Brief Review — RoFormer: Enhanced Transformer with Rotary Position Embedding
RoFormer: Rotary Position Embedding (RoPE), for Position Information
RoFormer: Enhanced Transformer with Rotary Position Embedding,
RoFormer, by Zhuiyi Technology Co., Ltd.
2021 arXiv v4, Over 70 Citations (Sik-Ho Tsang @ Medium)
Natural Language Processing, NLP, Language Model, LM, Transformer, BERT
- Rotary Position Embedding (RoPE) is proposed to effectively leverage the positional information.
- RoPE encodes the absolute position with a rotation matrix and meanwhile incorporates the explicit relative position dependency in self-attention formulation.
- RoPE has multiple advantages: The flexibility of sequence length, decaying inter-token dependency with increasing relative distances, and the capability of equipping the linear self-attention with relative position encoding.
Outline
- Preliminaries
- Roformer
- Results
1. Preliminaries
1.1. Self-Attention
- Let SN={wi}, where i from 1 to N, be a sequence of N input tokens with wi being the i-th element.
In Transformer, the self-attention first incorporates position information to the word embeddings and transforms them into queries, keys, and value representations:

where qm, kn and vn incorporate the m-th and n-th positions through fq, fk and fv, respectively.
- The query and key values are then used to compute the attention weights, while the output is computed as the weighted sum over the value representation:

1.2. Absolute Position Embedding in Original Transformer
- For the original Transformer, in fq, fk and fv, pi is a d-dimensional vector depending of the position of token xi:


- where L is the maximum sequence length.
pi is generated using the sinusoidal function:

1.3. Relative Position Embedding in Shaw NAACL’18
Trainable relative position embeddings ~pkr, ~pvr are used in Shaw NAACL’18:


where r represents the relative distance between position m and n. They clipped the relative distance with the hypothesis that precise relative position information is not useful beyond a certain distance.
2. Roformer
Specifically, incorporating the relative position embedding in Roformer is to: Simply rotate the affine-transformed word embedding vector by amount of angle multiples of its position index and thus interprets the intuition behind Rotary Position Embedding.
2.1. Goal
- In order to incorporate relative position information, we require the inner product of query qm and key kn in Equation (2) to be formulated by a function g, which takes only the word embeddings xm, xn, and their relative position m-n as input variables:
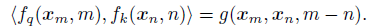
The ultimate goal is to find an equivalent encoding mechanism to solve the functions fq(xm, m) and fk(xn, n) to conform the aforementioned relation.
2.2. 2D Form (for Simplicity)
- Consider a simpler case of 2D form, the above equation becomes:
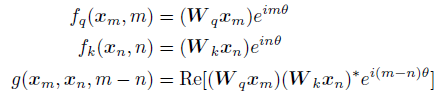
- where Re[] is the real part of a complex number and (Wkxn)* represents the conjugate complex number of (Wkxn).
- {fq, kg} is further written in a multiplication matrix:
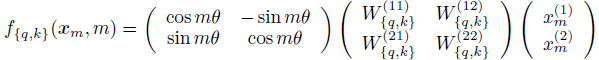
- where (x(1)m, x(2)m) is xm expressed in the 2D coordinates.
2.3. General Form
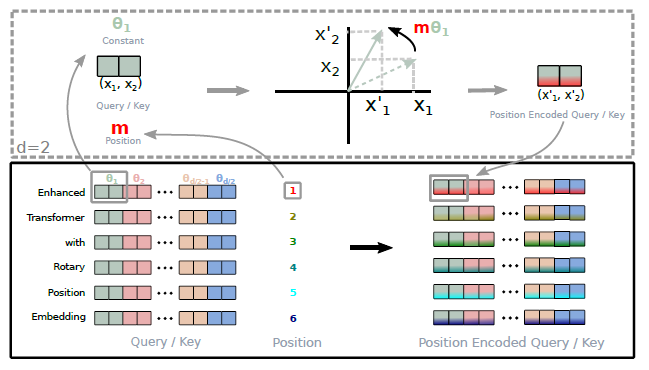
- In general form:
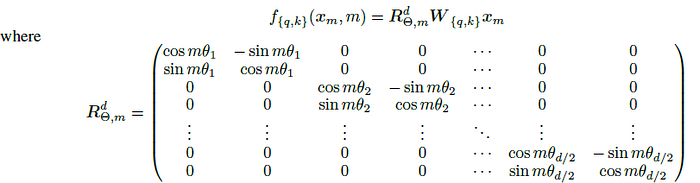
- Θ is the rotary matrix with pre-defined parameters:
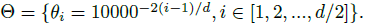
- When applying RoPE to self-attention, qTmkn becomes:

- With:
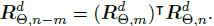
3. Results
3.1. Machine Translation

The proposed RoFormer gives better BLEU scores compared to its baseline alternative Vaswani et al. on the WMT 2014 English-to-German translation task.
3.2. Language Model Pretraining
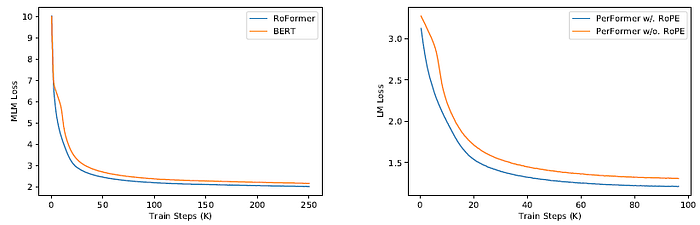
Compare to the vanilla BERT, RoFormer experiences faster convergence.
3.3. GLUE

RoFormer can significantly outperform BERT in three out of six datasets, and the improvements are considerable.
To encode position, conventional Transformer uses absolute position, Shaw NAACL’18 uses the distance between two positions, and the proposed RoFormer uses rotation.
Reference
[2021 arXiv v4] [RoFormer]
RoFormer: Enhanced Transformer with Rotary Position Embedding
2.1. Language Model / Sequence Model
(Some are not related to NLP, but I just group them here)
1991 … 2020 [ALBERT] [GPT-3] [T5] [Pre-LN Transformer] [MobileBERT] [TinyBERT] [BART] [Longformer] [ELECTRA] [Megatron-LM] [SpanBERT] [UniLMv2] 2021 [Performer] [gMLP] [RoFormer]
2.2. Machine Translation
2013 … 2021 [ResMLP] [GPKD] [RoFormer]
