Review — SimCLRv2: Big Self-Supervised Models are Strong Semi-Supervised Learners
Semi-Supervised Learning Using Self-Supervised SimCLRv2, Outperforms SimCLR, BYOL, PIRL, CPCv2, & etc.

Big Self-Supervised Models are Strong Semi-Supervised Learners
SimCLRv2, by Google Research, Brain Team
2020 NeurIPS, Over 600 Citations (Sik-Ho Tsang @ Medium)
Semi-Supervised Learning, Self-Supervised Learning, Unsupervised Learning, Contrastive Learning, Representation Learning, Image Classification
- The proposed semi-supervised learning algorithm can be summarized in three steps:
- Unsupervised pretraining of a big ResNet model using SimCLRv2,
- Supervised fine-tuning on a few labeled examples, and
- Distillation with unlabeled examples for refining and transferring the task-specific knowledge.
Outline
- SimCLRv2 Semi-Supervised Learning Framework
- Step 1: Self-Supervised Pretraining with SimCLRv2
- Step 2: Supervised Fine-Tuning
- Step 3: Self-Training/Knowledge Distillation via Unlabeled Examples
- Experimental Results
1. SimCLRv2 Semi-Supervised Learning Framework

- The proposed semi-supervised learning framework leverages unlabeled data in both task-agnostic and task-specific ways.
- Unsupervised Pretraining: The first time the unlabeled data is used, it is in a task-agnostic way.
- Supervised fine-Tuning: The general representations are then adapted for a specific task via supervised fine-tuning.
- Distillation: The second time the unlabeled data is used, it is in a task-specific way.
- (Please feel free to read SimCLR if interested.)
2. Step 1: Self-Supervised Pretraining with SimCLRv2
- SimCLRv2, improves upon SimCLR in three major ways.
2.1. Larger ResNet
- Models used are deeper but less wide. The largest model used is a 152-layer ResNet with 3× wider channels and selective kernels (SK) used in SKNet, a channel-wise attention mechanism that improves the parameter efficiency of the network.
- By scaling up the model from ResNet-50 to ResNet-152 (3×+SK), a 29% relative improvement in top-1 accuracy is obtained when fine-tuned on 1% of labeled examples.
2.2. Deeper Projection Head
- The capacity of the non-linear network g() (a.k.a. projection head) is increased, by making it deeper.
- Furthermore, instead of throwing away g() entirely after pretraining as in SimCLR, a middle layer of projection head is fine-tuned.
- Compared to SimCLR with 2-layer projection head, SimCLRv2 uses a 3-layer projection head and fine-tunes from the 1st layer of projection head, it results in as much as 14% relative improvement in top-1 accuracy when fine-tuned on 1% of labeled examples.
2.3. Memory Mechanism from MoCo
- A memory network (with a moving average of weights for stabilization) whose output will be buffered as negative examples, is used.
- The memory buffer is set to 64K. Exponential moving average (EMA) decay is set to 0.999.
- This change yields an improvement of ~1% for linear evaluation as well as when fine-tuning on 1% of labeled examples.
4. Step 3: Self-Training/Knowledge Distillation via Unlabeled Examples
- The fine-tuned network is used as a teacher to impute labels for training a student network.
- Specifically, the following distillation loss is minimized where no real labels are used:

- where
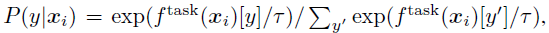
- And τ is temperature for model Distillation.
- The teacher network, which produces PT(y|xi), is fixed during the distillation. Only the student network, which produces PS(y|xi), is trained.
- In this paper, authors focus on using unlabeled examples only.
- One can also combine the distillation loss with ground-truth labeled examples using a weighted combination:
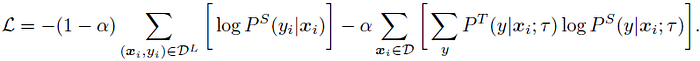
- This procedure can be performed using students either with the same model architecture (self-distillation), which further improves the task-specific performance, or with a smaller model architecture, which leads to a compact model.
5. Experimental Results
5.1. Bigger Models are More Label-Efficient

