Review — OHEM: Training Region-based Object Detectors with Online Hard Example Mining (Object Detection)
Using OHEM on Fast R-CNN, Heuristics Removed, Detection Accuracy Improved, Outperforms MR-CNN
In this story, Training Region-based Object Detectors with Online Hard Example Mining, (OHEM), by Carnegie Mellon University, and Facebook AI Research (FAIR), is reviewed.
Detection datasets contain an overwhelming number of easy examples and a small number of hard examples.
In this paper:
- OHEM automatic selects these hard examples can make training more effective and efficient.
- OHEM eliminates several heuristics and hyperparameters in common use.
This is a paper in 2016 CVPR with over 1300 citations. (Sik-Ho Tsang @ Medium)
Outline
- Brief Review of Fast R-CNN (FRCN)
- Several Heuristics in FRCN
- Online Hard Example Mining (OHEM)
- Experimental Results
1. Brief Review of Fast R-CNN (FRCN)

- FRCN takes as input an image and a set of object proposal regions of interest (RoIs), where object proposals are generated by Selective Search (SS), in which SS is a non-deep-learning approach.
- The conv network is applied to the given image to produce a conv feature map.
- For each object proposal, the RoI-pooling layer projects the proposal onto the conv feature map and extracts a fixed-length feature vector.
- Each feature vector is fed into the fc layers, which finally give two outputs: Softmax probability and regressed coordinates for bounding-box.
- For each minibatch, N images are first sampled from the dataset, and then B/N RoIs are sampled from each image. Setting N = 2 and B = 128.
These RoI sampling procedure uses several heuristics.
2. Several Heuristics in FRCN
2.1. Foreground RoIs
- For an example RoI to be labeled as foreground (fg), its intersection over union (IoU) overlap with a ground-truth bounding box should be at least 0.5. This is a very standard design choice.
2.2. Background RoIs
- A region is labeled background (bg) if its maximum IoU with ground truth is in the interval [bg_lo; 0:5).
A lower threshold of bg_lo = 0.1 is used.
- It is assumed that regions with some overlap with the ground truth are more likely to be the confusing or hard ones.
- Although this heuristic helps convergence and detection accuracy, it is suboptimal because it ignores some infrequent, but important, difficult background regions.
- OHEM removes the bg_lo threshold.
2.3. Balancing fg-bg RoIs
To handle the data imbalance, heuristics is designed to rebalance the foreground-to-background ratio in each mini-batch to a target of 1 : 3 by undersampling the background patches at random, thus ensuring that 25% of a mini-batch is fg RoIs.
- OHEM removes this ratio hyperparameter with no ill effect.
3. Online Hard Example Mining (OHEM)
3.1. OHEM
- The loss of each RoI represents how well the current network performs on each RoI.
Hard examples are selected by sorting the input RoIs by loss and taking the B/N examples for which the current network performs worst.
- The extra computation needed to forward all RoIs is relatively small.
- The backward pass is no more expensive than before.
- Overlapping RoIs can project onto the same region. To deal with these redundant and correlated regions, non-maximum suppression (NMS) is used to perform deduplication.
Given a list of RoIs and their losses, NMS works by iteratively selecting the RoI with the highest loss, and then removing all lower loss RoIs that have high overlap with the selected region. A relaxed IoU threshold of 0.7 is used to suppress only highly overlapping RoIs.
- Thus, OHEM removes the bg_lo threshold.
- And OHEM does not need a fg-bg ratio for data balancing. If any class were neglected, its loss would increase.
- There can be images where the fg RoIs are easy (e.g. canonical view of a car), so the network is free to use only bg regions in a mini-batch; and vice versa when bg is trivial (e.g. sky, grass etc.), the mini-batch can be entirely fg regions.
3.2. Implementation Details

