Review — CLIP: Learning Transferable Visual Models From Natural Language Supervision
Contrastive Language-Image Pre-Training (CLIP), Learn Image Representation From Image Captioning Dataset
Learning Transferable Visual Models From Natural Language Supervision,
CLIP, by OpenAI,
2021 ICML, Over 2700 Citations (Sik-Ho Tsang @ Medium)
Image Classification, Image Captioning, Vision Language Model, Vision Transformer, ViT
- Conventionally, a fixed set of predetermined object categories is used for training and prediction, e.g.: ImageNet.
- Contrastive Language-Image Pre-Training (CLIP) is proposed to have the pre-training task of predicting which caption to learn image representations from scratch on a dataset of 400 million (image, text) pairs.
- After pre-training, natural language is used to reference learned visual concepts (or describe new ones) enabling zero-shot transfer of the model to downstream tasks.
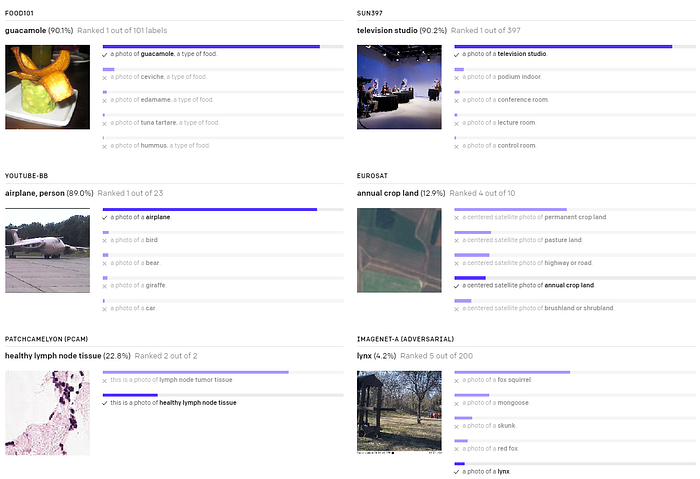
- (For fast read, please read 1, 2, 3.1, and 4.)
Outline
- Motivations & WebImageText (WIT) Dataset
- Contrastive Language-Image Pre-Training (CLIP)
- Zero-Shot Transfer Results
- Linear Probe Results
- Task & Distribution Shift Robustness
1. Motivations & WebImageText (WIT) Dataset
1.1. Motivation
- Learning from natural language is much easier to scale compared to standard crowd-sourced labeling for image classification since it does not require annotations.
- It also has an important advantage over most unsupervised or self-supervised learning approaches in that it doesn’t “just” learn a representation but also connects that representation to language which enables flexible zero-shot transfer.
1.2. Creating a Sufficiently Large Dataset: WebImageText (WIT)
- A major motivation for natural language supervision is the large quantities of data of this form available publicly on the internet.
- The base query list is all words occurring at least 100 times in the English version of Wikipedia. This is augmented with bi-grams.
- Then (image, text) pairs are searched as part of the construction process whose text includes one of a set of 500,000 queries. Class balance is approximated by including up to 20,000 (image, text) pairs per query.
- The resulting dataset has a similar total word count as the WebText dataset used to train GPT-2. This dataset is referred as WIT for WebImageText. Due to the large size of the pre-training dataset, over-fitting is not a major concern.
2. Contrastive Language-Image Pre-Training (CLIP)
2.1. Pretraining Framework

Given a batch of N (image, text) pairs, CLIP is trained to predict which of the N×N possible (image, text) pairings across a batch actually occurred.

