Review — S3D, S3D-G: Rethinking Spatiotemporal Feature Learning: Speed-Accuracy Trade-offs in Video Classification
S3D: Using Separable 3D Convolution; S3D-G: Further Improved With Spatio-Temporal Feature Gating
Rethinking Spatiotemporal Feature Learning: Speed-Accuracy Trade-offs in Video Classification, S3D, S3D-G, by Google Research, and University of California San Diego
2018 ECCV, Over 700 Citations (Sik-Ho Tsang @ Medium)
Video Classification, Action Recognition
- 3D CNNs are useful to convolve jointly over time and space. But 3D CNNs are much more expensive than 2D CNNs and prone to overfit.
- It is found that it is possible to replace many of the 3D convolutions at early stages by low-cost 2D convolutions.
1. I2D, I3D, Bottom-Heavy I3D, Top-Heavy I3D

- I2D, which is a 2D CNN, operating on multiple frames.
- I3D, which is a 3D CNN, convolving over space and time.
- Bottom-Heavy I3D, which uses 3D in the lower layers, and 2D in the higher layers.
- Top-Heavy I3D, which uses 2D in the lower (larger) layers, and 3D in the upper layers.
- The architecture details are shown below:

2. S3D
2.1. Separable 3D Convolution

- To separate space and time, 3D convolutions with spatial and temporal are replaced by separable 3D convolutions, i.e., replace filters of the form kt×k×k by 1×k×k followed by kt×1×1, where kt is the width of the filter in time, and k is the height/width of the filter in space.
- (For Inception, please feel free to read GoogLeNet / Inception-v1, BN-Inception / Inception-v2, Inception-v3, and Inception-v4)
2.2. Separable 3D CNN (S3D)

- The Separable 3D Convolution is used at the early layers.
- The resulting model is called S3D, which stands for “Separable 3D CNN”.
- (For separable convolution, please feel free to read Xception, MobileNetV1, MobileNetV2, and MobileNetV3)
2.3. Spatio-Temporal Feature Gating
- The accuracy of S3D is further improved by using feature gating:
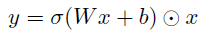
- This gating module is plugged into any layer of the network, and forms S3D-G.
- (For gating, please feel free to read Highway.)
3. Experimental Results

I2D underperforms I3D by a large margin.
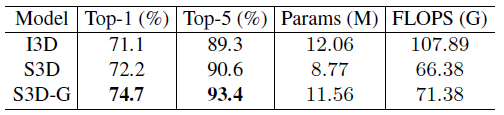
S3D and S3D-G outperforms I3D by a large margin with fewer FLOPs.
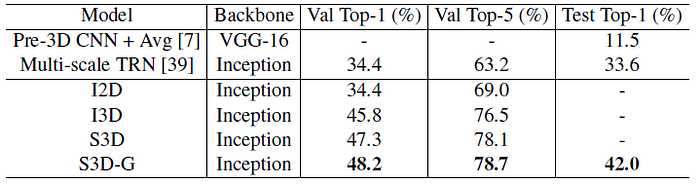
S3D-G also outperforms S3D and I3D on Something-something.
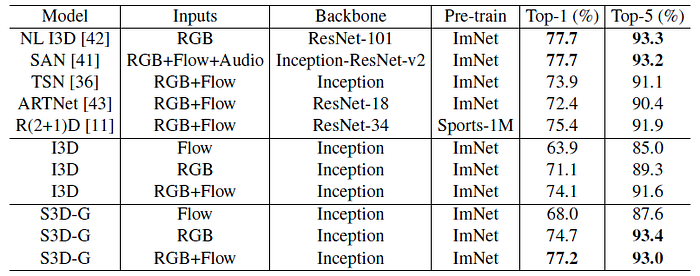
Using optical flow features as input, the performance is competitive compared with recent Kinetics Challenge winners and concurrent works.
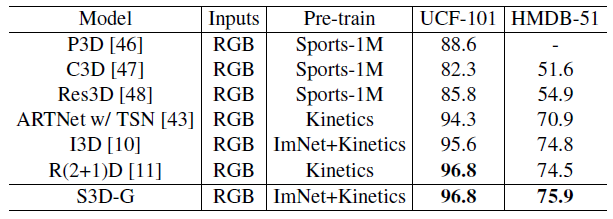
On UCF-101, the proposed S3D-G architecture, which only uses Kinetics for pretraining, outperforms I3D, and matches R(2+1)D, both of which use largescale datasets (Kinetics and Sports-1M) for pretraining.
On HMDB-51, S3D-G outperforms all previous methods published to date.
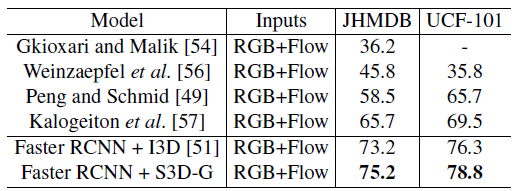
- Faster R-CNN object detection algorithm is used to jointly perform person localization and action recognition.
- The model uses a 2D ResNet-50 network that takes the annotated keyframe (frame with box annotations) as input, and extract features for region proposal generation on the keyframe.
- A 3D network (such as I3D or S3D-G) is then used to take the frames surrounding the keyframe as input, and feature maps are extracted, which are then pooled for bounding box classification.
Both 3D networks outperform previous architectures by large margins, while S3D-G is consistently better than I3D.
Reference
[2018 ECCV] [S3D, S3D-G]
Rethinking Spatiotemporal Feature Learning: Speed-Accuracy Trade-offs in Video Classification
Video Classification / Action Recognition
2014 [Deep Video] [Two-Stream ConvNet] 2015 [DevNet] [C3D] 2016 [TSN] 2017 [Temporal Modeling Approaches] [4 Temporal Modeling Approaches] [P3D] [I3D] 2018 [NL: Non-Local Neural Networks] [S3D, S3D-G]
