Review: Self-Attention with Relative Position Representations
Transformer Using Relative Position Representations

Self-Attention with Relative Position Representations
Shaw NAACL’18, by Google, & Google Brain
2018 NAACL, Over 900 Citations (Sik-Ho Tsang @ Medium)
Language Model, Natural Language Processing, NLP, Machine Translation, Transformer
- The self-attention mechanism in original Transformer is extended to efficiently consider representations of the relative positions, or distances between sequence elements.
Outline
- Original Transformer
- Transformer with Relative Position Representations
- Experimental Results
1. Original Transformer
1.1. Overall Architecture
- The Transformer uses encoder-decoder architecture.
- Encoder layers consist of two sublayers: self-attention followed by a position-wise feed-forward layer.
- Decoder layers consist of three sublayers: self-attention followed by encoder-decoder attention, followed by a position-wise feed-forward layer.
- It uses residual connections around each of the sublayers, followed by layer normalization.
1.2. Self-Attention
- Self-attention sublayers employ h attention heads.
- Each attention head operates on an input sequence, x=(x1, …, xn) of n elements, and computes a new sequence z=(z1, …, zn) of the same length, where x and z has dimension lengths of da and dz respectively.
- Each output element, zi, is computed as weighted sum of a linearly transformed input elements (Eq.(1)):

- Each weight coefficient, αij, is computed using a softmax function (Eq.(2)):

- And eij is computed using a compatibility function that compares two input elements (Eq.(3)):

- where WQ, WK, WV are the query, key, and value parameter matrices.
2. Transformer with Relative Position Representations
2.1. Relation-aware Self-Attention
- An extension to self-attention is proposed to consider the pairwise relationships between input elements in the sense that the input is modeled as a labeled, directed, fully-connected graph.
The edge between input elements xi and xj is represented by vectors:

- These representations can be shared across attention heads.
- Eq.(1) is modified to propagate edge information aVij to the sublayer output:

- Eq. (2) is also modified to consider edges aKij when determining compatibility (Eq. (4)):
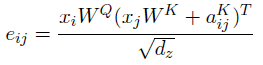
- The simple addition to incorporate edge representations is to enable an efficient implementation.
- The dimension of aVij and aKij is da where da=dz.
- The values of aVij and aKij are determined in the next sub-section.
2.2. Relative Position Representations
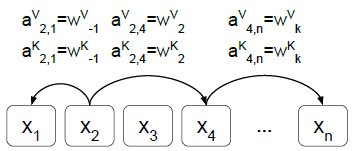
- Edges can capture information about the relative position differences between input elements.
The maximum relative position is clipped to a maximum absolute value of k. It is hypothesized that precise relative position information is not useful beyond a certain distance. Clipping the maximum distance also enables the model to generalize to sequence lengths not seen during training.
- Therefore, 2k+1 unique edge labels are considered.
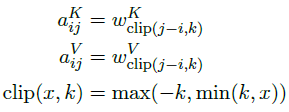
- where the learn relative position representations are:
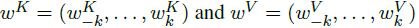
2.3. Efficient Implementation
- For a sequence of length n and h attention heads, by sharing them across each heads, the space complexity of storing relative position representations is reduced from O(h n² da) to O(n² da) where h is the head size.
- Additionally, relative position representations can be shared across sequences. Therefore, the overall self-attention space complexity increases from O(b h n dz) to O(b h n dz+n² da), where b is the batch size.
- Given da=dz, the size of the relative increase depends on n/bh.
- Without relative position representations, each eij can be computed using bh parallel multiplications of n×dz and dz×n matrices.
- However, using relative position representations prevents from parallel eij computation.
- The computation of Eq. (4) can be split into two terms:
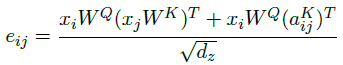
- The first term is identical to Eq. (2).
- For the second term involving relative position representations, tensor reshaping can be used to compute n parallel multiplications of bh×dz and dz×n matrices.
- The same approach can be used to efficiently compute Eq. (3).
- For the machine translation experiments, the result was a modest 7% decrease in steps per second, but the same model and batch sizes were able to maintained on P100 GPUs.
3. Experimental Results
- For all experiments, tokens are split into a 32,768 word-piece vocabulary. Sentence pairs are batched by approximate length, and input and output tokens per batch are limited to 4096 per GPU. Each resulting training batch contained approximately 25,000 source and 25,000 target tokens.
- For evaluation, beam search with a beam size of 4 and length penalty α=0.6 is used.
- For the proposed base model, 6 encoder and decoder layers are used, dx=512, dz=64, 8 attention heads, 1024 feed forward inner-layer dimensions, and Pdropout=0.1. Clipping distance k=16. 8 k40 GPUs are used.
- For the proposed big model, 6 encoder and decoder layers are used, dx=1024, dz=64, 16 attention heads, 4096 feed forward inner-layer dimensions, and Pdropout=0.3 for EN-DE and Pdropout=0.1 for EN-FR. k=8, and unique edge representations are used per layer. 8 P100 GPUs are used.
3.1. Comparison with Original Transformer

For English-to-German, the proposed approach improved performance over the baseline Transformers by 0.3 and 1.3 BLEU for the base and big configurations, respectively.
For English-to-French, it improved the baseline Transformers by 0.5 and 0.3 BLEU for the base and big configurations, respectively.
- And there is no benefit from including sinusoidal position encodings in addition to relative position representations.
3.2. Model Variants
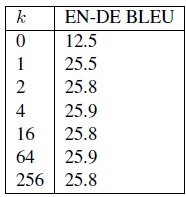
For k≥2, there does not appear to be much variation in BLEU scores.
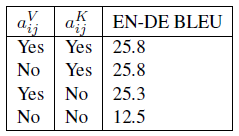
Including relative position representations solely when determining compatibility between elements may be sufficient, but authors said further work is needed to determine whether this is true for other tasks.
T5 also uses the relative position embedding.
The below YouTube link explains the proposed method in a very good way and with many good images. Please feel free to watch if interested.
References
[2018 NAACL] [Shaw NAACL’18]
Self-Attention with Relative Position Representations
[Good Presentation in YouTube]
Machine Translation
2014 [Seq2Seq] [RNN Encoder-Decoder] 2015 [Attention Decoder/RNNSearch] 2016 [GNMT] [ByteNet] [Deep-ED & Deep-Att] 2017 [ConvS2S] [Transformer] [MoE] [GMNMT] [CoVe] 2018 [Shaw NAACL’18] 2019 [AdaNorm] [GPT-2] 2020 [Batch Augment, BA] [GPT-3] [T5] 2021 [ResMLP]