Review — R-Drop: Regularized Dropout for Neural Networks
KL-Divergence Minimization With the Use of Dropout
R-Drop: Regularized Dropout for Neural Networks,
R-Drops, by Soochow University, and Microsoft Research Asia,
2021 NeurIPS, Over 140 Citations (Sik-Ho Tsang @ Medium)
NLP, LM, NMT, Image Classification Transformer, Vision Transformer, ViT, DropoutImage Classification: 1989 … 2023 [Vision Permutator (ViP)]
Language Model: 1991 … 2022 [GPT-NeoX-20B] [InstructGPT]
Machine Translation: 2013 … 2022 [DeepNet]
==== My Other Paper Readings Are Also Over Here ====
- A simple consistency training strategy to regularize Dropout, R-Drop, is proposed, which forces the output distributions of different sub models generated by Dropout to be consistent with each other.
- R-Drop minimizes the bidirectional KL-divergence between the output distributions of two sub models sampled by Dropout.
- R-Drop can be applied to language modeling, neural machine translation and image classification.
Outline
- Motivations
- R-Drop
- Results
1. Motivations
- Given the training data D={(xi, yi)} where i is from 1 to n, the main learning objective for a deep learning model is to minimize the negative log-likelihood loss function, which is as follow:

However, deep neural networks are prone to over-fitting. Because there is a huge inconsistency between training and inference that hinders the model performance.
2. R-Drop
2.1. Loss Functions

- Given the input data xi at each training step, xi is fed to go through the forward pass of the network twice. Therefore, we can obtain two distributions of the model predictions, denoted as Pw1(yi|xi) and Pw2(yi|xi).
- Since Dropout is used, the two forward passes are indeed based on two different sub models. As the dropped units are different, two distributions Pw1(yi|xi) and Pw2(yi|xi) are also different.
R-Drop method tries to regularize on the model predictions by minimizing the bidirectional Kullback-Leibler (KL) divergence between these two output distributions for the same sample, which is:

- With the basic negative log-likelihood learning objective LiNLL of the two forward passes:

- The final training objective is to minimize Li for data (xi, yi):

- where α is the coefficient weight.
2.2. Training Algorithm

- Lines 3–4: The input data x is repeated itself and concatenated ([x; x]) in batch-size dimension, and perform forward pass to save the training cost.
- Lines 5–6: calculate the negative log-likelihood and the KL-divergence.
- Line 7: Finally, the model parameters are updated.
2.3. Theoretical Analysis
- (Please skip this part for quick read.)
- Let hl(x) denote the output of the l-th layer of input x.
- ξli is the random vector of each dimension of which is independently sampled from a Bernoulli distribution B(p):
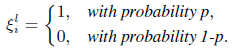
- Dropout can be interpreted as:
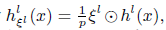
- where ⊙ denotes the element-wised product.
- The objective for R-Drop enhanced training can be formulated as solving the following constrained optimization problem:

- Therefore, R-Drop optimizes the constrained optimization problem in a stochastic manner, i.e., it samples two random vectors ξ(1) and ξ(2) (corresponding to two Dropout instantiations) from Bernoulli distribution and one training instance (xi, yi).
R-Drop enhanced training reduces this inconsistency by forcing the sub structures to be similar.
3. Results
3.1. Neural Machine Translation

