Review — Transformer-XL: Attentive Language Models Beyond a Fixed-Length Context
Transformer-XL: Transformer With The Use Of Memory

Transformer-XL: Attentive Language Models Beyond a Fixed-Length Context
Transformer-XL, by Carnegie Mellon University, Google Brain
2019 ACL, Over 1600 Citations (Sik-Ho Tsang @ Medium)
- Transformer-XL that enables learning dependency beyond a fixed length without disrupting temporal coherence.
- A novel positional encoding scheme is proposed.
Outline
- Vanilla Character Transformer Model T64
- Proposed Transformer-XL
- Experimental Results
1. Vanilla Character Transformer Model T64

- A simple solution would be to process the entire context sequence is usually infeasible with the limited resource in practice.
- In T64, a crude approximation is proposed to split the entire corpus into shorter segments of manageable sizes, and only train the model within each segment, ignoring all contextual information from previous segments.
- The above figure shows T64, a vanilla model, with a segment length 4.
- (Please feel free to read T64 if interested.)
2. Proposed Transformer-XL

2.1. Segment-Level Recurrence with State Reuse
- As shown above, during training, the hidden state sequence computed for the previous segment is fixed and cached to be reused as an extended context (green lines) when the model processes the next new segment.
- Formally, let the two consecutive segments sτ and sτ+1 of length L be:

- Denoting the n-th layer hidden state sequence produced for the τ-th segment sτ by hnτ. Then, the n-th layer hidden state for segment sτ+1 is produced (schematically) as follows:

- where the function SG(.) stands for stop-gradient, [] is concatenation of 2 hidden sequences at the (n-1)-th hidden layers.
- q, k, v are the query, key, and value respectively.
- Transformer-Layer is one layer of Transformer to get the n-th hidden layer.
- Thus, a predefined length-M old hidden states can be cached which spans (possibly) multiple segments, and is referred as the memorymn.
- In the experiment, M is set as the segment length during training, and it is increased by multiple times during evaluation.
2.2. Relative Positional Encodings
- Positional encoding is used in Transformer. But when hidden states are reused, there is positional encoding problem.
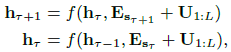
- where Esτ is the word embedding sequence of sτ, and f represents a transformation function.
- Notice that, both Esτ and Esτ+1 are associated with the same positional encoding U1:L. As a result, the model has no information to distinguish the positional difference.
Practically, one can create a set of relative positional encodings to solve it.
- In the standard Transformer, the attention score between query qi and key vector kj within the same segment can be decomposed as:

- Following the idea of only relying on relative positional information, the above equation is modified and is re-parameterized as the four terms:
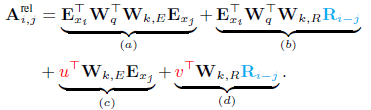
- The first change is to replace all appearances of the absolute positional embedding Uj for computing key vectors in term (b) and (d) with its relative counterpart Ri-j.
- Secondly, a trainable parameter u is introduced to replace the query in term (c). Similar in term (d), a trainable parameter v is introduced. In this case, since the query vector is the same for all query positions, it suggests that the attentive bias towards different words should remain the same regardless of the query position.
- Finally, the two weight matrices Wk,E and Wk,R are deliberately separated for producing the content-based key vectors and location-based key vectors respectively.
Under this new parameterization, each term has an intuitive meaning: term (a) represents content-based addressing, term (b) captures a content-dependent positional bias, term (c) governs a global content bias, and term (d) encodes a global positional bias.
- The relative positional embedding R adapts the sinusoid formulation.
- The computational procedure for a N-layer Transformer-XL with a single attention head is:
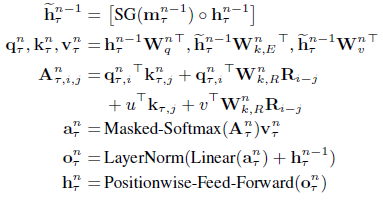
3. Experimental Results
3.1. SOTA Comparison on WikiText-103