- The implementation maintains two copies of the RoI network, one of which is readonly.
- The readonly RoI network performs a forward pass and computes loss for all input RoIs (R) (green arrows).
- Then the hard RoI sampling module uses OHEM to select hard examples (Rhard-sel), which are input to the regular RoI network (red arrows).
- This network computes forward and backward passes only for Rhard-sel.
4. Experimental Results
4.1 OHEM on PASCAL VOC 2007

- Two networks are used: VGGM, which is a wider version of AlexNet, and also VGG-16.
- FRCN with bg_lo = 0, rows 3-4 show that for VGGM, mAP drops by 2.4 points, whereas for VGG-16 remains similar comparing with rows 1–2.
- Different settings are also tried (rows 5–10).
- OHEM (rows 11–13) improves mAP by 2.4 points compared to FRCN with the bg_lo = 0.1 heuristic for VGGM, and 4.8 points without the heuristic.
- This result demonstrates the sub-optimality of these heuristics and the effectiveness of our hard mining approach.
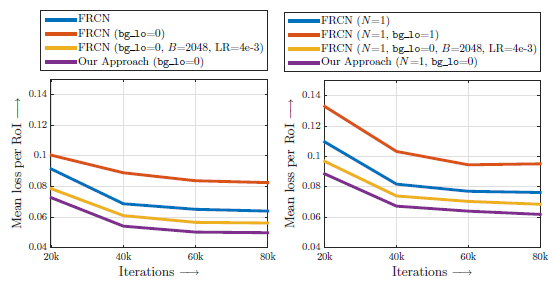
- OHEM achieves the lowest training loss of all methods, validating our claims that OHEM leads to better training for FRCN.
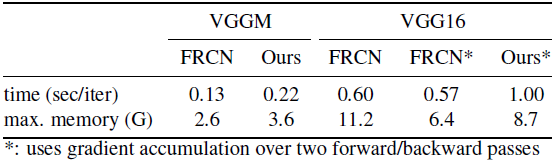
- OHEM costs 0.09s per training iteration for VGGM network (0.43s for VGG-16) and requires 1G more memory (2.3G for VGG-16).
- The increase in training time is likely acceptable to most users.
4.2. PASCAL VOC 2007 & 2012


4.3. MS COCO, & Adding Bells and Whistles

- FRCN scores 19.7% AP, and OHEM improves it to 22.6% AP.
- With multi-scale for training and testing (M), 24.4% AP and 25.5% AP are obtained for different training sets.
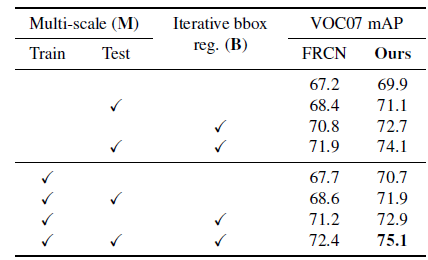
- With iterative bounding-box regression (B), high-scoring boxes are the rescored and relocalized, yielding a more accurate boxes.
- Using OHEM consistently results in higher mAP for all variants of these two additions (M and B).
- In the 2015 MS COCO Detection Challenge, a variant of OHEM finished 4th place overall.
Reference
[2016 CVPR] [OHEM]
Training Region-based Object Detectors with Online Hard Example Mining
Object Detection
2014: [OverFeat] [R-CNN]
2015: [Fast R-CNN] [Faster R-CNN] [MR-CNN & S-CNN] [DeepID-Net]
2016: [OHEM] [CRAFT] [R-FCN] [ION] [MultiPathNet] [Hikvision] [GBD-Net / GBD-v1 & GBD-v2] [SSD] [YOLOv1]
2017: [NoC] [G-RMI] [TDM] [DSSD] [YOLOv2 / YOLO9000] [FPN] [RetinaNet] [DCN / DCNv1] [Light-Head R-CNN] [DSOD]
2018: [YOLOv3] [Cascade R-CNN] [MegDet] [StairNet]
2019: [DCNv2] [Rethinking ImageNet Pre-training] [GRF-DSOD & GRF-SSD]