- Transformer is used. R-Drop is denoted as RD. α=5.
R-Drop achieves more than 2.0 BLEU score improvements on 8 IWSLT translation tasks.
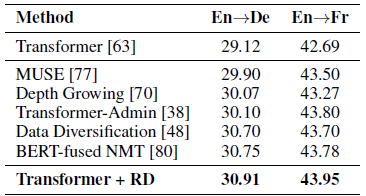
After applying RD on the basic Transformer network, the state-of-the-art (SOTA) BLEU score is achieved on WMT14 En→De (30.91) and En→Fr (43.95) translation tasks, which surpass current SOTA models, such as the BERT-fused NMT [80].
3.2. Language Understanding
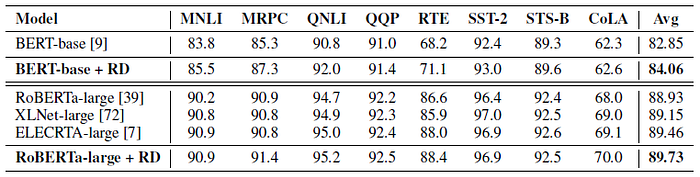
- The BERT-base and strong RoBERTa-large pre-trained models are used as backbone. α is dynamically adjusted as {0.1; 0.5; 1.0} for each setting.
- For the regression task STS-B, MSE is used instead of KL-divergence to regularize the outputs.
R-Drop achieves 1.21 points and 0.80 points (on average) improvement over the two baselines BERT-base and RoBERTa-large, respectively, which clearly demonstrate the effectiveness of R-Drop.
- Specifically, RoBERTa-large + RD also surpasses the other two strong models: XLNet-large and ELECTRA-large, which are specially designed with different model architecture and pre-training task.
3.3. Summarization
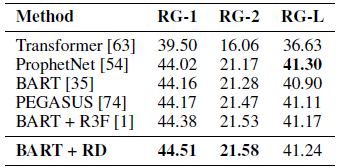
- Pretrained BART is used. α=0.7.
R-Drop based training outperforms the fine-tuned BART model by 0.3 points on RG-1 and RG-2 score and achieves the SOTA performance. Specifically, it also surpasses the PEGASUS method [74].
3.4. Language Modeling
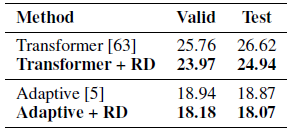
- Two models: One is the basic Transformer decoder, another is the more advanced one: Adaptive Input Transformer [5]. α=1.0.
R-Drop based training improves the perplexity on both two different model structures, e.g., 0.80 perplexity improvement on test set over Adaptive Input Transformer [5].
3.5. Image Classification
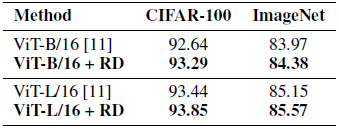
- Pre-trained models, ViT-B/16 and ViT-L/16, with 86M and 307M parameters respectively, are used. α=0.6.
For CIFAR-100, RD achieves about 0.65 accuracy improvement over ViT-B/16 baseline, and 0.41 points over ViT-L/16 model. Similarly, on the large-scale ImageNet dataset, consistent improvements are also obtained.
3.6. Ablation Study

Left: Transformer quickly becomes over-fitting, and the gap between train and valid loss of Transformer is large, while R-Drop has a lower valid loss.
Right: R-Drop can be performed every k steps instead of each step (k=1). k=1 is the best.
Also, R-Drop can have more than m=2 distributions. But m=2 is found out to be good enough.
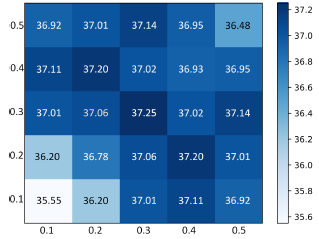
Dropout rates with the same value (0.3, 0.3) is the best choice (current setting). R-Drop can stably achieve strong results when the two Dropout rates are in a reasonable range (0.3-0.5) without a big performance difference.
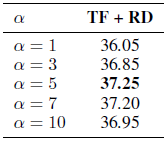
The best balanced choice is α=5.
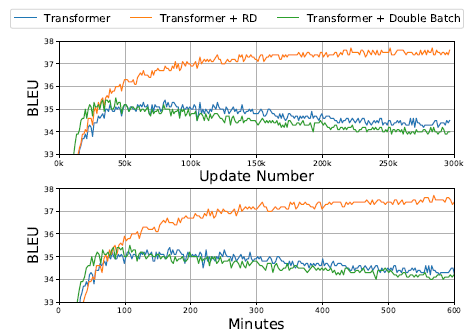
Since R-Drop doubles the batch size, doubling batch size without using R-drop (Green) is also tested and the results are not good. Thus, R-Drop is effective.
Authors mentioned that, due to the limitation of computational resources, for pre-training related tasks, authors only tested R-Drop on downstream task fine-tuning in this work. One of the future works is to test it on pre-training.
Authors also said that they only focused on Transformer based models. Another future work is to apply R-Drop to other network architectures such as convolutional neural networks.