- ResNet models are trained by varying width and depth as well as whether or not to use selective kernels (SK). The smallest model is the standard ResNet-50, and biggest model is ResNet-152 (3×+SK).
Increasing width and depth, as well as using SK, all improve the performance.
- But ResNet-152 (3×+SK) is only marginally better than ResNet-152 (2×+SK), though the parameter size is almost doubled, suggesting that the benefits of width may have plateaued.
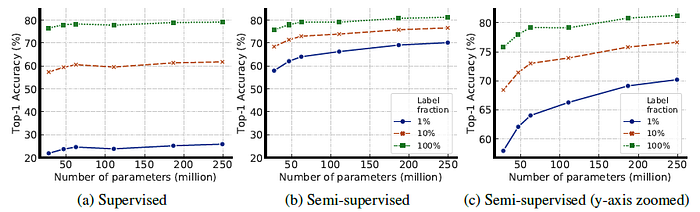
- These results show that bigger models are more label-efficient for both supervised and semi-supervised learning, but gains appear to be larger for semi-supervised learning.
5.2. Bigger/Deeper Projection Heads Improve Representation Learning
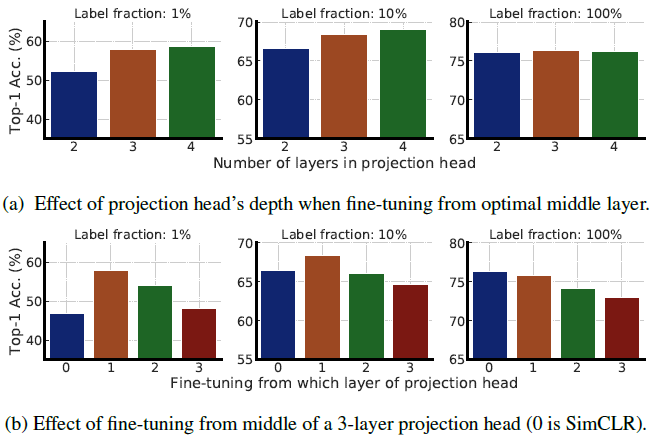
- Wider ResNets also have wider projection heads.
- Using a deeper projection head during pretraining is better when fine-tuning from the optimal layer of projection head (Figure a), and this optimal layer is typically the first layer of projection head rather than the input (0th layer), especially when fine-tuning on fewer labeled examples (Figure b).
5.3. Distillation Using Unlabeled Data Improves Semi-Supervised Learning

- The above table demonstrates the importance of using unlabeled examples when training with the distillation loss.
- Furthermore, using the distillation loss alone works almost as well as balancing distillation and label losses.
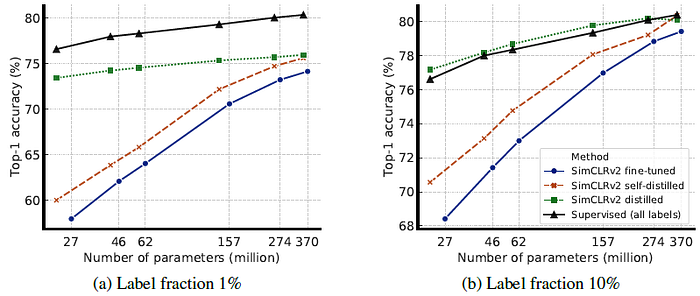
- When the student model has a smaller architecture than the teacher model, it improves the model efficiency by transferring task-specific knowledge to a student model.
- Even when the student model has the same architecture as the teacher model (excluding the projection head after ResNet encoder), self-distillation can still meaningfully improve the semi-supervised learning performance.
5.4. SOTA Comparison
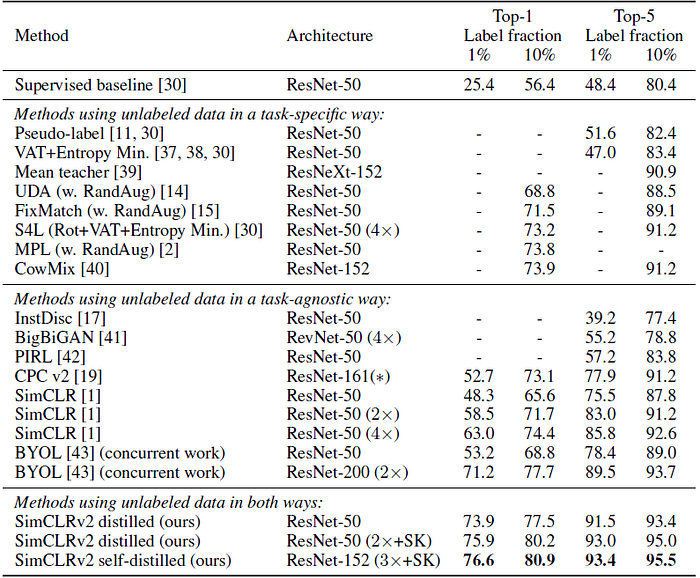
The proposed approach greatly improves upon previous results such as SimCLR, BYOL, PIRL, CPCv2, Instance Discrimination, Mean Teacher, Pseudo-Label (PL), & etc., for both small and big ResNet variants.
Impact
Authors also mentioned the impact of semi-supervised learning at the end of the paper:
- In medical applications where acquiring high-quality labels requires careful annotation by clinicians, better semi-supervised learning approaches can potentially help save lives.
- Applications of computer vision to agriculture can increase crop yields, which may help to improve the availability of food. … etc.
Reference
[2020 NeurIPS] [SimCLRv2]
Big Self-Supervised Models are Strong Semi-Supervised Learners
Unsupervised/Self-Supervised Learning
1993–2017 … 2018 [RotNet/Image Rotations] [DeepCluster] [CPC/CPCv1] [Instance Discrimination] 2019 [Ye CVPR’19] 2020 [CMC] [MoCo] [CPCv2] [PIRL] [SimCLR] [MoCo v2] [iGPT] [BoWNet] [BYOL] [SimCLRv2]
Pretraining or Weakly/Semi-Supervised Learning
2013 [Pseudo-Label (PL)] 2017 [Mean Teacher] 2018 [WSL] 2019 [Billion-Scale] [Label Propagation] [Rethinking ImageNet Pre-training] 2020 [BiT] [Noisy Student] [SimCLRv2]