CLIP learns a multi-modal embedding space by jointly training an image encoder and text encoder to maximize the cosine similarity of the image and text embeddings of the N real pairs in the batch while minimizing the cosine similarity of the embeddings of the N²-N incorrect pairings.
- CLIP is trained from scratched, and does not use any non-linear projection layers, instead only a linear projection is used to map from each encoder’s representation to the multi-modal embedding space.
- The text transformation function tu, as in ConVIRT, is removed.
- A random square crop from resized images is the only image data augmentation tv.
- Finally, the temperature parameter τ=0.07, as in Knowledge Distillation, which controls the range of the logits in the softmax.
2.2. Models
- For image encoder, ResNet-50 is used as base model, with some modifications. Specifically, ResNet-D is used. (The anti-aliased rect-2 blur pooling is used. Attention pooling is used to replace global average pooling, which is a single layer of “Transformer-style” multi-head QKV attention.)
- Another image encoder considered is Vision Transformer, ViT. (With modification of adding an additional layer normalization to the combined patch and position embeddings before the Transformer and slightly different initialization scheme is used.)
- The text encoder is a Transformer. As a base size, a 63M-parameter 12- layer 512-wide model with 8 attention heads, is used.
- Only the width of the Transformer is scaled to be proportional to the calculated increase in width of the ResNet and the Transformer depth is not scaled at all.
- In practical, a series of 5 ResNets and 3 ViTs is used.
- For the ResNets, a ResNet-50, a ResNet-101, and then 3 more which follow EfficientNet-style model scaling and use approximately 4×, 16×, and 64× the compute of a ResNet-50. They are denoted as RN50×4, RN50×16, and RN50×64 respectively.
- For the ViTs, a ViT-B/32, a ViT-B/16, and a ViT-L/14.
2.3. Training
- All models are trained for 32 epochs. A very large minibatch size of 32,768 is used. Mixed-Precision Training. The calculation of embedding similarities was also sharded with individual GPUs.
- The largest ResNet model, RN50×64, took 18 days to train on 592 V100 GPUs while the largest ViT took 12 days on 256 V100 GPUs.
- For the ViT-L/14, it is also pre-trained at a higher 336 pixel resolution for one additional epoch to boost performance similar to FixRes, denoted as ViT-L/14@336px.
3. Zero-Shot Transfer Results
3.1. Comparison with Visual N-Grams

- Visual N-Grams is a primitive conceptual approach leveraging text for visual tasks.
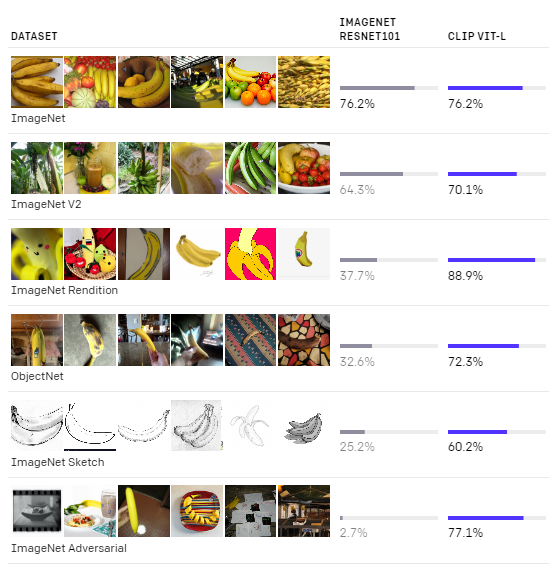
The best CLIP model improves accuracy on ImageNet from a proof of concept 11.5% to 76.2% and matches the performance of the original ResNet-50. This shows that CLIP is a significant step towards flexible and practical zero-shot computer vision classifiers.
3.2. Prompt Engineering and Ensembling
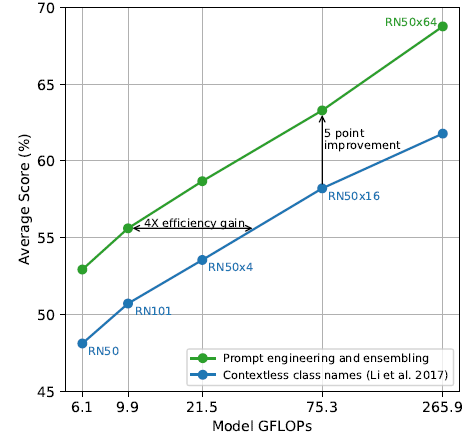
- Using the prompt template, e.g.: “A photo of a <label>.” to be a good default that helps specify the text is about the content of the image.
- Ensembling over multiple zero-shot classifiers as another way of improving performance.
On ImageNet, 80 different context prompts are ensembled and this improves performance by an additional 3.5% over the single default prompt discussed above.
When considered together, prompt engineering and ensembling improve ImageNet accuracy by almost 5%.
3.3. Comparison with Few-Shot Linear Probes
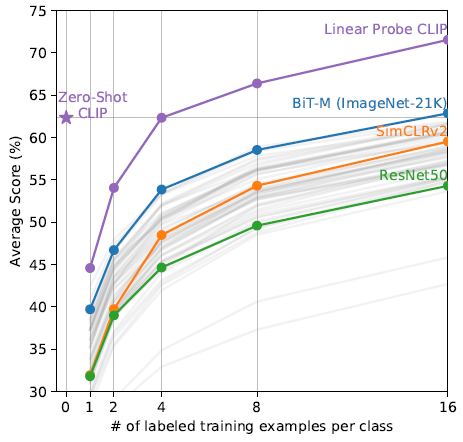
- Zero-shot CLIP roughly matches the performance of the best performing 16-shot classifier in the evaluation suite, which uses the features of a BiT-M ResNet-152×2 trained on ImageNet-21K.
3.4. Room for Improvement
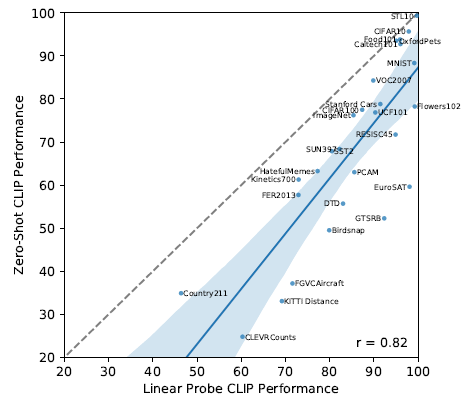
- The dashed, y=x line represents an “optimal” zero-shot classifier that matches the performance of its fully supervised equivalent.
- Zero-shot CLIP only approaches fully supervised performance on 5 datasets: STL10, CIFAR10, Food101, OxfordPets, and Caltech101. On all 5 datasets, both zero-shot accuracy and fully supervised accuracy are over 90%.
For most datasets, the performance of zero-shot classifiers still underperform fully supervised classifiers by 10% to 25%, suggesting that there is still plenty of headroom for improving.
4. Linear Probe Results

