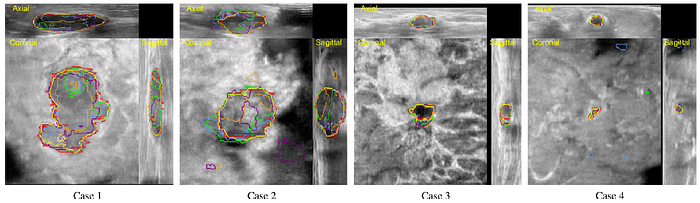
The proposed method gives results that are consistent with the ground truth.
3.3. Classification Results
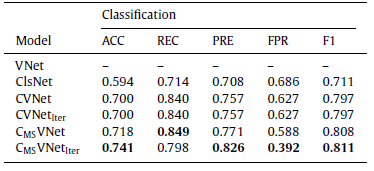
CVNet uses single-scale feature extraction for classification and improves classification results compared with the classification baseline ClsNet, which verifies that segmentation improves classification.
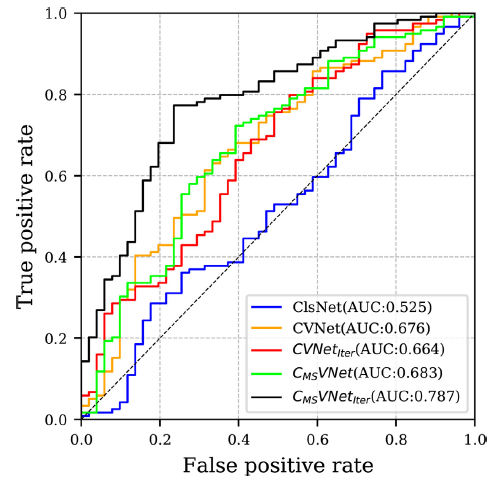
Multi-scale feature concatenation improves classification performance.
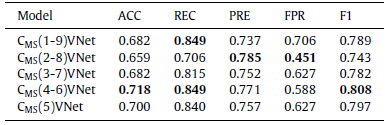
- Multi-scale feature ablation is performed, e.g.: CMS(4–6)VNet model uses feature maps from Stage 4, Stage 5, and Stage 6.
Involving too many features with different scales does not necessarily result in better classification performance.
3.4. Multi-Task Learning
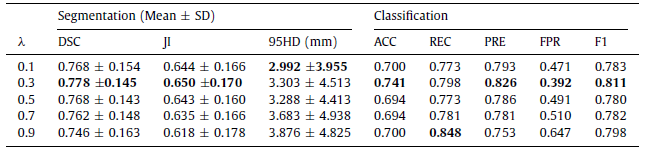
When λ is set to 0.3, CMSVNetIter balances classification and segmentation and gives the best performance on DSC, JI, ACC, PRE, FPR, and F1 score.
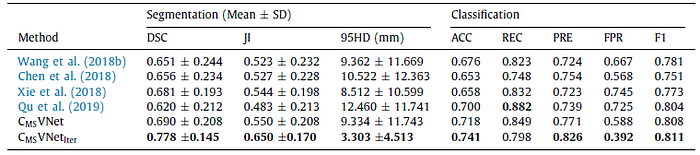
The proposed CMSVNetIter model achieves the best performance for all metrics except REC and CMSVNet yields the second best REC among all methods.

- A benign tumor and a malignant tumor that are misclassified by the classification baseline due to their similar appearances. However, they are correctly classified by the proposed method when multi-scale features are used (i.e., CMSVNet and CMSVNetIter).
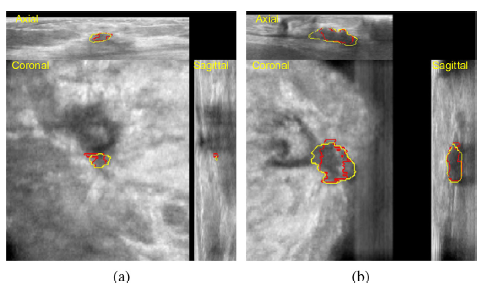
- Tumors adjacent to nipple regions are difficult to be segmented. The proposed method successfully locates such tumors, however, segmentation metrics are not satisfied.
Reference
[2021 JMEDIA] [CMSVNetIter]
Multi-Task Learning for Segmentation and Classification of Tumors in 3D Automated Breast Ultrasound Images
4.3. Biomedical Image Multi-Task Learning
2018 [ResNet+Mask R-CNN] [cU-Net+PE] [Multi-Task Deep U-Net] [cGAN-AutoEnc & cGAN-Unet] 2019 [cGAN+AC+CAW] [Qu ISBI’19] 2020 [BUSI] [Song JBHI’20] [cGAN JESWA’20] 2021 [Ciga JMEDIA’21] [CMSVNetIter]
