Review — DeLighT: Deep and Light-weight Transformer
DeLighT, Parameter Reduction for Transformers
DeLighT: Deep and Light-weight Transformer,
DeLighT, by University of Washington, Facebook AI Research, and Allen Institute for AI,
2021 ICLR, Over 60 Citations (Sik-Ho Tsang @ Medium)
NLP, LM, NMT, Transformer
- Within each Transformer block, a deep and lightweight transformation is used using DeLighT block.
- Across blocks, block-wise scaling is used for shallower and narrower DeLighT blocks near the input, and wider and deeper DeLighT blocks near the output.
Outline
- DeLighT Block
- Block-wise Scaling
- Experimental Results
1. DeLighT Block

1.1. Conceptual Idea
DeLighT transformation maps a dm dimensional input vector into a high dimensional space (expansion) and then reduces it down to a do dimensional output vector (reduction) using N layers of the group transformations.
- Similar to DeFINE, DeLighT transformation uses group linear transformations (GLTs) because they learn local representations by deriving the output from a specific part of the input and are more efficient than linear transformations.
- To learn global representations, the DeLighT transformation shares information between different groups in the group linear transformation using feature shuffling.
1.2. DeLighT Transformation

Formally, the DeLighT transformation is controlled by five configuration parameters: (1) number of GLT layers N, (2) width multiplier wm, (3) input dimension dm, (4) output dimension do, and (5) maximum groups gmax in a GLT.
- In the expansion phase, the DeLighT transformation projects the dm-dimensional input to a high-dimensional space, dmax=wmdm, linearly using ⌈N/2⌉ layers.
- In the reduction phase, the DeLighT transformation projects the dmax-dimensional vector to a do-dimensional space using the remaining N- ⌈N/2⌉ GLT layers.
- Mathematically, the output Y at each GLT layer l as:

- The function F then linearly transforms each Xi with weights Wli and bias bli to produce output Yli.
- The outputs of each group Yli are then concatenated to produce the output Yl.
- The function H first shuffles the output of each group in Yl-1 and then combines it with the input X using the input mixer connection in DeFINE.
- The number of groups at the l-th GLT are computed as:

- In this paper, gmax=⌈dm/32⌉ so that each group has at least 32 input elements.
1.3. DeLighT Block
- DeLighT transformation is integrated into the Transformer block.
- DeLighT attention is:

- where do<dm, and dm is the standard Transformer module. In the experiment, do=dm/2, 2× fewer multiplication-addition operations are required as compared to the Transformer architecture.
- For the light-weight FFN, the first layer reduces the dimensionality of the input from dm to dm/r while the second layer expands the dimensionality from dm/r to dm, where r is the reduction factor.
- In the experiment, r=4. Thus, the light-weight FFN reduces the number of parameters in the FFN by 16.
The DeLighT block stacks (1) a DeLighT transformation with N GLTs, (2) three parallel linear layers for key, query, and value, (3) a projection layer, and (4) two linear layers. The depth of DeLighT block is N+4 where N is the depth of standard Transformer block.
2. Block-wise Scaling

- Simply scaling model width and depth allocates parameters uniformly across blocks, which may lead to learning redundant parameters.
Block-wise scaling is introduced that creates a network with variably-sized DeLighT blocks, allocating shallower and narrower DeLighT blocks near the input and deeper and wider DeLighT blocks near the output.
- For the b-th DeLighT block, the number of GLTs Nb and the width multiplier wbm are computed:
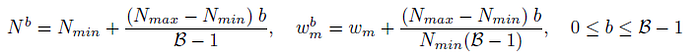
With this scaling, each DeLighT block has a different depth and width.
3. Experimental Results
3.1. Machine Translation
- wm=2, Nmin=4, and Nmax=8 for WMT’16 En-Ro, WMT’14 En-De, and WMT’14 En-Fr; resulting in 222 layer deep DeLighT networks.
- wm=1, Nmin=3, and Nmax=9 for IWSLT’14 De-En; resulting in 289 layer deep network.
- For simplicity, B=Nmax.
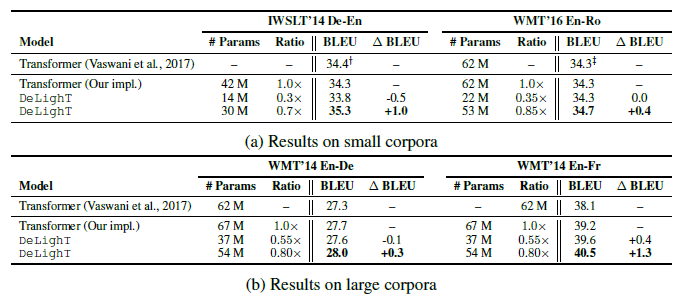
DeLighT delivers better performance with fewer parameters than Transformers, across different corpora.

For example, on WMT’14 En-Fr dataset, DeLighT is 3.7 deeper than Transformers and improves its BLEU score by 1.3 points yet with 13 million fewer parameters and 3 billion fewer operations.
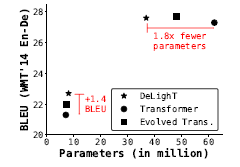
For small models (< 10M parameters), DeLighT models delivers better performance and for attaining the same performance as these models, DeLighT models requires fewer parameters.

DeLighT delivers similar or better performance than existing methods.
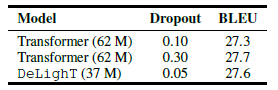
- DeLighT delivers similar performance to baseline Transformers, but with fewer parameters and less regularization.
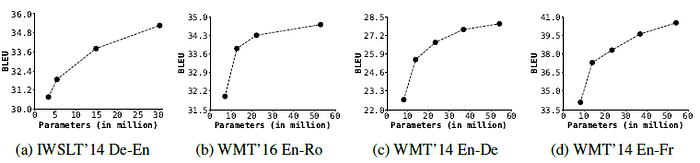
DeLighT models improves with increase in network parameters; suggesting their ability to learn representations across different corpora, including low-resource.
3.2. Language Modeling
- wm=2, Nmin=4, and Nmax=12, B=Nmax.

DeLighT delivers better performance than state-of-the-art methods (including Transformer-XL).
3.3. Computational Complexity

The Transformer and DeLighT models took about 37 and 23 hours for training and consumed about 12.5 GB and 14.5 GB of GPU memory, respectively (R1 vs. R2).
- Dedicated CUDA kernels for grouping and ungrouping functions in GLTs are implemented. With these changes, training time and GPU memory consumption of DeLighT reduced by about 4 hours and 3 GB, respectively.
Reference
[2021 ICLR] [DeLightT]
DeLighT: Deep and Light-weight Transformer
2.1. Language Model / Sequence Model
1991 … 2021 [Performer] [gMLP] [Roformer] [PPBERT] [DeBERTa] [DeLighT] 2022 [GPT-NeoX-20B] [InstructGPT]
2.2. Machine Translation
2013 … 2021 [ResMLP] [GPKD] [Roformer] [DeLighT]