- Models trained with CLIP scale very well and the largest model trained (ResNet-50×64) slightly outperforms the best performing existing model (a Noisy Student EfficientNet-L2) on both overall score and compute efficiency.
- It is also found that CLIP ViTs are about 3× more compute efficient than CLIP ResNets.
The best overall model is a ViT-L/14 that is fine-tuned at a higher resolution of 336 pixels on the dataset for 1 additional epoch. This model outperforms the best existing model across this evaluation suite by an average of 2.6%.
5. Task & Distribution Shift Robustness
5.1. Task Shift Robustness

The representations of models trained on ImageNet are somewhat overfit to their task.
5.2. Distribution Shift Robustness
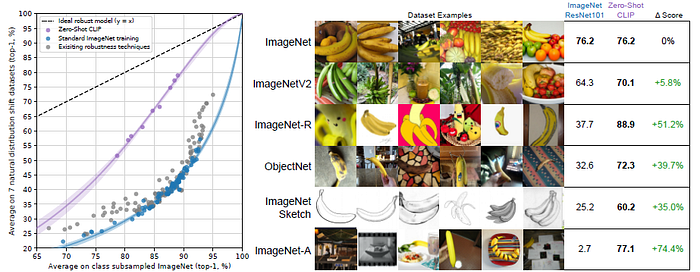
All zero-shot CLIP models improve effective robustness by a large amount and reduce the size of the gap between ImageNet accuracy and accuracy under distribution shift by up to 75%.
The paper got 48 pages in total! I’ve only presented very few things here. There are also other contents such as zero/one-shot comparison with human, bias issue, limitations, impacts, and possible future works. Please feel free to read the paper directly if interested.
References
[2021 ICML] [CLIP]
Learning Transferable Visual Models From Natural Language Supervision
[OpenAI Blog] [CLIP]
https://openai.com/blog/clip/
3.1. Visual/Vision/Video Language Model (VLM)
2018 [Conceptual Captions] 2019 [VideoBERT] [VisualBERT] [LXMERT] [ViLBERT] 2020 [ConVIRT] [VL-BERT] [OSCAR] 2021 [CLIP]
