Brief Review — LiT: Zero-Shot Transfer with Locked-image text Tuning
LiT : Zero-Shot Transfer with Locked-image text Tuning,
LiT, by Google Research, Brain Team
2022 CVPR, Over 90 Citations (Sik-Ho Tsang @ Medium)
Vision Language Model, Visual Language, VLM3.1. Visual/Vision/Video Language Model (VLM)
2017 … 2021 [CLIP] [VinVL] [ALIGN] [VirTex] [ALBEF] [Conceptual 12M (CC12M) 2022 [FILIP] [Wukong]
My Other Previous Paper Readings Are Also Over Here
- “Locked-image Tuning” (LiT) is proposed, which just teaches a text model to read out good representations from a pre-trained image model for new tasks, i.e. locked pre-trained image models with unlocked text models.
Outline
- Locked-image Tuning (LiT)
- Results
1. Locked-image Tuning (LiT)

- For VLM, one way is to train image encoder (tower) and text encoder (tower) using contrastive loss so that their representations are the same when they are mentioning the same thing in both image and text.
- Two letters are introduced to represent the image tower and text tower setups.
- L stands for locked variables and initialized from a pre-trained model.
- U stands for unlocked and initialized from a pre-trained model.
- u stands for unlocked and randomly initialized.
Lu is named as “Locked-image Tuning” (LiT).
- Image-text models may have different representation sizes, a simple head is added onto each tower.
- Besides CC12M and YFCC100m, authors also collected a 4-billion image-text-pair dataset on their own.
2. Results
2.1. Comparison to the Previous SOTA

The proposed model significantly outperforms the previous state-of-the-art methods at ImageNet zero-shot classification. There are 8.3% and 8.1% improvement over CLIP and ALIGN, respectively.
- LiT models achieve promising zero-shot results, comparing to the supervised fine-tuned ResNet50 baseline.

- LiT achieves 78.7% top-1 accuracy on 0-shot ImageNet transfer, with only 300M image-text pairs seen.
- In comparison, it took the from-scratch method (i.e. CLIP) 12.8B image-text pairs seen, i.e. 40 times more data pairs, to reach 76.2% top-1 accuracy.
With a pre-trained image model, the proposed setup converges significantly faster than the standard from-scratch setups reported in the literature. LiT provides a way to reuse the already pre-trained models in the literature.
2.2. Evaluation of Design Choices
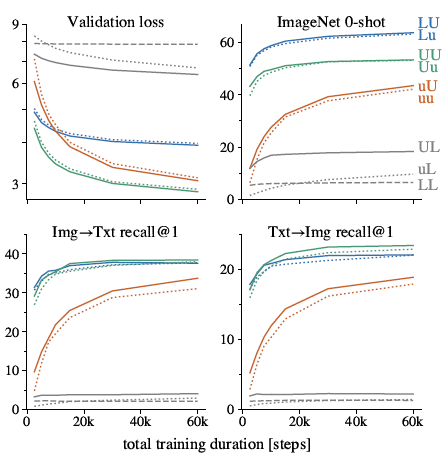
- Each point on the curves is a separate full run for that duration.
It is evident that locking the image tower almost always works best and using a pre-trained image tower significantly helps across the board, whereas using a pre-trained text tower only marginally improves performance, and locking the text tower does not work well.
- (There are also other design choices, please feel free to read the paper directly if you’re interested.)
2.3. Preliminary Multilingual Experiments
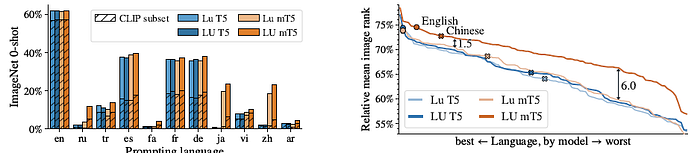
- On cross-modal retrieval tasks, there is no clear benefit of the Lu setup compared to Uu or UU. For very long tuning schedules, Uu or UU sometimes overtake Lu on these tasks.
The results suggest that the proposed Lu setup can still save computational cost within a fixed budget, but with a large enough budget, it may be useful to also consider the Uu setup.