- Attention length is set to 384 during training and 1600 during evaluation.
Transformer-XL reduces the previous state-of-the-art (SoTA) perplexity from 20.5 to 18.3, which demonstrates the superiority of the Transformer-XL architecture.
3.2. SOTA Comparison on enwik8
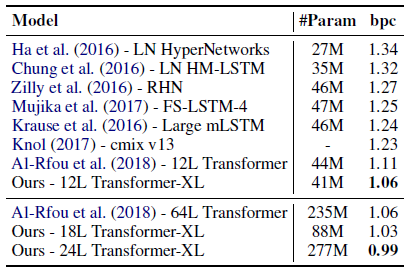
12-layer architecture achieves the same result as T64, the 64-layer network from Al-Rfou et al. (2018), using only 17% of the parameter budget.
Under the model size constraint, the 12-layer Transformer-XL achieves a new SoTA result, outperforming the 12-layer vanilla Transformer from Al-Rfou et al. (2018) (T64) by 0.05.
- By increasing model sizes, 18-layer and 24-layer Transformer-XLs are trained with attention length is set to 784 during training and 3800 during evaluation.
A new SoTA result is obtained by 24-layer transformer-XL and it is the first to break through 1.0 on widely-studied character-level benchmarks.
- Different from T64, Transformer-XL does not need any auxiliary losses.
3.3. SOTA Comparison on text8
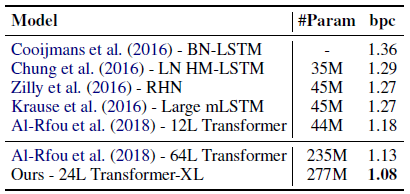
- Simply adapt the best model and the same hyper-parameters on enwik8 to text8 without further tuning.
Transformer-XL achieves the new SoTA result with a clear margin.
3.4. SOTA Comparison on One Billion Word
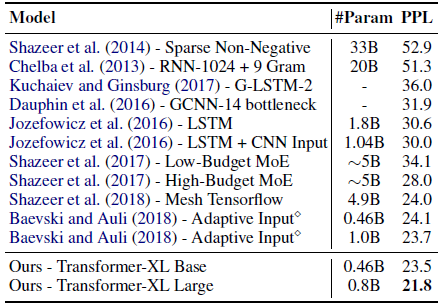
- Transformer-XL dramatically improves the single-model SoTA from 23.7 to 21.8.
Specifically, Transformer-XL significantly outperforms a contemporary method using vanilla Transformers.
3.5. SOTA Comparison on Penn Treebank
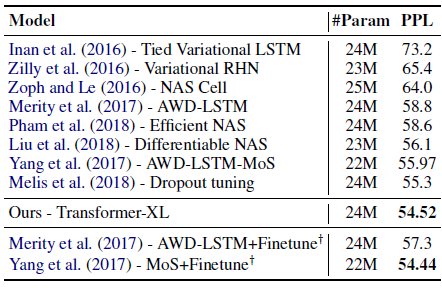
- Variational dropout and weight average are applied to Transformer-XL similar to AWD-LSTM.
Penn Treebank has only 1M training tokens, which implies that Transformer-XL also generalizes well even on small datasets.
- (There are ablation studies in the paper. Please feel free to read the paper.)
Reference
[2019 ACL] [Transformer-XL]
Transformer-XL: Attentive Language Models Beyond a Fixed-Length Context
Natural Language Processing (NLP)
Language/Sequence Model: 2007 [Bengio TNN’07] 2013 [Word2Vec] [NCE] [Negative Sampling] 2014 [GloVe] [GRU] [Doc2Vec] 2015 [Skip-Thought] 2016 [GCNN/GLU] [context2vec] [Jozefowicz arXiv’16] [LSTM-Char-CNN] 2017 [TagLM] [CoVe] [MoE] 2018 [GLUE] [T-DMCA] [GPT] [ELMo] 2019 [T64] [Transformer-XL] [BERT]
Machine Translation: 2014 [Seq2Seq] [RNN Encoder-Decoder] 2015 [Attention Decoder/RNNSearch] 2016 [GNMT] [ByteNet] [Deep-ED & Deep-Att] 2017 [ConvS2S] [Transformer] [MoE]
Image Captioning: 2015 [m-RNN] [R-CNN+BRNN] [Show and Tell/NIC] [Show, Attend and Tell]
