Review: Virtual Adversarial Training (VAT)
VAT for Semi-Supervised Learning, Outperforms Ladder Network, Γ-Model & Π-Model

Virtual Adversarial Training: A Regularization Method for Supervised and Semi-Supervised Learning
VAT, by Preferred Networks, Inc., ATR Cognitive Mechanisms Laboratories, Ritsumeikan University, and Kyoto University
2019 TPAMI, Over 1500 Citations (Sik-Ho Tsang @ Medium)
This paper is extended from “Distributional Smoothing with Virtual Adversarial Training” in 2016 ICLR with over 400 Citations.
- A new measure of local smoothness of the conditional label distribution given input is proposed.
- Virtual adversarial loss is defined as the robustness of the conditional label distribution around each input data point against local perturbation.
Outline
- Virtual Adversarial Training (VAT)
- Experimental Results
1. Virtual Adversarial Training (VAT)

- In Temporal Ensembling and Mean Teacher, MSE is used for estimating the similarity between two predictions.
- In contrast, in Virtual Adversarial Training (VAT), KL divergence is used:

- where x is input, r is a small perturbation on x, y is output, and Q is the set of labels.

- The perturbation r should be in the adversarial direction such that the prediction of the perturbed input should be different from the original one, i.e. the KL divergence between the two output distributions should be large:

- where ε is the norm constraint.
- Local Distribution Smoothing (LDS) loss is defined:

The loss LDS(x,θ) can be considered as a negative measure of the local smoothness of the current model at each input data point x.
- The regularization term proposed in this paper is the average of LDS(x*,θ) over all input data points:

- where Nl is the number of labelled samples, Nul is the number of unlabelled samples, Dl is the labelled samples, Dul is the unlabelled samples.
- The full objective function is:
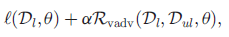
- where l(Dl,θ) is the negative log-likelihood for the labeled dataset. VAT is a training method with the regularizer Rvadv.

- To perform VAT, first, get M randomly selected samples.
- Generate a random unit vector for each sample, to calculate rvadv by taking the gradient.

- The above codes are from the author.
- d in the code is equal to r in the paper.

- LDSs are large for the points at the class boundary, and getting smaller after each update.
2. Experimental Results
2.1. MNIST

- NN with four hidden layers, of {1200, 600, 300, 150}, is used.
VAT outperforms many other semi-supervised methods except Ladder Network or GANs.
2.2. SVHN & CIFAR-10
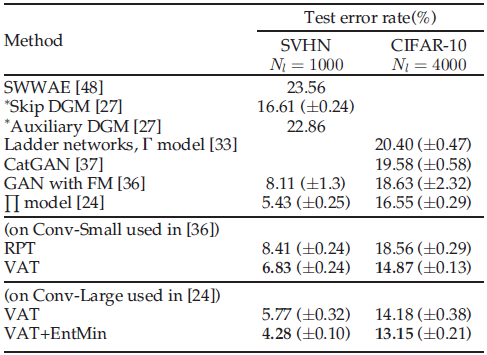
- Two CNNs, Conv-Small and Conv-Large, are used.
VAT achieved the test error rate of 14.82%, which outperformed the state-of-the-art methods for semi-supervised learning on CIFAR-10.
- With EntMin, ‘VAT+EntMin’ outperformed the state-of-the-art methods for semi-supervised learning on both SVHN and CIFAR-10.
2.3. Ablation of ε and α
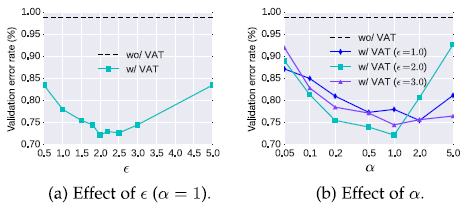
- α is fixed to be 1. ε is the only hyperparameter to be tuned.
2.4. Virtual Adversarial Examples

References
[2016 ICLR] [VAT]
Distributional Smoothing with Virtual Adversarial Training
[2019 TPAMI] [VAT]
Virtual Adversarial Training: A Regularization Method for Supervised and Semi-Supervised Learning
Pretraining or Semi-Supervised Learning
2004 [Entropy Minimization, EntMin] 2013 [Pseudo-Label (PL)] 2015 [Ladder Network, Γ-Model] 2016 [Sajjadi NIPS’16] 2017 [Mean Teacher] [PATE & PATE-G] [Π-Model, Temporal Ensembling] 2018 [WSL] 2019 [VAT] [Billion-Scale] [Label Propagation] [Rethinking ImageNet Pre-training] 2020 [BiT] [Noisy Student] [SimCLRv2]