Brief Review — Fast Transformer Decoding: One Write-Head is All You Need
Multi-Query Attention Instead of Multi-Head Attention
Fast Transformer Decoding: One Write-Head is All You Need
Multi-Query Attention, by Google
2019 arXiv v1, Over 80 Citations (Sik-Ho Tsang @ Medium)Neural Machine Translation (NMT)
2013 … 2021 [ResMLP] [GPKD] [Roformer] [DeLighT] [R-Drop] 2022 [DeepNet] [PaLM] [BLOOM] [AlexaTM 20B]
==== My Other Paper Readings Are Also Over Here ====
- Multi-head attention layers, in Transformer, make inference often slow, due to the memory-bandwidth cost of repeatedly loading the large “keys” and “values” tensors.
- A variant called multi-query attention is proposed, where the keys and values are shared across all of the different attention “heads”, greatly reducing the size of these tensors and hence the memory bandwidth requirements of incremental decoding.
- Although this is a tech report with relatively low citations (still high) compared with other Transformer papers. It has been applied in some of the NLP models such as AlphaCode.
Outline
- Multi-Query Attention
- Results
1. Multi-Query Attention
1.1. Conventional Multi-head Attention

- The Transformer sequence-to-sequence model uses h different attention layers (heads) in parallel.
- The query vectors for the h different layers are derived from h different learned linear projections Pq of an input vector x.
- Similarly, the keys and values are derived from h different learned linear projections Pk, Pv of a collection M of m different input vectors.
- The outputs of the h layers are themselves passed through different learned linear projections Po, then summed.
1.2. Proposed Multi-Query Attention

- Multi-query attention is identical except that the different heads share a single set of keys and values.
- The letter “h” is removed from the tf.einsum equations as above.
2. Results
- A Transformer model with 6 layers, dmodel = 1024, dff = 8192, h = 8, dk = dv = 128, is used. The total parameter count is 192 million for the baseline and for all variations.

The multi-query attention model seems to be slightly worse than the baseline.

For the multi-query model, the encoder took 195ms and the decoder took 3.9ms per step, for amortized per-token costs of 1.5μs and 3.8μs respectively, which is faster than multi-head one.
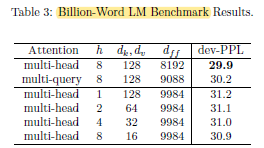
The multi-query attention model was slightly worse than the baseline, but significantly better than any of the alternatives involving decreasing h, dk and dv.
